 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaking Bias Non-Predictive: Training Robust LLM Judges via Reinforcement Learning
Feb 02, 2026Large language models (LLMs) increasingly serve as automated judges, yet they remain susceptible to cognitive biases -- often altering their reasoning when faced with spurious prompt-level cues such as consensus claims or authority appeals. Existing mitigations via prompting or supervised fine-tuning fail to generalize, as they modify surface behavior without changing the optimization objective that makes bias cues predictive. To address this gap, we propose Epistemic Independence Training (EIT), a reinforcement learning framework grounded in a key principle: to learn independence, bias cues must be made non-predictive of reward. EIT operationalizes this through a balanced conflict strategy where bias signals are equally likely to support correct and incorrect answers, combined with a reward design that penalizes bias-following without rewarding bias agreement. Experiments on Qwen3-4B demonstrate that EIT improves both accuracy and robustness under adversarial biases, while preserving performance when bias aligns with truth. Notably, models trained only on bandwagon bias generalize to unseen bias types such as authority and distraction, indicating that EIT induces transferable epistemic independence rather than bias-specific heuristics. Code and data are available at https://anonymous.4open.science/r/bias-mitigation-with-rl-BC47.
TNStream: Applying Tightest Neighbors to Micro-Clusters to Define Multi-Density Clusters in Streaming Data
May 01, 2025In data stream clustering, systematic theory of stream clustering algorithms remains relatively scarce. Recently, density-based methods have gained attention. However, existing algorithms struggle to simultaneously handle arbitrarily shaped, multi-density, high-dimensional data while maintaining strong outlier resistance. Clustering quality significantly deteriorates when data density varies complexly. This paper proposes a clustering algorithm based on the novel concept of Tightest Neighbors and introduces a data stream clustering theory based on the Skeleton Set. Based on these theories, this paper develops a new method, TNStream, a fully online algorithm. The algorithm adaptively determines the clustering radius based on local similarity, summarizing the evolution of multi-density data streams in micro-clusters. It then applies a Tightest Neighbors-based clustering algorithm to form final clusters. To improve efficiency in high-dimensional cases, Locality-Sensitive Hashing (LSH) is employed to structure micro-clusters, addressing the challenge of storing k-nearest neighbors. TNStream is evaluated on various synthetic and real-world datasets using different clustering metrics. Experimental results demonstrate its effectiveness in improving clustering quality for multi-density data and validate the proposed data stream clustering theory.
Yi-Lightning Technical Report
Dec 03, 2024



This technical report presents Yi-Lightning, our latest flagship large language model (LLM). It achieves exceptional performance, ranking 6th overall on Chatbot Arena, with particularly strong results (2nd to 4th place) in specialized categories including Chinese, Math, Coding, and Hard Prompts. Yi-Lightning leverages an enhanced Mixture-of-Experts (MoE) architecture, featuring advanced expert segmentation and routing mechanisms coupled with optimized KV-caching techniques. Our development process encompasses comprehensive pre-training, supervised fine-tuning (SFT), and reinforcement learning from human feedback (RLHF), where we devise deliberate strategies for multi-stage training, synthetic data construction, and reward modeling. Furthermore, we implement RAISE (Responsible AI Safety Engine), a four-component framework to address safety issues across pre-training, post-training, and serving phases. Empowered by our scalable super-computing infrastructure, all these innovations substantially reduce training, deployment and inference costs while maintaining high-performance standards. With further evaluations on public academic benchmarks, Yi-Lightning demonstrates competitive performance against top-tier LLMs, while we observe a notable disparity between traditional, static benchmark results and real-world, dynamic human preferences. This observation prompts a critical reassessment of conventional benchmarks' utility in guiding the development of more intelligent and powerful AI systems for practical applications. Yi-Lightning is now available through our developer platform at https://platform.lingyiwanwu.com.
