 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDEAR: Disentangled Environment and Agent Representations for Reinforcement Learning without Reconstruction
Jun 30, 2024Reinforcement Learning (RL) algorithms can learn robotic control tasks from visual observations, but they often require a large amount of data, especially when the visual scene is complex and unstructured. In this paper, we explore how the agent's knowledge of its shape can improve the sample efficiency of visual RL methods. We propose a novel method, Disentangled Environment and Agent Representations (DEAR), that uses the segmentation mask of the agent as supervision to learn disentangled representations of the environment and the agent through feature separation constraints. Unlike previous approaches, DEAR does not require reconstruction of visual observations. These representations are then used as an auxiliary loss to the RL objective, encouraging the agent to focus on the relevant features of the environment. We evaluate DEAR on two challenging benchmarks: Distracting DeepMind control suite and Franka Kitchen manipulation tasks. Our findings demonstrate that DEAR surpasses state-of-the-art methods in sample efficiency, achieving comparable or superior performance with reduced parameters. Our results indicate that integrating agent knowledge into visual RL methods has the potential to enhance their learning efficiency and robustness.
Autonomous Navigation for Robot-assisted Intraluminal and Endovascular Procedures: A Systematic Review
May 06, 2023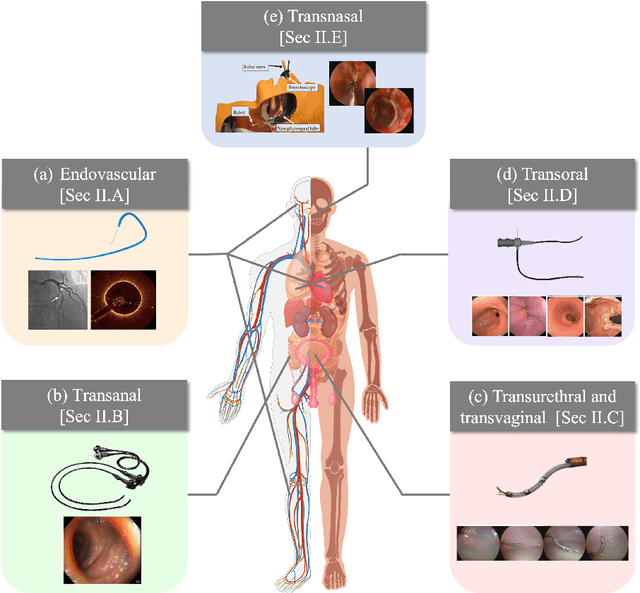
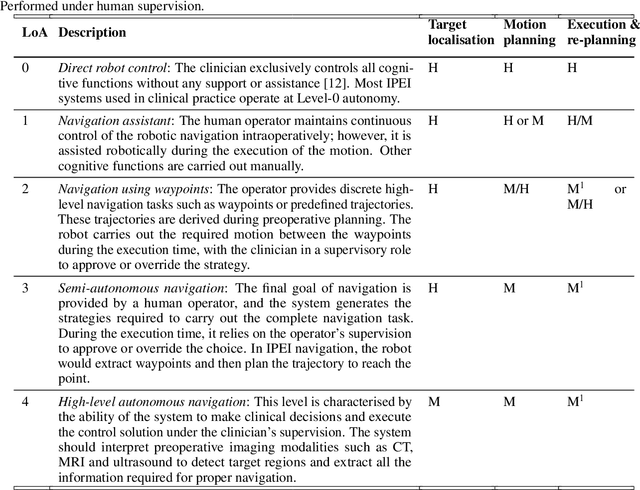
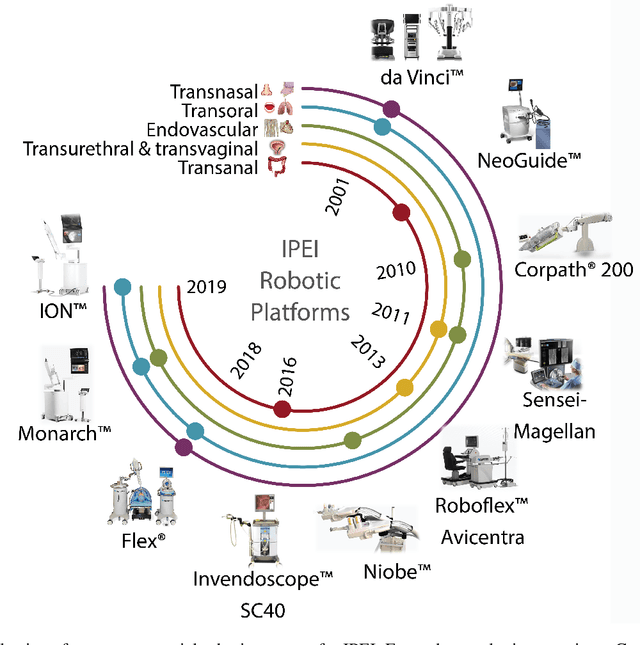

Increased demand for less invasive procedures has accelerated the adoption of Intraluminal Procedures (IP) and Endovascular Interventions (EI) performed through body lumens and vessels. As navigation through lumens and vessels is quite complex, interest grows to establish autonomous navigation techniques for IP and EI for reaching the target area. Current research efforts are directed toward increasing the Level of Autonomy (LoA) during the navigation phase. One key ingredient for autonomous navigation is Motion Planning (MP) techniques. This paper provides an overview of MP techniques categorizing them based on LoA. Our analysis investigates advances for the