 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Dubbing: End-to-End Auto-Audiobook System with Text-to-Timbre and Context-Aware Instruct-TTS
Sep 19, 2025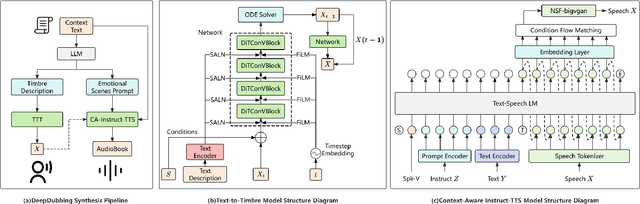


The pipeline for multi-participant audiobook production primarily consists of three stages: script analysis, character voice timbre selection, and speech synthesis. Among these, script analysis can be automated with high accuracy using NLP models, whereas character voice timbre selection still relies on manual effort. Speech synthesis uses either manual dubbing or text-to-speech (TTS). While TTS boosts efficiency, it struggles with emotional expression, intonation control, and contextual scene adaptation. To address these challenges, we propose DeepDubbing, an end-to-end automated system for multi-participant audiobook production. The system comprises two main components: a Text-to-Timbre (TTT) model and a Context-Aware Instruct-TTS (CA-Instruct-TTS) model. The TTT model generates role-specific timbre embeddings conditioned on text descriptions. The CA-Instruct-TTS model synthesizes expressive speech by analyzing contextual dialogue and incorporating fine-grained emotional instructions. This system enables the automated generation of multi-participant audiobooks with both timbre-matched character voices and emotionally expressive narration, offering a novel solution for audiobook production.
Towards Text-Image Interleaved Retrieval
Feb 18, 2025Current multimodal information retrieval studies mainly focus on single-image inputs, which limits real-world applications involving multiple images and text-image interleaved content. In this work, we introduce the text-image interleaved retrieval (TIIR) task, where the query and document are interleaved text-image sequences, and the model is required to understand the semantics from the interleaved context for effective retrieval. We construct a TIIR benchmark based on naturally interleaved wikiHow tutorials, where a specific pipeline is designed to generate interleaved queries. To explore the task, we adapt several off-the-shelf retrievers and build a dense baseline by interleaved multimodal large language model (MLLM). We then propose a novel Matryoshka Multimodal Embedder (MME), which compresses the number of visual tokens at different granularity, to address the challenge of excessive visual tokens in MLLM-based TIIR models. Experiments demonstrate that simple adaption of existing models does not consistently yield effective results. Our MME achieves significant improvements over the baseline by substantially fewer visual tokens. We provide extensive analysis and will release the dataset and code to facilitate future research.
GME: Improving Universal Multimodal Retrieval by Multimodal LLMs
Dec 22, 2024



Universal Multimodal Retrieval (UMR) aims to enable search across various modalities using a unified model, where queries and candidates can consist of pure text, images, or a combination of both. Previous work has attempted to adopt multimodal large language models (MLLMs) to realize UMR using only text data. However, our preliminary experiments demonstrate that more diverse multimodal training data can further unlock the potential of MLLMs. Despite its effectiveness, the existing multimodal training data is highly imbalanced in terms of modality, which motivates us to develop a training data synthesis pipeline and construct a large-scale, high-quality fused-modal training dataset. Based on the synthetic training data, we develop the General Multimodal Embedder (GME), an MLLM-based dense retriever designed for UMR. Furthermore, we construct a comprehensive UMR Benchmark (UMRB) to evaluate the effectiveness of our approach. Experimental results show that our method achieves state-of-the-art performance among existing UMR methods. Last, we provide in-depth analyses of model scaling, training strategies, and perform ablation studies on both the model and synthetic data.
mGTE: Generalized Long-Context Text Representation and Reranking Models for Multilingual Text Retrieval
Jul 29, 2024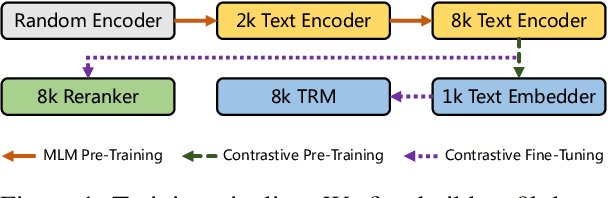

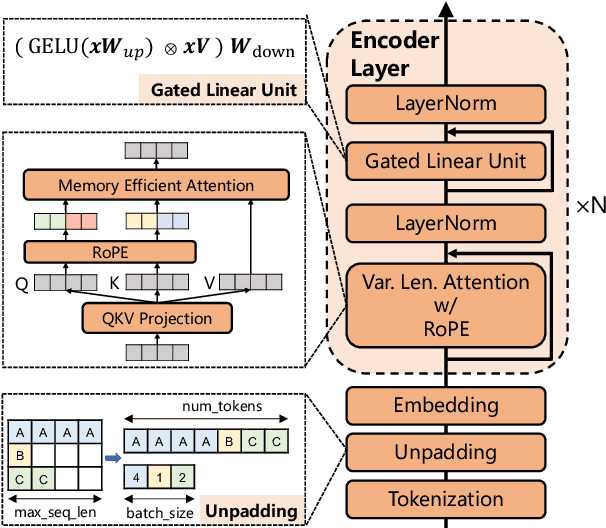
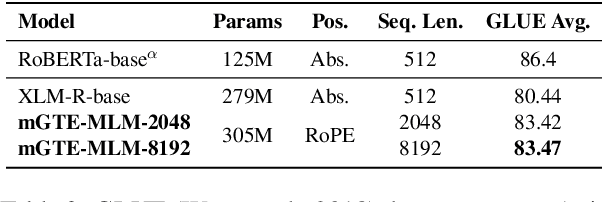
We present systematic efforts in building long-context multilingual text representation model (TRM) and reranker from scratch for text retrieval. We first introduce a text encoder (base size) enhanced with RoPE and unpadding, pre-trained in a native 8192-token context (longer than 512 of previous multilingual encoders). Then we construct a hybrid TRM and a cross-encoder reranker by contrastive learning. Evaluations show that our text encoder outperforms the same-sized previous state-of-the-art XLM-R. Meanwhile, our TRM and reranker match the performance of large-sized state-of-the-art BGE-M3 models and achieve better results on long-context retrieval benchmarks. Further analysis demonstrate that our proposed models exhibit higher efficiency during both training and inference. We believe their efficiency and effectiveness could benefit various researches and industrial applications.