I Can Hear You: Selective Robust Training for Deepfake Audio Detection
Oct 31, 2024


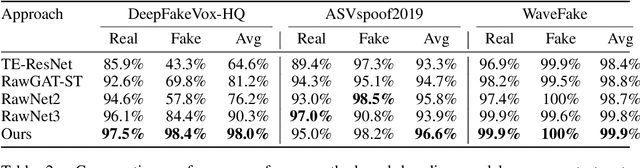
Recent advances in AI-generated voices have intensified the challenge of detecting deepfake audio, posing risks for scams and the spread of disinformation. To tackle this issue, we establish the largest public voice dataset to date, named DeepFakeVox-HQ, comprising 1.3 million samples, including 270,000 high-quality deepfake samples from 14 diverse sources. Despite previously reported high accuracy, existing deepfake voice detectors struggle with our diversely collected dataset, and their detection success rates drop even further under realistic corruptions and adversarial attacks. We conduct a holistic investigation into factors that enhance model robustness and show that incorporating a diversified set of voice augmentations is beneficial. Moreover, we find that the best detection models often rely on high-frequency features, which are imperceptible to humans and can be easily manipulated by an attacker. To address this, we propose the F-SAT: Frequency-Selective Adversarial Training method focusing on high-frequency components. Empirical results demonstrate that using our training dataset boosts baseline model performance (without robust training) by 33%, and our robust training further improves accuracy by 7.7% on clean samples and by 29.3% on corrupted and attacked samples, over the state-of-the-art RawNet3 model.
BA-Net: Bridge Attention in Deep Neural Networks
Oct 10, 2024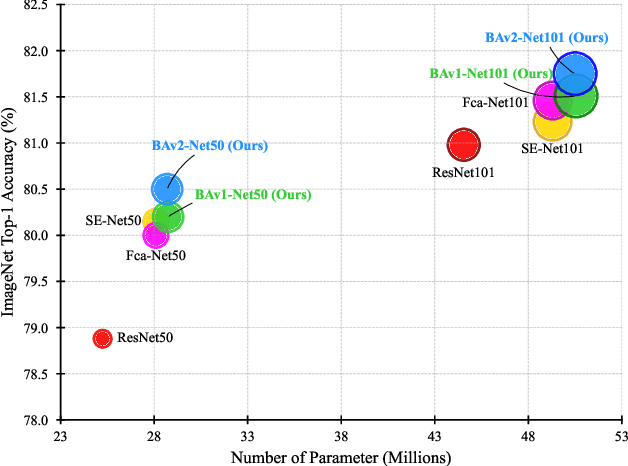
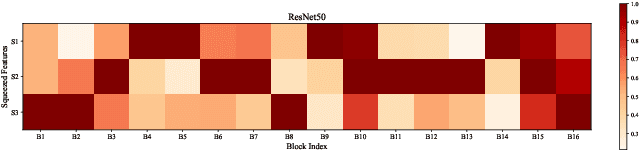
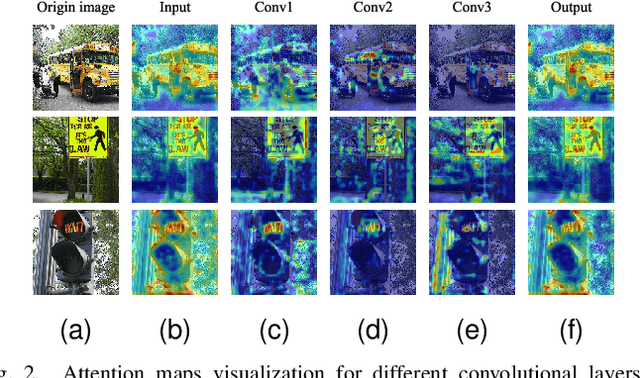
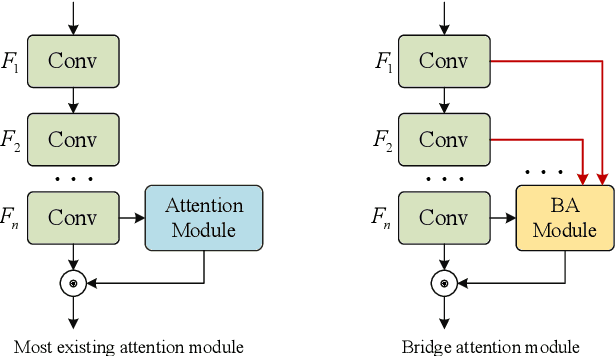
Attention mechanisms, particularly channel attention, have become highly influential in numerous computer vision tasks. Despite their effectiveness, many existing methods primarily focus on optimizing performance through complex attention modules applied at individual convolutional layers, often overlooking the synergistic interactions that can occur across multiple layers. In response to this gap, we introduce bridge attention, a novel approach designed to facilitate more effective integration and information flow between different convolutional layers. Our work extends the original bridge attention model (BAv1) by introducing an adaptive selection operator, which reduces information redundancy and optimizes