 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMedGEN-Bench: Contextually entangled benchmark for open-ended multimodal medical generation
Nov 18, 2025As Vision-Language Models (VLMs) increasingly gain traction in medical applications, clinicians are progressively expecting AI systems not only to generate textual diagnoses but also to produce corresponding medical images that integrate seamlessly into authentic clinical workflows. Despite the growing interest, existing medical visual benchmarks present notable limitations. They often rely on ambiguous queries that lack sufficient relevance to image content, oversimplify complex diagnostic reasoning into closed-ended shortcuts, and adopt a text-centric evaluation paradigm that overlooks the importance of image generation capabilities. To address these challenges, we introduce MedGEN-Bench, a comprehensive multimodal benchmark designed to advance medical AI research. MedGEN-Bench comprises 6,422 expert-validated image-text pairs spanning six imaging modalities, 16 clinical tasks, and 28 subtasks. It is structured into three distinct formats: Visual Question Answering, Image Editing, and Contextual Multimodal Generation. What sets MedGEN-Bench apart is its focus on contextually intertwined instructions that necessitate sophisticated cross-modal reasoning and open-ended generative outputs, moving beyond the constraints of multiple-choice formats. To evaluate the performance of existing systems, we employ a novel three-tier assessment framework that integrates pixel-level metrics, semantic text analysis, and expert-guided clinical relevance scoring. Using this framework, we systematically assess 10 compositional frameworks, 3 unified models, and 5 VLMs.
VrdONE: One-stage Video Visual Relation Detection
Aug 18, 2024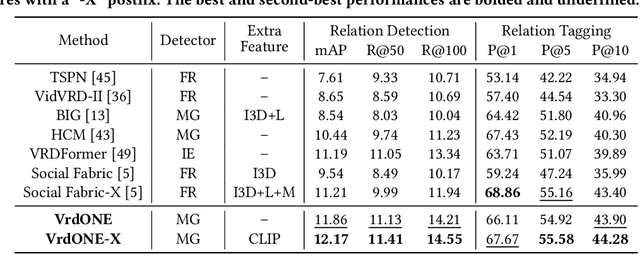

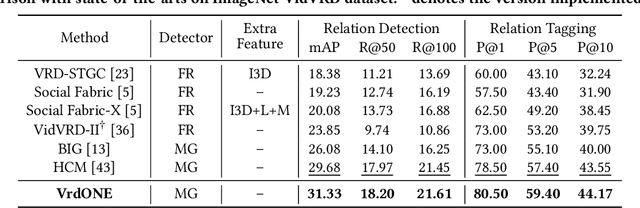

Video Visual Relation Detection (VidVRD) focuses on understanding how entities interact over time and space in videos, a key step for gaining deeper insights into video scenes beyond basic visual tasks. Traditional methods for VidVRD, challenged by its complexity, typically split the task into two parts: one for identifying what relation categories are present and another for determining their temporal boundaries. This split overlooks the inherent connection between these elements. Addressing the need to recognize entity pairs' spatiotemporal interactions across a range of durations, we propose VrdONE, a streamlined yet efficacious one-stage model. VrdONE combines the features of subjects and objects, turning predicate detection into 1D instance segmentation on their combined representations. This setup allows for both relation category identification and binary mask generation in one go, eliminating the need for extra steps like proposal generation or post-processing. VrdONE facilitates the interaction of features across various frames, adeptly capturing both short-lived and enduring relations. Additionally, we introduce the Subject-Object Synergy (SOS) module, enhancing how subjects and objects perceive each other before combining. VrdONE achieves state-of-the-art performances on the VidOR benchmark and ImageNet-VidVRD, showcasing its superior capability in discerning relations across different temporal scales. The code is available at \textcolor[RGB]{228,58,136}{\href{https://github.com/lucaspk512/vrdone}{https://github.com/lucaspk512/vrdone}}.