 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan LLMs Track Their Output Length? A Dynamic Feedback Mechanism for Precise Length Regulation
Jan 07, 2026Precisely controlling the length of generated text is a common requirement in real-world applications. However, despite significant advancements in following human instructions, Large Language Models (LLMs) still struggle with this task. In this work, we demonstrate that LLMs often fail to accurately measure their response lengths, leading to poor adherence to length constraints. To address this issue, we propose a novel length regulation approach that incorporates dynamic length feedback during generation, enabling adaptive adjustments to meet target lengths. Experiments on summarization and biography tasks show our training-free approach significantly improves precision in achieving target token, word, or sentence counts without compromising quality. Additionally, we demonstrate that further supervised fine-tuning allows our method to generalize effectively to broader text-generation tasks.
SPAN: Benchmarking and Improving Cross-Calendar Temporal Reasoning of Large Language Models
Nov 13, 2025We introduce SPAN, a cross-calendar temporal reasoning benchmark, which requires LLMs to perform intra-calendar temporal reasoning and inter-calendar temporal conversion. SPAN features ten cross-calendar temporal reasoning directions, two reasoning types, and two question formats across six calendars. To enable time-variant and contamination-free evaluation, we propose a template-driven protocol for dynamic instance generation that enables assessment on a user-specified Gregorian date. We conduct extensive experiments on both open- and closed-source state-of-the-art (SOTA) LLMs over a range of dates spanning 100 years from 1960 to 2060. Our evaluations show that these LLMs achieve an average accuracy of only 34.5%, with none exceeding 80%, indicating that this task remains challenging. Through in-depth analysis of reasoning types, question formats, and temporal reasoning directions, we identify two key obstacles for LLMs: Future-Date Degradation and Calendar Asymmetry Bias. To strengthen LLMs' cross-calendar temporal reasoning capability, we further develop an LLM-powered Time Agent that leverages tool-augmented code generation. Empirical results show that Time Agent achieves an average accuracy of 95.31%, outperforming several competitive baselines, highlighting the potential of tool-augmented code generation to advance cross-calendar temporal reasoning. We hope this work will inspire further efforts toward more temporally and culturally adaptive LLMs.
Efficient k-Nearest-Neighbor Machine Translation with Dynamic Retrieval
Jun 10, 2024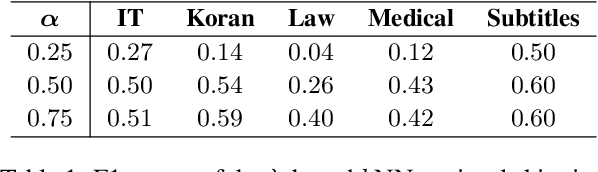
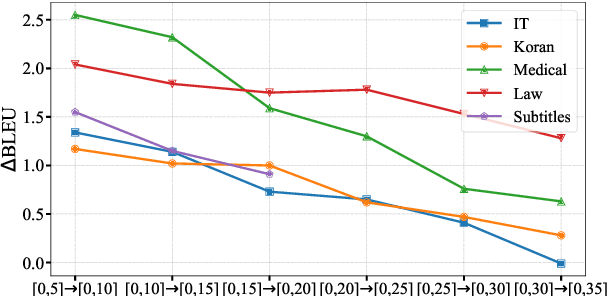
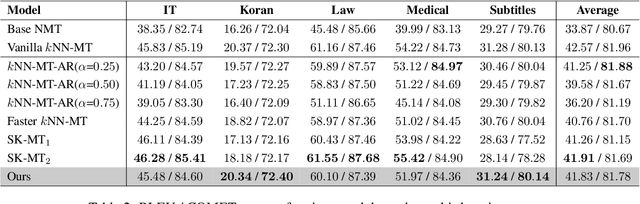
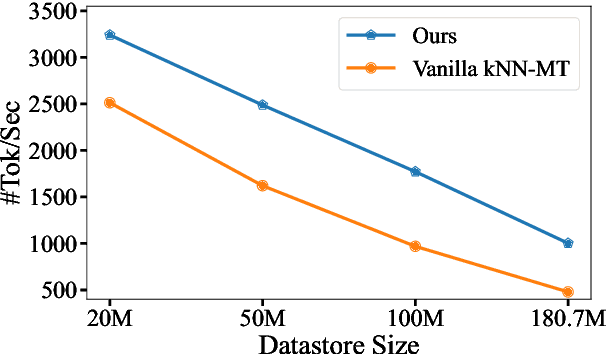
To achieve non-parametric NMT domain adaptation, $k$-Nearest-Neighbor Machine Translation ($k$NN-MT) constructs an external datastore to store domain-specific translation knowledge, which derives a $k$NN distribution to interpolate the prediction distribution of the NMT model via a linear interpolation coefficient $\lambda$. Despite its success, $k$NN retrieval at each timestep leads to substantial time overhead. To address this issue, dominant studies resort to $k$NN-MT with adaptive retrieval ($k$NN-MT-AR), which dynamically estimates $\lambda$ and skips $k$NN retrieval if $\lambda$ is less than a fixed threshold. Unfortunately, $k$NN-MT-AR does not yield satisfactory results. In this paper, we first conduct a preliminary study to reveal two key limitations of $k$NN-MT-AR: 1) the optimization gap leads to inaccurate estimation of $\lambda$ for determining $k$NN retrieval skipping, and 2) using a fixed threshold fails to accommodate the dynamic demands for $k$NN retrieval at different timesteps. To mitigate these limitations, we then propose $k$NN-MT with dynamic retrieval ($k$NN-MT-DR) that significantly extends vanilla $k$NN-MT in two aspects. Firstly, we equip $k$NN-MT with a MLP-based classifier for determining whether to skip $k$NN retrieval at each timestep. Particularly, we explore several carefully-designed scalar features to fully exert the potential of the classifier. Secondly, we propose a timestep-aware threshold adjustment method to dynamically generate the threshold, which further improves the efficiency of our model. Experimental results on the widely-used datasets demonstrate the effectiveness and generality of our model.\footnote{Our code is available at \url{https://github.com/DeepLearnXMU/knn-mt-dr}.
