 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeI Can Hear You: Selective Robust Training for Deepfake Audio Detection
Paper and Code
Oct 31, 2024


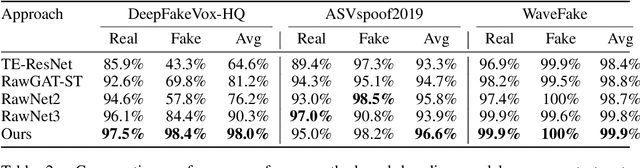
Recent advances in AI-generated voices have intensified the challenge of detecting deepfake audio, posing risks for scams and the spread of disinformation. To tackle this issue, we establish the largest public voice dataset to date, named DeepFakeVox-HQ, comprising 1.3 million samples, including 270,000 high-quality deepfake samples from 14 diverse sources. Despite previously reported high accuracy, existing deepfake voice detectors struggle with our diversely collected dataset, and their detection success rates drop even further under realistic corruptions and adversarial attacks. We conduct a holistic investigation into factors that enhance model robustness and show that incorporating a diversified set of voice augmentations is beneficial. Moreover, we find that the best detection models often rely on high-frequency features, which are imperceptible to humans and can be easily manipulated by an attacker. To address this, we propose the F-SAT: Frequency-Selective Adversarial Training method focusing on high-frequency components. Empirical results demonstrate that using our training dataset boosts baseline model performance (without robust training) by 33%, and our robust training further improves accuracy by 7.7% on clean samples and by 29.3% on corrupted and attacked samples, over the state-of-the-art RawNet3 model.