 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Robust Visual-Semantic Embedding for Generalizable Person Re-identification
Apr 19, 2023
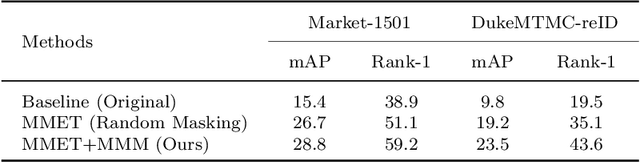


Generalizable person re-identification (Re-ID) is a very hot research topic in machine learning and computer vision, which plays a significant role in realistic scenarios due to its various applications in public security and video surveillance. However, previous methods mainly focus on the visual representation learning, while neglect to explore the potential of semantic features during training, which easily leads to poor generalization capability when adapted to the new domain. In this paper, we propose a Multi-Modal Equivalent Transformer called MMET for more robust visual-semantic embedding learning on visual, textual and visual-textual tasks respectively. To further enhance the robust feature learning in the context of transformer, a dynamic masking mechanism called Masked Multimodal Modeling strategy (MMM) is introduced to mask both the image patches and the text tokens, which can jointly works on multimodal or unimodal data and significantly boost the performance of generalizable person Re-ID. Extensive experiments on benchmark datasets demonstrate the competitive performance of our method over previous approaches. We hope this method could advance the research towards visual-semantic representation learning. Our source code is also publicly available at https://github.com/JeremyXSC/MMET.
VTBR: Semantic-based Pretraining for Person Re-Identification
Oct 11, 2021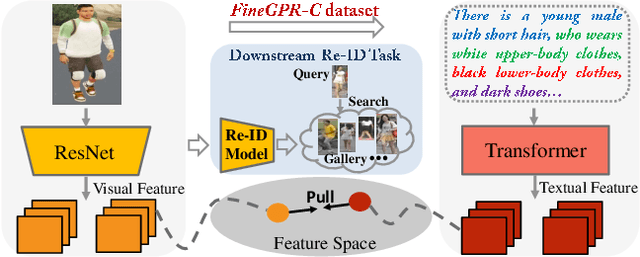


Pretraining is a dominant paradigm in computer vision. Generally, supervised ImageNet pretraining is commonly used to initialize the backbones of person re-identification (Re-ID) models. However, recent works show a surprising result that ImageNet pretraining has limited impacts on Re-ID system due to the large domain gap between ImageNet and person Re-ID data. To seek an alternative to traditional pretraining, we manually construct a diversified FineGPR-C caption dataset for the first time on person Re-ID events. Based on it, we propose a pure semantic-based pretraining approach named VTBR, which uses dense captions to learn visual representations with fewer images. Specifically, we train convolutional networks from scratch on the captions of FineGPR-C dataset, and transfer them to downstream Re-ID tasks. Comprehensive experiments conducted on benchmarks show that our VTBR can achieve competitive performance compared with ImageNet pretraining -- despite using up to 1.4x fewer images, revealing its potential in Re-ID pretraining.
Less is More: Learning from Synthetic Data with Fine-grained Attributes for Person Re-Identification
Sep 22, 2021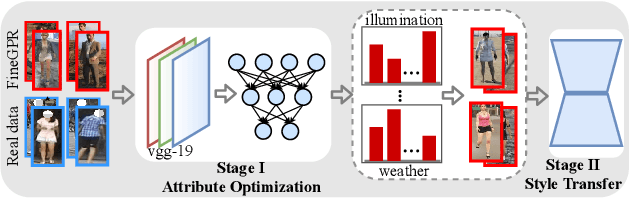



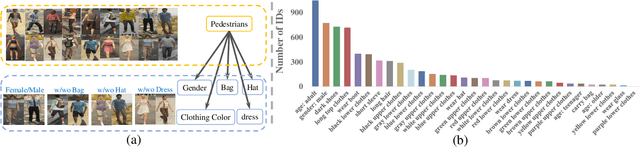
Person re-identification (re-ID) plays an important role in applications such as public security and video surveillance. Recently, learning from synthetic data, which benefits from the popularity of synthetic data engine, has attracted attention from both academia and the public eye. However, existing synthetic datasets are limited in quantity, diversity and realisticity, and cannot be efficiently used for generalizable re-ID problem. To address this challenge, we construct and label a large-scale synthetic person dataset named FineGPR with fine-grained attribute distribution. Moreover, aiming to fully exploit the potential of FineGPR and promote the efficient training from millions of synthetic data, we propose an attribute analysis pipeline AOST to learn attribute distribution in target domain, then apply style transfer network to eliminate the gap between synthetic and real-world data and thus is freely deployed to new scenarios. Experiments conducted on benchmarks demonstrate that FineGPR with AOST outperforms (or is on par with) existing real and synthetic datasets, which suggests its feasibility for re-ID and proves the proverbial less-is-more principle. We hope this fine-grained dataset could advance research towards re-ID in real scenarios.
Learning from Self-Discrepancy via Multiple Co-teaching for Cross-Domain Person Re-Identification
Apr 06, 2021



Employing clustering strategy to assign unlabeled target images with pseudo labels has become a trend for person re-identification (re-ID) algorithms in domain adaptation. A potential limitation of these clustering-based methods is that they always tend to introduce noisy labels, which will undoubtedly hamper the performance of our re-ID system. To handle this limitation, an intuitive solution is to utilize collaborative training to purify the pseudo label quality. However, there exists a challenge that the complementarity of two networks, which inevitably share a high similarity, becomes weakened gradually as training process goes on; worse still, these approaches typically ignore to consider the self-discrepancy of intra-class relations. To address this issue, in this letter, we propose a multiple co-teaching framework for domain adaptive person re-ID, opening up a promising direction about self-discrepancy problem under unsupervised condition. On top of that, a mean-teaching mechanism is leveraged to enlarge the difference and discover more complementary features. Comprehensive experiments conducted on several large-scale datasets show that our method achieves competitive performance compared with the state-of-the-arts.