 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVTBR: Semantic-based Pretraining for Person Re-Identification
Oct 11, 2021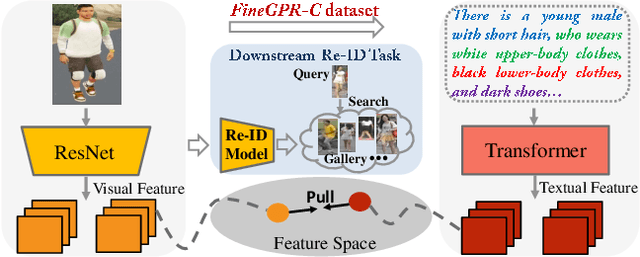

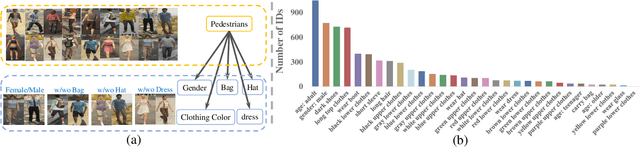

Pretraining is a dominant paradigm in computer vision. Generally, supervised ImageNet pretraining is commonly used to initialize the backbones of person re-identification (Re-ID) models. However, recent works show a surprising result that ImageNet pretraining has limited impacts on Re-ID system due to the large domain gap between ImageNet and person Re-ID data. To seek an alternative to traditional pretraining, we manually construct a diversified FineGPR-C caption dataset for the first time on person Re-ID events. Based on it, we propose a pure semantic-based pretraining approach named VTBR, which uses dense captions to learn visual representations with fewer images. Specifically, we train convolutional networks from scratch on the captions of FineGPR-C dataset, and transfer them to downstream Re-ID tasks. Comprehensive experiments conducted on benchmarks show that our VTBR can achieve competitive performance compared with ImageNet pretraining -- despite using up to 1.4x fewer images, revealing its potential in Re-ID pretraining.