 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowledge Graph-Augmented Abstractive Summarization with Semantic-Driven Cloze Reward
Paper and Code


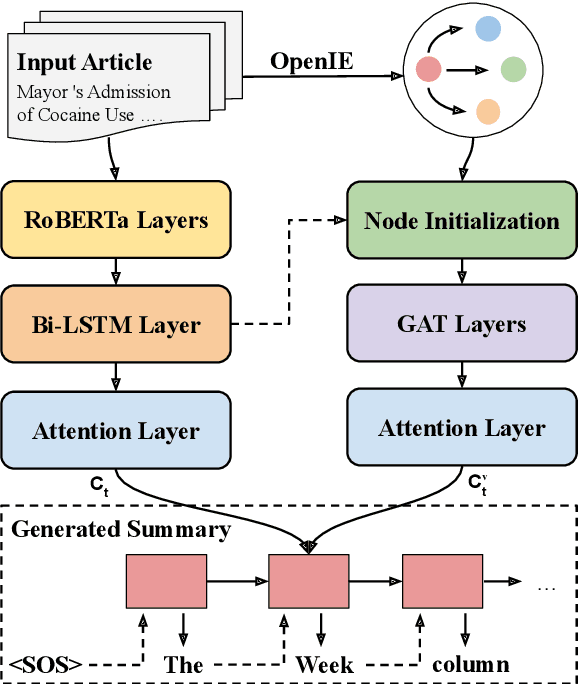

Sequence-to-sequence models for abstractive summarization have been studied extensively, yet the generated summaries commonly suffer from fabricated content, and are often found to be near-extractive. We argue that, to address these issues, the summarizer should acquire semantic interpretation over input, e.g., via structured representation, to allow the generation of more informative summaries. In this paper, we present ASGARD, a novel framework for Abstractive Summarization with Graph-Augmentation and semantic-driven RewarD. We propose the use of dual encoders---a sequential document encoder and a graph-structured encoder---to maintain the global context and local characteristics of entities, complementing each other. We further design a reward based on a multiple choice cloze test to drive the model to better capture entity interactions. Results show that our models produce significantly higher ROUGE scores than a variant without knowledge graph as input on both New York Times and CNN/Daily Mail datasets. We also obtain better or comparable performance compared to systems that are fine-tuned from large pretrained language models. Human judges further rate our model outputs as more informative and containing fewer unfaithful errors.