 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncertainty Aware-Predictive Control Barrier Functions: Safer Human Robot Interaction through Probabilistic Motion Forecasting
Aug 28, 2025To enable flexible, high-throughput automation in settings where people and robots share workspaces, collaborative robotic cells must reconcile stringent safety guarantees with the need for responsive and effective behavior. A dynamic obstacle is the stochastic, task-dependent variability of human motion: when robots fall back on purely reactive or worst-case envelopes, they brake unnecessarily, stall task progress, and tamper with the fluidity that true Human-Robot Interaction demands. In recent years, learning-based human-motion prediction has rapidly advanced, although most approaches produce worst-case scenario forecasts that often do not treat prediction uncertainty in a well-structured way, resulting in over-conservative planning algorithms, limiting their flexibility. We introduce Uncertainty-Aware Predictive Control Barrier Functions (UA-PCBFs), a unified framework that fuses probabilistic human hand motion forecasting with the formal safety guarantees of Control Barrier Functions. In contrast to other variants, our framework allows for dynamic adjustment of the safety margin thanks to the human motion uncertainty estimation provided by a forecasting module. Thanks to uncertainty estimation, UA-PCBFs empower collaborative robots with a deeper understanding of future human states, facilitating more fluid and intelligent interactions through informed motion planning. We validate UA-PCBFs through comprehensive real-world experiments with an increasing level of realism, including automated setups (to perform exactly repeatable motions) with a robotic hand and direct human-robot interactions (to validate promptness, usability, and human confidence). Relative to state-of-the-art HRI architectures, UA-PCBFs show better performance in task-critical metrics, significantly reducing the number of violations of the robot's safe space during interaction with respect to the state-of-the-art.
DEAR: Disentangled Environment and Agent Representations for Reinforcement Learning without Reconstruction
Jun 30, 2024Reinforcement Learning (RL) algorithms can learn robotic control tasks from visual observations, but they often require a large amount of data, especially when the visual scene is complex and unstructured. In this paper, we explore how the agent's knowledge of its shape can improve the sample efficiency of visual RL methods. We propose a novel method, Disentangled Environment and Agent Representations (DEAR), that uses the segmentation mask of the agent as supervision to learn disentangled representations of the environment and the agent through feature separation constraints. Unlike previous approaches, DEAR does not require reconstruction of visual observations. These representations are then used as an auxiliary loss to the RL objective, encouraging the agent to focus on the relevant features of the environment. We evaluate DEAR on two challenging benchmarks: Distracting DeepMind control suite and Franka Kitchen manipulation tasks. Our findings demonstrate that DEAR surpasses state-of-the-art methods in sample efficiency, achieving comparable or superior performance with reduced parameters. Our results indicate that integrating agent knowledge into visual RL methods has the potential to enhance their learning efficiency and robustness.
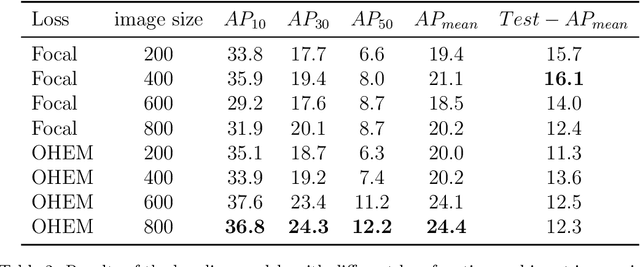
The SARAS Endoscopic Surgeon Action Detection (ESAD) dataset: Challenges and methods
Apr 07, 2021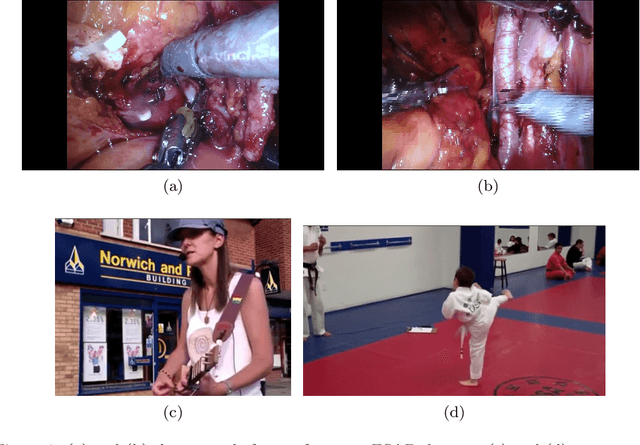
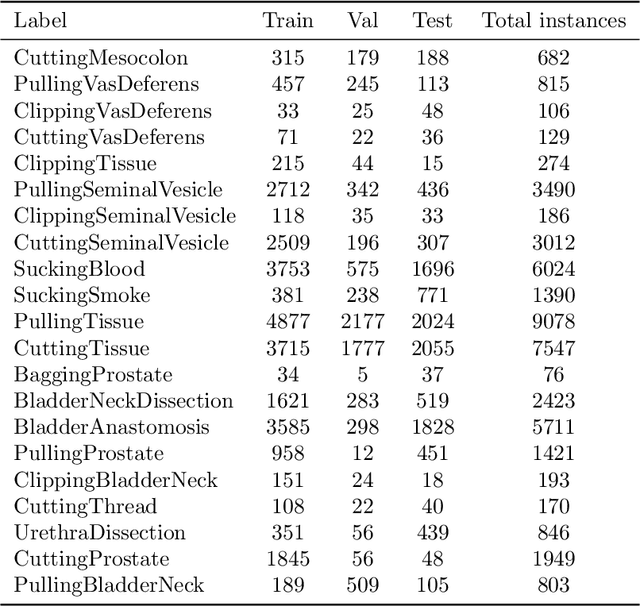
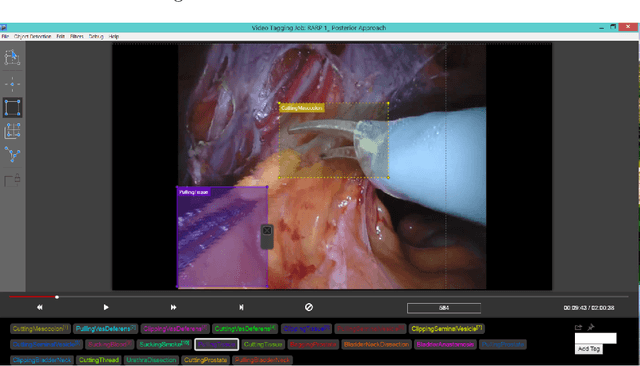
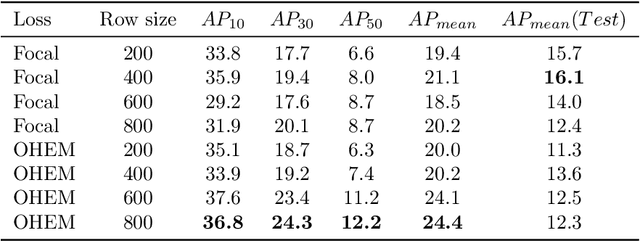
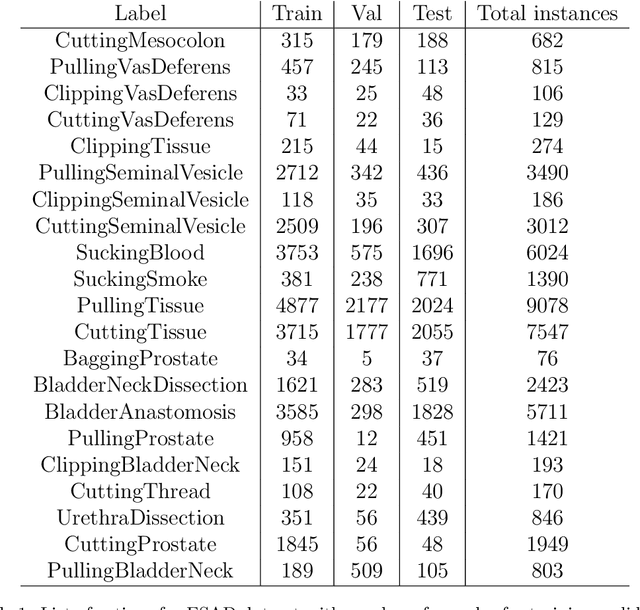
For an autonomous robotic system, monitoring surgeon actions and assisting the main surgeon during a procedure can be very challenging. The challenges come from the peculiar structure of the surgical scene, the greater similarity in appearance of actions performed via tools in a cavity compared to, say, human actions in unconstrained environments, as well as from the motion of the endoscopic camera. This paper presents ESAD, the first large-scale dataset designed to tackle the problem of surgeon action detection in endoscopic minimally invasive surgery. ESAD aims at contributing to increase the effectiveness and reliability of surgical assistant robots by realistically testing their awareness of the actions performed by a surgeon. The dataset provides bounding box annotation for 21 action classes on real endoscopic video frames captured during prostatectomy, and was used as the basis of a recent MIDL 2020 challenge. We also present an analysis of the dataset conducted using the baseline model which was released as part of the challenge, and a description of the top performing models submitted to the challenge together with the results they obtained. This study provides significant insight into what approaches can be effective and can be extended further. We believe that ESAD will serve in the future as a useful benchmark for all researchers active in surgeon action detection and assistive robotics at large.
