 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient k-Nearest-Neighbor Machine Translation with Dynamic Retrieval
Paper and Code
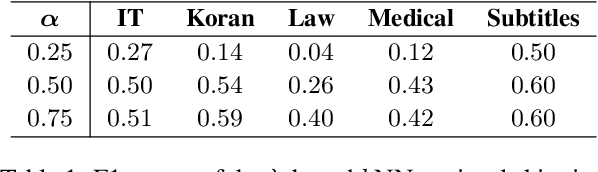
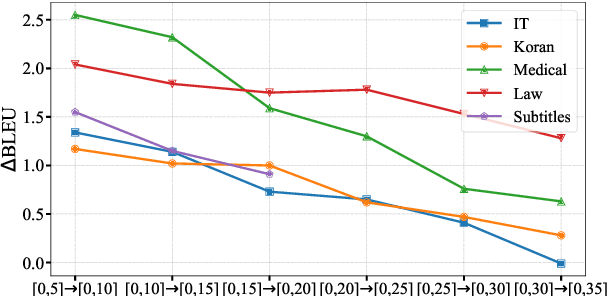
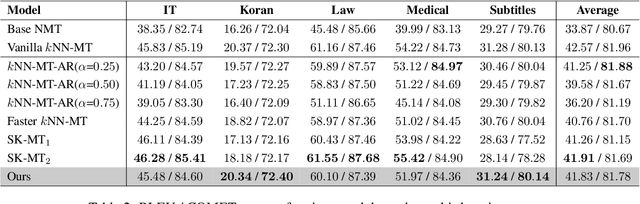
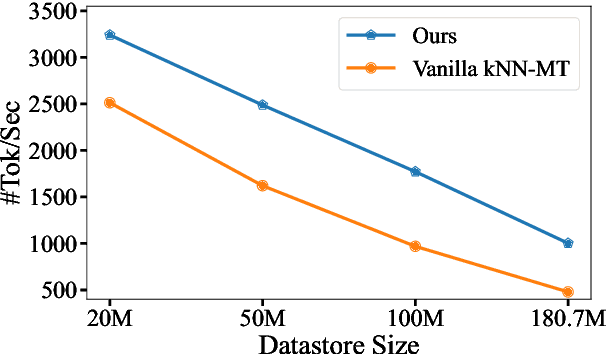
To achieve non-parametric NMT domain adaptation, $k$-Nearest-Neighbor Machine Translation ($k$NN-MT) constructs an external datastore to store domain-specific translation knowledge, which derives a $k$NN distribution to interpolate the prediction distribution of the NMT model via a linear interpolation coefficient $\lambda$. Despite its success, $k$NN retrieval at each timestep leads to substantial time overhead. To address this issue, dominant studies resort to $k$NN-MT with adaptive retrieval ($k$NN-MT-AR), which dynamically estimates $\lambda$ and skips $k$NN retrieval if $\lambda$ is less than a fixed threshold. Unfortunately, $k$NN-MT-AR does not yield satisfactory results. In this paper, we first conduct a preliminary study to reveal two key limitations of $k$NN-MT-AR: 1) the optimization gap leads to inaccurate estimation of $\lambda$ for determining $k$NN retrieval skipping, and 2) using a fixed threshold fails to accommodate the dynamic demands for $k$NN retrieval at different timesteps. To mitigate these limitations, we then propose $k$NN-MT with dynamic retrieval ($k$NN-MT-DR) that significantly extends vanilla $k$NN-MT in two aspects. Firstly, we equip $k$NN-MT with a MLP-based classifier for determining whether to skip $k$NN retrieval at each timestep. Particularly, we explore several carefully-designed scalar features to fully exert the potential of the classifier. Secondly, we propose a timestep-aware threshold adjustment method to dynamically generate the threshold, which further improves the efficiency of our model. Experimental results on the widely-used datasets demonstrate the effectiveness and generality of our model.\footnote{Our code is available at \url{https://github.com/DeepLearnXMU/knn-mt-dr}.