different clinical scenarios. Through a systematic literature analysis using the PRISMA method, the study summarizes relevant works and investigates the clinical aim, LoA, adopted MP techniques, and validation types. We identify the limitations of the corresponding MP methods and provide directions to improve the robustness of the algorithms in dynamic intraluminal environments. MP for IP and EI can be classified into four subgroups: node, sampling, optimization, and learning-based techniques, with a notable rise in learning-based approaches in recent years. One of the review's contributions is the identification of the limiting factors in IP and EI robotic systems hindering higher levels of autonomous navigation. In the future, navigation is bound to become more autonomous, placing the clinician in a supervisory position to improve control precision and reduce workload.
Constrained Reinforcement Learning and Formal Verification for Safe Colonoscopy Navigation
Mar 16, 2023



The field of robotic Flexible Endoscopes (FEs) has progressed significantly, offering a promising solution to reduce patient discomfort. However, the limited autonomy of most robotic FEs results in non-intuitive and challenging manoeuvres, constraining their application in clinical settings. While previous studies have employed lumen tracking for autonomous navigation, they fail to adapt to the presence of obstructions and sharp turns when the endoscope faces the colon wall. In this work, we propose a Deep Reinforcement Learning (DRL)-based navigation strategy that eliminates the need for lumen tracking. However, the use of DRL methods poses safety risks as they do not account for potential hazards associated with the actions taken. To ensure safety, we exploit a Constrained Reinforcement Learning (CRL) method to restrict the policy in a predefined safety regime. Moreover, we present a model selection strategy that utilises Formal Verification (FV) to choose a policy that is entirely safe before deployment. We validate our approach in a virtual colonoscopy environment and report that out of the 300 trained policies, we could identify three policies that are entirely safe. Our work demonstrates that CRL, combined with model selection through FV, can improve the robustness and safety of robotic behaviour in surgical applications.