Improving rigid 3D calibration for robotic surgery
Jul 16, 2020
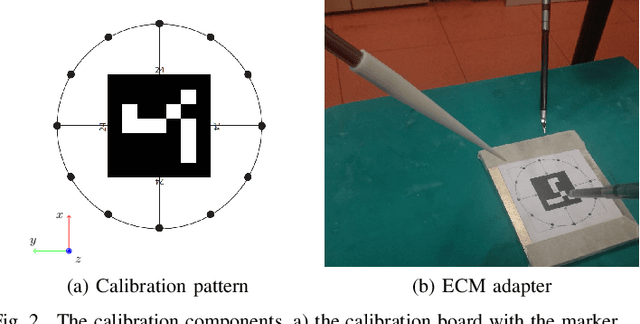

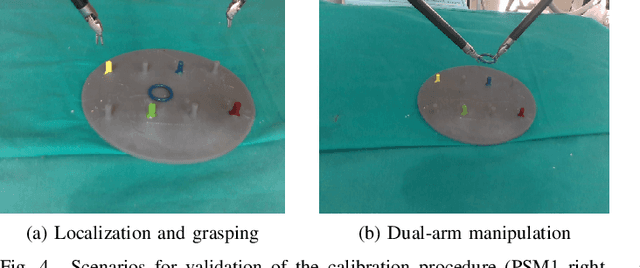
Autonomy is the frontier of research in robotic surgery and its aim is to improve the quality of surgical procedures in the next future. One fundamental requirement for autonomy is advanced perception capability through vision sensors. In this paper, we propose a novel calibration technique for a surgical scenario with da Vinci robot. Calibration of the camera and the robot is necessary for precise positioning of the tools in order to emulate the high performance surgeons. Our calibration technique is tailored for RGB-D camera. Different tests performed on relevant use cases for surgery prove that we significantly improve precision and accuracy with respect to the state of the art solutions for similar devices on a surgical-size setup. Moreover, our calibration method can be easily extended to standard surgical endoscope to prompt its use in real surgical scenario.
ESAD: Endoscopic Surgeon Action Detection Dataset
Jun 12, 2020
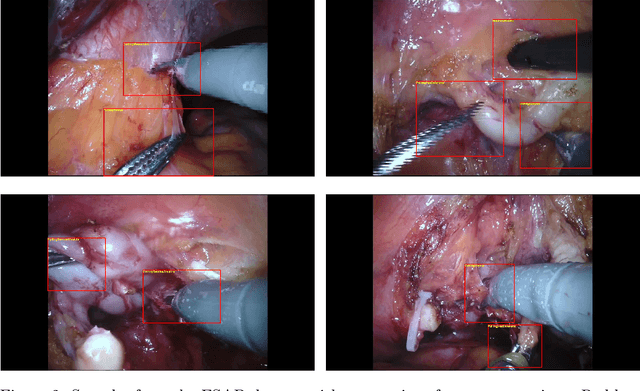
In this work, we take aim towards increasing the effectiveness of surgical assistant robots. We intended to make assistant robots safer by making them aware about the actions of surgeon, so it can take appropriate assisting actions. In other words, we aim to solve the problem of surgeon action detection in endoscopic videos. To this, we introduce a challenging dataset for surgeon action detection in real-world endoscopic videos. Action classes are picked based on the feedback of surgeons and annotated by medical professional. Given a video frame, we draw bounding box around surgical tool which is performing action and label it with action label. Finally, we presenta frame-level action detection baseline model based on recent advances in ob-ject detection. Results on our new dataset show that our presented dataset provides enough interesting challenges for future method and it can serveas strong benchmark corresponding research in surgeon action detection in endoscopic videos.
