 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLess is More: Learning from Synthetic Data with Fine-grained Attributes for Person Re-Identification
Sep 22, 2021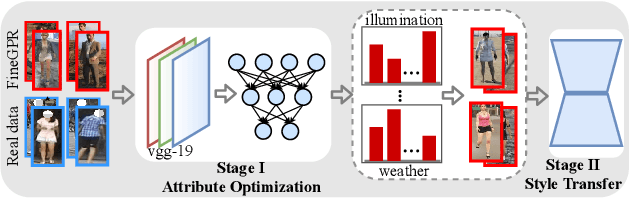



Person re-identification (re-ID) plays an important role in applications such as public security and video surveillance. Recently, learning from synthetic data, which benefits from the popularity of synthetic data engine, has attracted attention from both academia and the public eye. However, existing synthetic datasets are limited in quantity, diversity and realisticity, and cannot be efficiently used for generalizable re-ID problem. To address this challenge, we construct and label a large-scale synthetic person dataset named FineGPR with fine-grained attribute distribution. Moreover, aiming to fully exploit the potential of FineGPR and promote the efficient training from millions of synthetic data, we propose an attribute analysis pipeline AOST to learn attribute distribution in target domain, then apply style transfer network to eliminate the gap between synthetic and real-world data and thus is freely deployed to new scenarios. Experiments conducted on benchmarks demonstrate that FineGPR with AOST outperforms (or is on par with) existing real and synthetic datasets, which suggests its feasibility for re-ID and proves the proverbial less-is-more principle. We hope this fine-grained dataset could advance research towards re-ID in real scenarios.
Taking A Closer Look at Synthesis: Fine-grained Attribute Analysis for Person Re-Identification
Oct 29, 2020



Person re-identification (re-ID) plays an important role in applications such as public security and video surveillance. Recently, learning from synthetic data, which benefits from the popularity of synthetic data engine, has achieved remarkable performance. However, in pursuit of high accuracy, researchers in the academic always focus on training with large-scale datasets at a high cost of time and label expenses, while neglect to explore the potential of performing efficient training from millions of synthetic data. To facilitate development in this field, we reviewed the previously developed synthetic dataset GPR and built an improved one (GPR+) with larger number of identities and distinguished attributes. Based on it, we quantitatively analyze the influence of dataset attribute on re-ID system. To our best knowledge, we are among the first attempts to explicitly dissect person re-ID from the aspect of attribute on synthetic dataset. This research helps us have a deeper understanding of the fundamental problems in person re-ID, which also provides useful insights for dataset building and future practical usage.
Attribute analysis with synthetic dataset for person re-identification
Jun 12, 2020



Person re-identification (re-ID) plays an important role in applications such as public security and video surveillance. Recently, learning from synthetic data, which benefits from the popularity of synthetic data engine, have achieved remarkable performance. However, existing synthetic datasets are in small size and lack of diversity, which hinders the development of person re-ID in real-world scenarios. To address this problem, firstly, we develop a large-scale synthetic data engine, the salient characteristic of this engine is controllable. Based on it, we build a large-scale synthetic dataset, which are diversified and customized from different attributes, such as illumination and viewpoint. Secondly, we quantitatively analyze the influence of dataset attributes on re-ID system. To our best knowledge, this is the first attempt to explicitly dissect person re-ID from the aspect of attribute on synthetic dataset. Comprehensive experiments help us have a deeper understanding of the fundamental problems in person re-ID. Our research also provides useful insights for dataset building and future practical usage.