Colonoscopy Navigation using End-to-End Deep Visuomotor Control: A User Study
Jun 30, 2022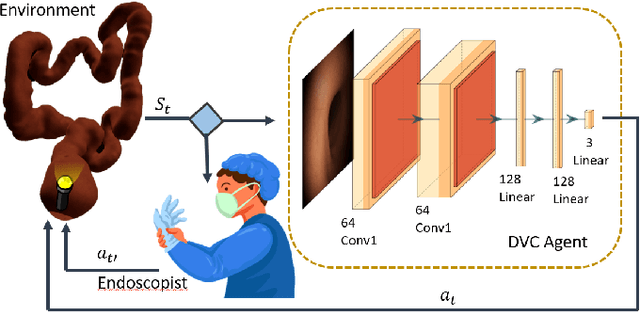
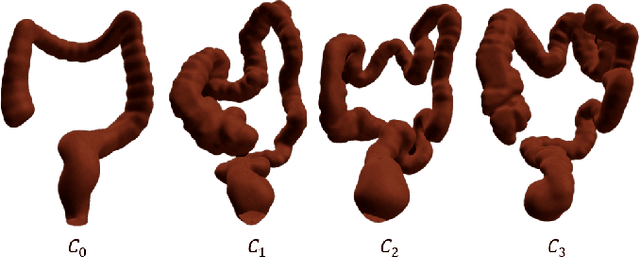
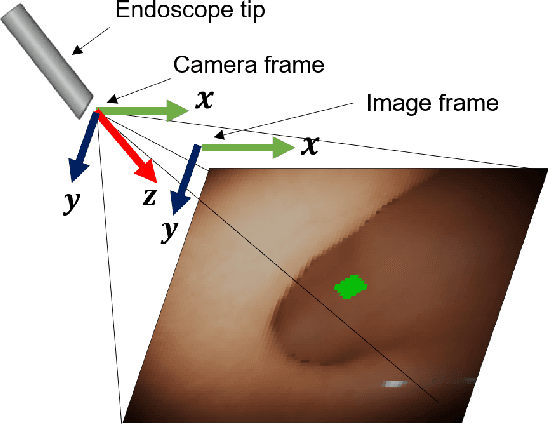
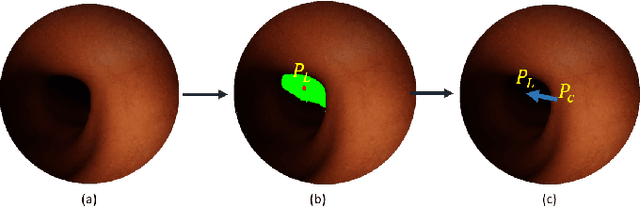
Flexible endoscopes for colonoscopy present several limitations due to their inherent complexity, resulting in patient discomfort and lack of intuitiveness for clinicians. Robotic devices together with autonomous control represent a viable solution to reduce the workload of endoscopists and the training time while improving the overall procedure outcome. Prior works on autonomous endoscope control use heuristic policies that limit their generalisation to the unstructured and highly deformable colon environment and require frequent human intervention. This work proposes an image-based control of the endoscope using Deep Reinforcement Learning, called Deep Visuomotor Control (DVC), to exhibit adaptive behaviour in convoluted sections of the colon tract. DVC learns a mapping between the endoscopic images and the control signal of the endoscope. A first user study of 20 expert gastrointestinal endoscopists was carried out to compare their navigation performance with DVC policies using a realistic virtual simulator. The results indicate that DVC shows equivalent performance on several assessment parameters, being more safer. Moreover, a second user study with 20 novice participants was performed to demonstrate easier human supervision compared to a state-of-the-art heuristic control policy. Seamless supervision of colonoscopy procedures would enable interventionists to focus on the medical decision rather than on the control problem of the endoscope.
