 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Robust Visual-Semantic Embedding for Generalizable Person Re-identification
Paper and Code

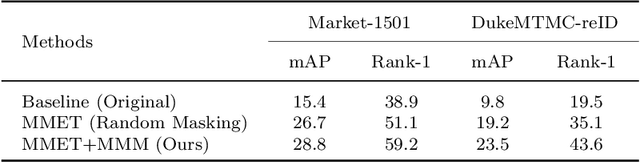


Generalizable person re-identification (Re-ID) is a very hot research topic in machine learning and computer vision, which plays a significant role in realistic scenarios due to its various applications in public security and video surveillance. However, previous methods mainly focus on the visual representation learning, while neglect to explore the potential of semantic features during training, which easily leads to poor generalization capability when adapted to the new domain. In this paper, we propose a Multi-Modal Equivalent Transformer called MMET for more robust visual-semantic embedding learning on visual, textual and visual-textual tasks respectively. To further enhance the robust feature learning in the context of transformer, a dynamic masking mechanism called Masked Multimodal Modeling strategy (MMM) is introduced to mask both the image patches and the text tokens, which can jointly works on multimodal or unimodal data and significantly boost the performance of generalizable person Re-ID. Extensive experiments on benchmark datasets demonstrate the competitive performance of our method over previous approaches. We hope this method could advance the research towards visual-semantic representation learning. Our source code is also publicly available at https://github.com/JeremyXSC/MMET.