 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplain Yourself, Briefly! Self-Explaining Neural Networks with Concise Sufficient Reasons
Paper and Code


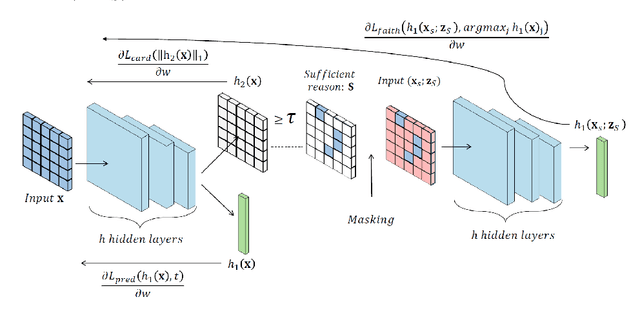
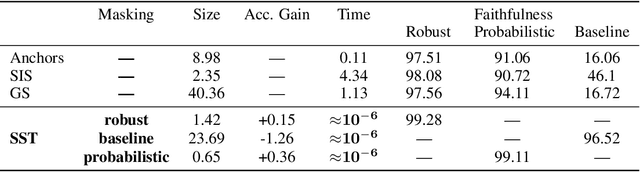
Minimal sufficient reasons represent a prevalent form of explanation - the smallest subset of input features which, when held constant at their corresponding values, ensure that the prediction remains unchanged. Previous post-hoc methods attempt to obtain such explanations but face two main limitations: (1) Obtaining these subsets poses a computational challenge, leading most scalable methods to converge towards suboptimal, less meaningful subsets; (2) These methods heavily rely on sampling out-of-distribution input assignments, potentially resulting in counterintuitive behaviors. To tackle these limitations, we propose in this work a self-supervised training approach, which we term *sufficient subset training* (SST). Using SST, we train models to generate concise sufficient reasons for their predictions as an integral part of their output. Our results indicate that our framework produces succinct and faithful subsets substantially more efficiently than competing post-hoc methods, while maintaining comparable predictive performance.