Learning from Demonstrations for Autonomous Soft-tissue Retraction
Oct 01, 2021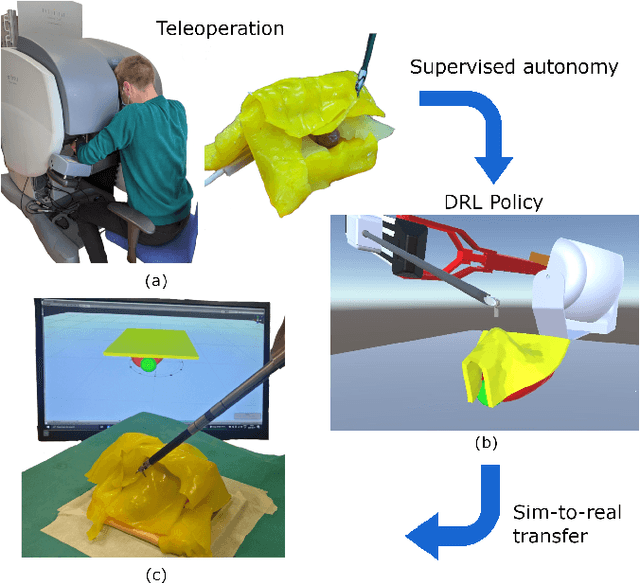
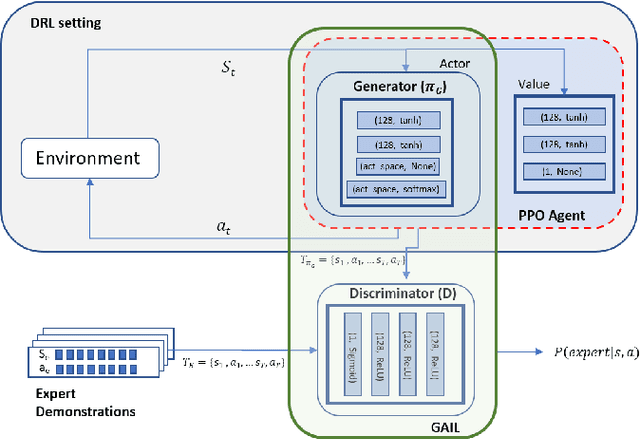
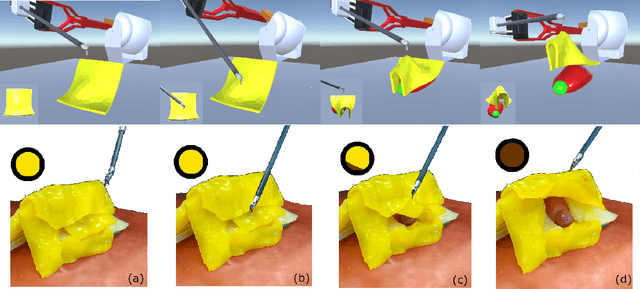
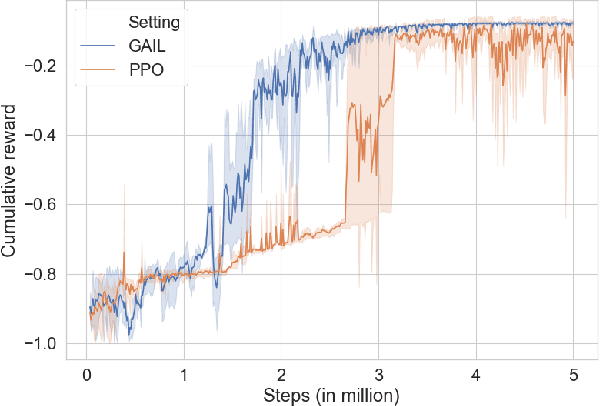
The current research focus in Robot-Assisted Minimally Invasive Surgery (RAMIS) is directed towards increasing the level of robot autonomy, to place surgeons in a supervisory position. Although Learning from Demonstrations (LfD) approaches are among the preferred ways for an autonomous surgical system to learn expert gestures, they require a high number of demonstrations and show poor generalization to the variable conditions of the surgical environment. In this work, we propose an LfD methodology based on Generative Adversarial Imitation Learning (GAIL) that is built on a Deep Reinforcement Learning (DRL) setting. GAIL combines generative adversarial networks to learn the distribution of expert trajectories with a DRL setting to ensure generalisation of trajectories providing human-like behaviour. We consider automation of tissue retraction, a common RAMIS task that involves soft tissues manipulation to expose a region of interest. In our proposed methodology, a small set of expert trajectories can be acquired through the da Vinci Research Kit (dVRK) and used to train the proposed LfD method inside a simulated environment. Results indicate that our methodology can accomplish the tissue retraction task with human-like behaviour while being more sample-efficient than the baseline DRL method. Towards the end, we show that the learnt policies can be successfully transferred to the real robotic platform and deployed for soft tissue retraction on a synthetic phantom.