the overall information exchange. This enhancement results in the development of BAv2, which achieves substantial performance improvements in the ImageNet classification task, obtaining Top-1 accuracies of 80.49% and 81.75% when using ResNet50 and ResNet101 as backbone networks, respectively. These results surpass the retrained baselines by 1.61% and 0.77%, respectively. Furthermore, BAv2 outperforms other existing channel attention techniques, such as the classical SENet101, exceeding its retrained performance by 0.52% Additionally, integrating BAv2 into advanced convolutional networks and vision transformers has led to significant gains in performance across a wide range of computer vision tasks, underscoring its broad applicability.
DSDFormer: An Innovative Transformer-Mamba Framework for Robust High-Precision Driver Distraction Identification
Sep 09, 2024



Driver distraction remains a leading cause of traffic accidents, posing a critical threat to road safety globally. As intelligent transportation systems evolve, accurate and real-time identification of driver distraction has become essential. However, existing methods struggle to capture both global contextual and fine-grained local features while contending with noisy labels in training datasets. To address these challenges, we propose DSDFormer, a novel framework that integrates the strengths of Transformer and Mamba architectures through a Dual State Domain Attention (DSDA) mechanism, enabling a balance between long-range dependencies and detailed feature extraction for robust driver behavior recognition. Additionally, we introduce Temporal Reasoning Confident Learning (TRCL), an unsupervised approach that refines noisy labels by leveraging spatiotemporal correlations in video sequences. Our model achieves state-of-the-art performance on the AUC-V1, AUC-V2, and 100-Driver datasets and demonstrates real-time processing efficiency on the NVIDIA Jetson AGX Orin platform. Extensive experimental results confirm that DSDFormer and TRCL significantly improve both the accuracy and robustness of driver distraction detection, offering a scalable solution to enhance road safety.
BA-Net: Bridge Attention for Deep Convolutional Neural Networks
Dec 08, 2021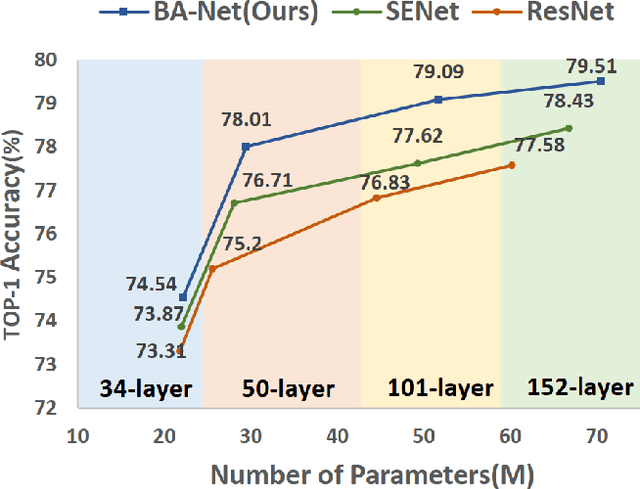
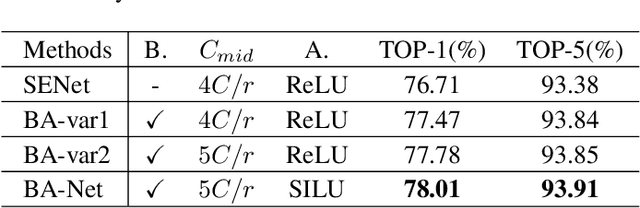
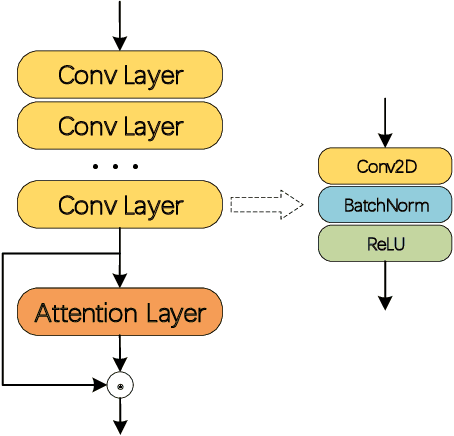