Inertial Parameter Identification Including Friction and Motor Dynamics
Oct 16, 2014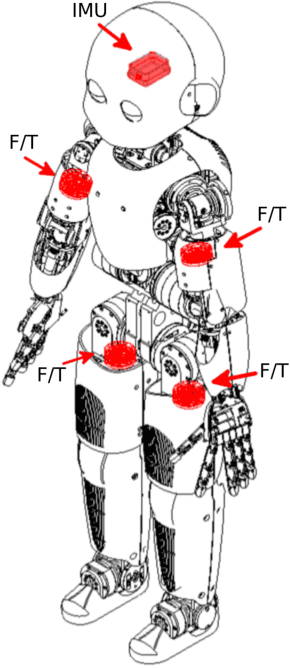
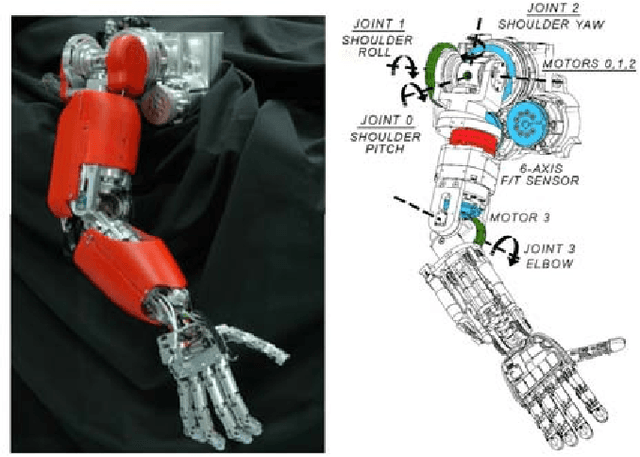
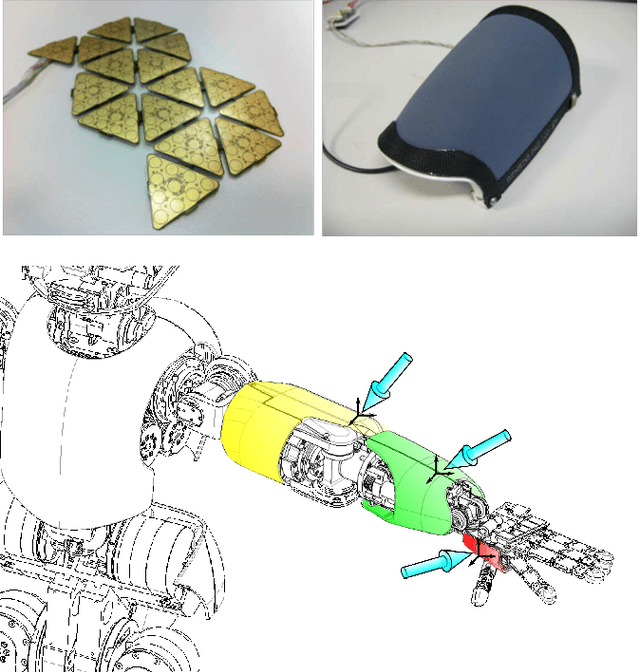
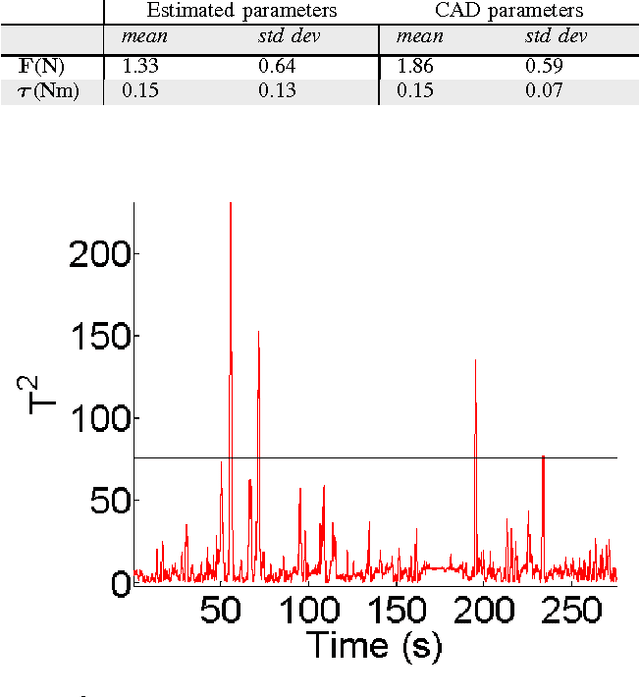
Identification of inertial parameters is fundamental for the implementation of torque-based control in humanoids. At the same time, good models of friction and actuator dynamics are critical for the low-level control of joint torques. We propose a novel method to identify inertial, friction and motor parameters in a single procedure. The identification exploits the measurements of the PWM of the DC motors and a 6-axis force/torque sensor mounted inside the kinematic chain. The partial least-square (PLS) method is used to perform the regression. We identified the inertial, friction and motor parameters of the right arm of the iCub humanoid robot. We verified that the identified model can accurately predict the force/torque sensor measurements and the motor voltages. Moreover, we compared the identified parameters against the CAD parameters, in the prediction of the force/torque sensor measurements. Finally, we showed that the estimated model can effectively detect external contacts, comparing it against a tactile-based contact detection. The presented approach offers some advantages with respect to other state-of-the-art methods, because of its completeness (i.e. it identifies inertial, friction and motor parameters) and simplicity (only one data collection, with no particular requirements).