Safe Reinforcement Learning using Formal Verification for Tissue Retraction in Autonomous Robotic-Assisted Surgery
Sep 06, 2021

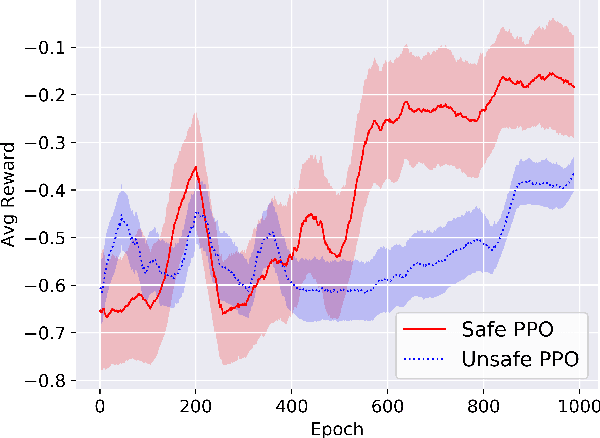
Deep Reinforcement Learning (DRL) is a viable solution for automating repetitive surgical subtasks due to its ability to learn complex behaviours in a dynamic environment. This task automation could lead to reduced surgeon's cognitive workload, increased precision in critical aspects of the surgery, and fewer patient-related complications. However, current DRL methods do not guarantee any safety criteria as they maximise cumulative rewards without considering the risks associated with the actions performed. Due to this limitation, the application of DRL in the safety-critical paradigm of robot-assisted Minimally Invasive Surgery (MIS) has been constrained. In this work, we introduce a Safe-DRL framework that incorporates safety constraints for the automation of surgical subtasks via DRL training. We validate our approach in a virtual scene that replicates a tissue retraction task commonly occurring in multiple phases of an MIS. Furthermore, to evaluate the safe behaviour of the robotic arms, we formulate a formal verification tool for DRL methods that provides the probability of unsafe configurations. Our results indicate that a formal analysis guarantees safety with high confidence such that the robotic instruments operate within the safe workspace and avoid hazardous interaction with other anatomical structures.
Towards Hierarchical Task Decomposition using Deep Reinforcement Learning for Pick and Place Subtasks
Mar 01, 2021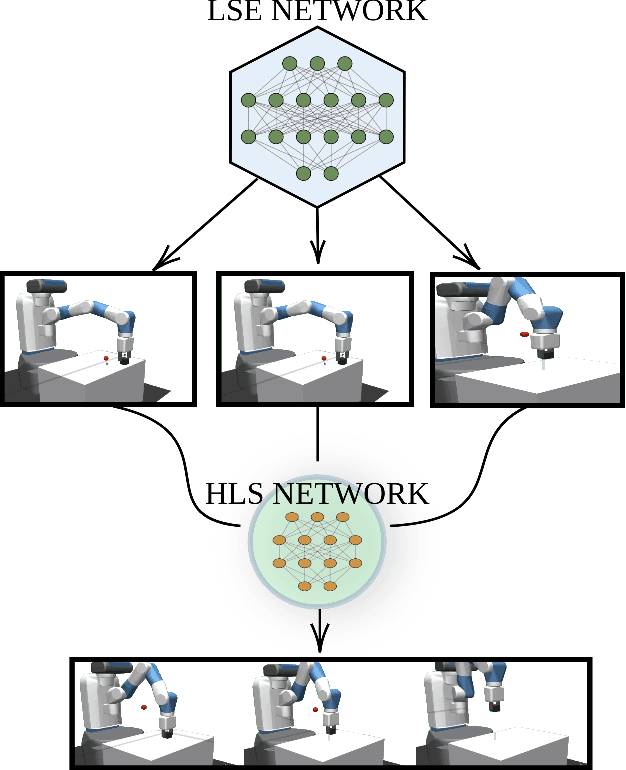


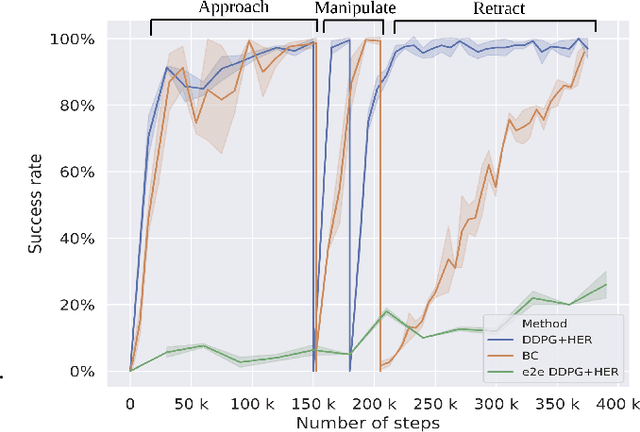