In recent years, channel attention mechanism is widely investigated for its great potential in improving the performance of deep convolutional neural networks (CNNs). However, in most existing methods, only the output of the adjacent convolution layer is fed to the attention layer for calculating the channel weights. Information from other convolution layers is ignored. With these observations, a simple strategy, named Bridge Attention Net (BA-Net), is proposed for better channel attention mechanisms. The main idea of this design is to bridge the outputs of the previous convolution layers through skip connections for channel weights generation. BA-Net can not only provide richer features to calculate channel weight when feedforward, but also multiply paths of parameters updating when backforward. Comprehensive evaluation demonstrates that the proposed approach achieves state-of-the-art performance compared with the existing methods in regards to accuracy and speed. Bridge Attention provides a fresh perspective on the design of neural network architectures and shows great potential in improving the performance of the existing channel attention mechanisms. The code is available at \url{https://github.com/zhaoy376/Attention-mechanism
VTBR: Semantic-based Pretraining for Person Re-Identification
Oct 11, 2021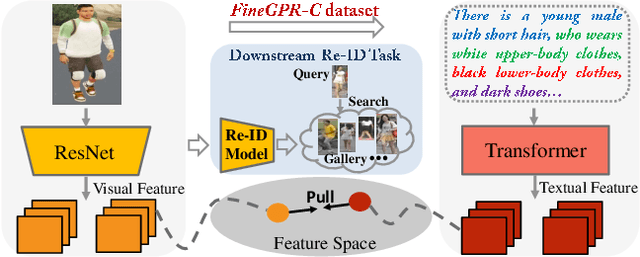

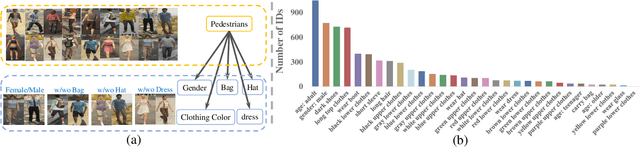

Pretraining is a dominant paradigm in computer vision. Generally, supervised ImageNet pretraining is commonly used to initialize the backbones of person re-identification (Re-ID) models. However, recent works show a surprising result that ImageNet pretraining has limited impacts on Re-ID system due to the large domain gap between ImageNet and person Re-ID data. To seek an alternative to traditional pretraining, we manually construct a diversified FineGPR-C caption dataset for the first time on person Re-ID events. Based on it, we propose a pure semantic-based pretraining approach named VTBR, which uses dense captions to learn visual representations with fewer images. Specifically, we train convolutional networks from scratch on the captions of FineGPR-C dataset, and transfer them to downstream Re-ID tasks. Comprehensive experiments conducted on benchmarks show that our VTBR can achieve competitive performance compared with ImageNet pretraining -- despite using up to 1.4x fewer images, revealing its potential in Re-ID pretraining.