Towards Better Document-level Relation Extraction via Iterative Inference
Nov 26, 2022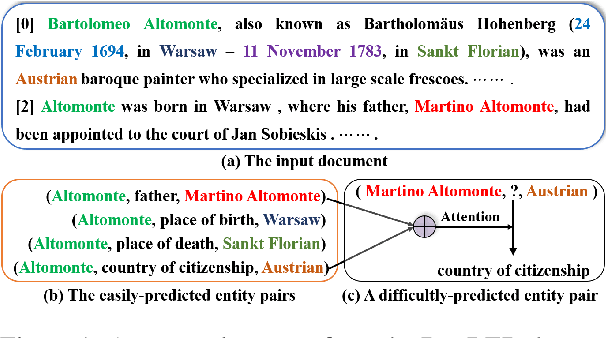
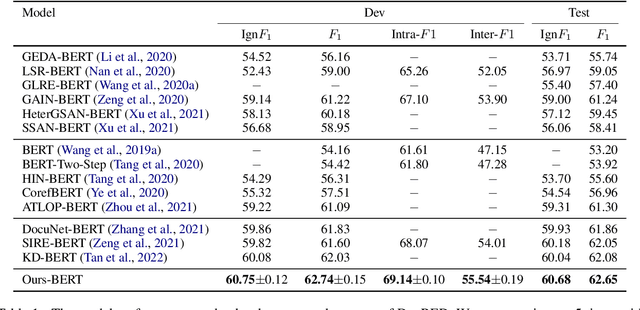
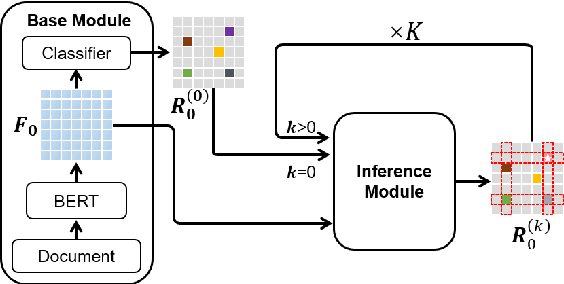
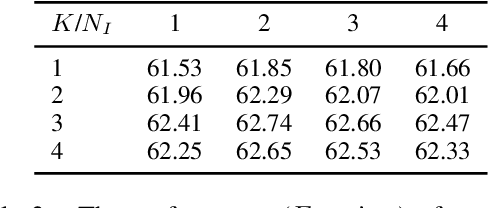
Document-level relation extraction (RE) aims to extract the relations between entities from the input document that usually containing many difficultly-predicted entity pairs whose relations can only be predicted through relational inference. Existing methods usually directly predict the relations of all entity pairs of input document in a one-pass manner, ignoring the fact that predictions of some entity pairs heavily depend on the predicted results of other pairs. To deal with this issue, in this paper, we propose a novel document-level RE model with iterative inference. Our model is mainly composed of two modules: 1) a base module expected to provide preliminary relation predictions on entity pairs; 2) an inference module introduced to refine these preliminary predictions by iteratively dealing with difficultly-predicted entity pairs depending on other pairs in an easy-to-hard manner. Unlike previous methods which only consider feature information of entity pairs, our inference module is equipped with two Extended Cross Attention units, allowing it to exploit both feature information and previous predictions of entity pairs during relational inference. Furthermore, we adopt a two-stage strategy to train our model. At the first stage, we only train our base module. During the second stage, we train the whole model, where contrastive learning is introduced to enhance the training of inference module. Experimental results on three commonly-used datasets show that our model consistently outperforms other competitive baselines.