Deep Reinforcement Learning (DRL) is emerging as a promising approach to generate adaptive behaviors for robotic platforms. However, a major drawback of using DRL is the data-hungry training regime that requires millions of trial and error attempts, which is impractical when running experiments on robotic systems. To address this issue, we propose a multi-subtask reinforcement learning method where complex tasks are decomposed manually into low-level subtasks by leveraging human domain knowledge. These subtasks can be parametrized as expert networks and learned via existing DRL methods. Trained subtasks can then be composed with a high-level choreographer. As a testbed, we use a pick and place robotic simulator to demonstrate our methodology, and show that our method outperforms an imitation learning-based method and reaches a high success rate compared to an end-to-end learning approach. Moreover, we transfer the learned behavior in a different robotic environment that allows us to exploit sim-to-real transfer and demonstrate the trajectories in a real robotic system. Our training regime is carried out using a central processing unit (CPU)-based system, which demonstrates the data-efficient properties of our approach.
Intrinsic Robotic Introspection: Learning Internal States From Neuron Activations
Nov 03, 2020
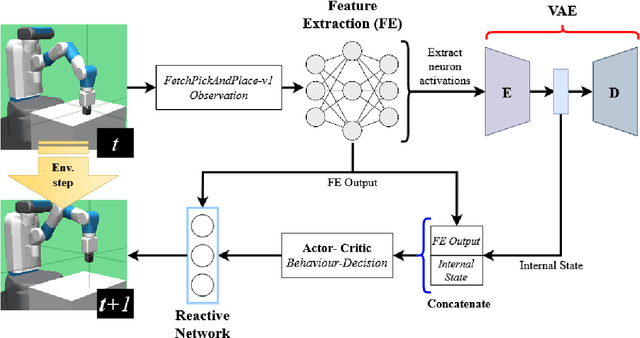
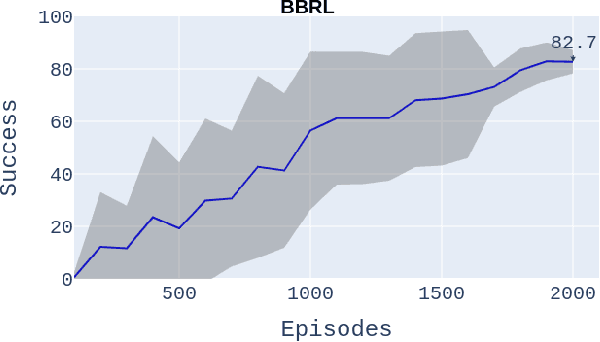
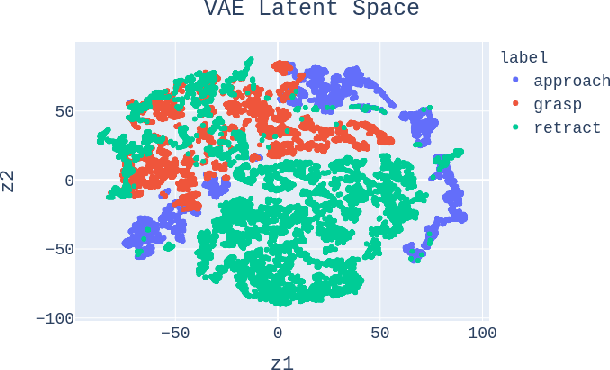
We present an introspective framework inspired by the process of how humans perform introspection. Our working assumption is that neural network activations encode information, and building internal states from these activations can improve the performance of an actor-critic model. We perform experiments where we first train a Variational Autoencoder model to reconstruct the activations of a feature extraction network and use the latent space to improve the performance of an actor-critic when deciding which low-level robotic behaviour to execute. We show that internal states reduce the number of episodes needed by about 1300 episodes while training an actor-critic, denoting faster convergence to get a high success value while completing a robotic task.
On Simple Reactive Neural Networks for Behaviour-Based Reinforcement Learning
Jan 22, 2020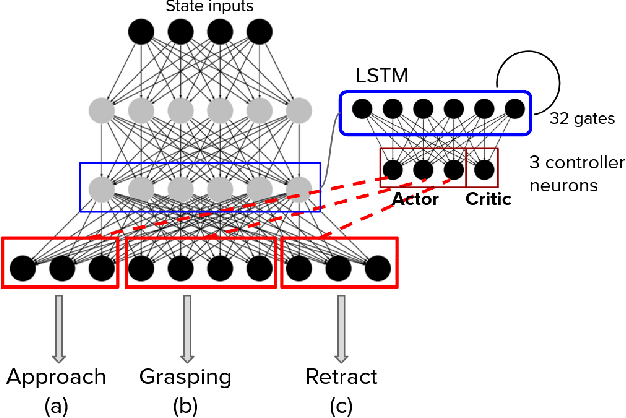
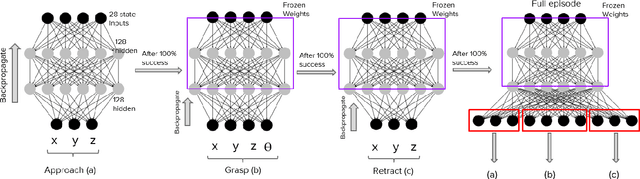

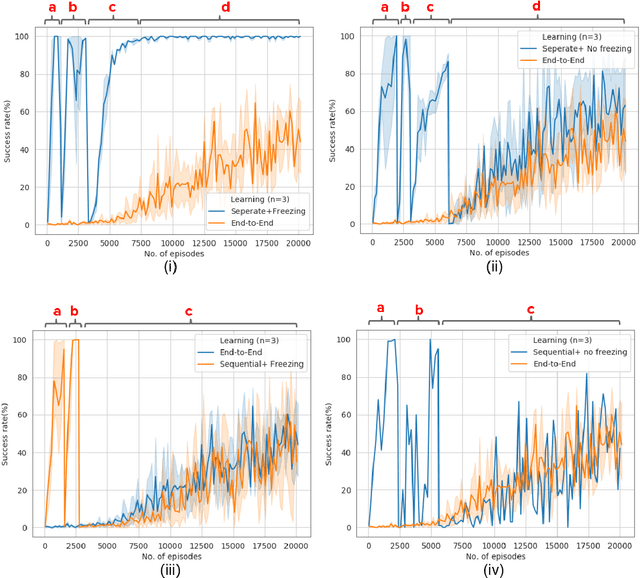
We present a behaviour-based reinforcement learning approach, inspired by Brook's subsumption architecture, in which simple fully connected networks are trained as reactive behaviours. Our working assumption is that a pick and place robotic task can be simplified by leveraging domain knowledge of a robotics developer to decompose and train such reactive behaviours; namely, approach, grasp, and retract. Then the robot autonomously learns how to combine them via an Actor-Critic architecture. The Actor-Critic policy is to determine the activation and inhibition mechanisms of the reactive behaviours in a particular temporal sequence. We validate our approach in a simulated robot environment where the task is picking a block and taking it to a target position while orienting the gripper from a top grasp. The latter represents an extra degree-of-freedom of which current end-to-end reinforcement learning fail to generalise. Our findings suggest that robotic learning can be more effective if each behaviour is learnt in isolation and then combined them to accomplish the task. That is, our approach learns the pick and place task in 8,000 episodes, which represents a drastic reduction in the number of training episodes required by an end-to-end approach and the existing state-of-the-art algorithms.