 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTurbo2K: Towards Ultra-Efficient and High-Quality 2K Video Synthesis
Apr 20, 2025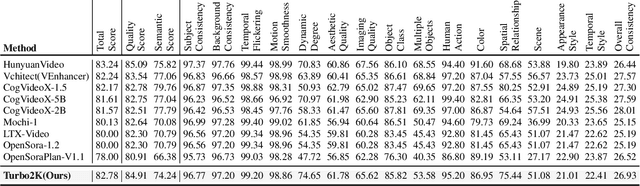

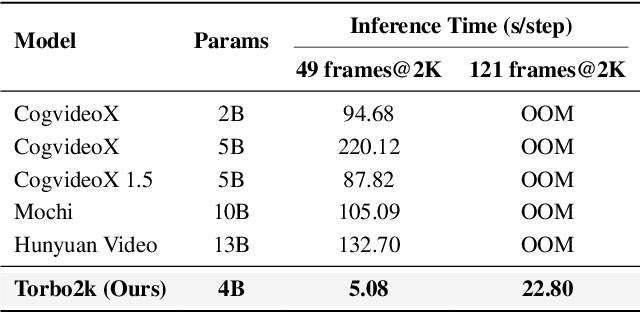

Demand for 2K video synthesis is rising with increasing consumer expectations for ultra-clear visuals. While diffusion transformers (DiTs) have demonstrated remarkable capabilities in high-quality video generation, scaling them to 2K resolution remains computationally prohibitive due to quadratic growth in memory and processing costs. In this work, we propose Turbo2K, an efficient and practical framework for generating detail-rich 2K videos while significantly improving training and inference efficiency. First, Turbo2K operates in a highly compressed latent space, reducing computational complexity and memory footprint, making high-resolution video synthesis feasible. However, the high compression ratio of the VAE and limited model size impose constraints on generative quality. To mitigate this, we introduce a knowledge distillation strategy that enables a smaller student model to inherit the generative capacity of a larger, more powerful teacher model. Our analysis reveals that, despite differences in latent spaces and architectures, DiTs exhibit structural similarities in their internal representations, facilitating effective knowledge transfer. Second, we design a hierarchical two-stage synthesis framework that first generates multi-level feature at lower resolutions before guiding high-resolution video generation. This approach ensures structural coherence and fine-grained detail refinement while eliminating redundant encoding-decoding overhead, further enhancing computational efficiency.Turbo2K achieves state-of-the-art efficiency, generating 5-second, 24fps, 2K videos with significantly reduced computational cost. Compared to existing methods, Turbo2K is up to 20$\times$ faster for inference, making high-resolution video generation more scalable and practical for real-world applications.
RecDreamer: Consistent Text-to-3D Generation via Uniform Score Distillation
Feb 18, 2025Current text-to-3D generation methods based on score distillation often suffer from geometric inconsistencies, leading to repeated patterns across different poses of 3D assets. This issue, known as the Multi-Face Janus problem, arises because existing methods struggle to maintain consistency across varying poses and are biased toward a canonical pose. While recent work has improved pose control and approximation, these efforts are still limited by this inherent bias, which skews the guidance during generation. To address this, we propose a solution called RecDreamer, which reshapes the underlying data distribution to achieve a more consistent pose representation. The core idea behind our method is to rectify the prior distribution, ensuring that pose variation is uniformly distributed rather than biased toward a canonical form. By modifying the prescribed distribution through an auxiliary function, we can reconstruct the density of the distribution to ensure compliance with specific marginal constraints. In particular, we ensure that the marginal distribution of poses follows a uniform distribution, thereby eliminating the biases introduced by the prior knowledge. We incorporate this rectified data distribution into existing score distillation algorithms, a process we refer to as uniform score distillation. To efficiently compute the posterior distribution required for the auxiliary function, RecDreamer introduces a training-free classifier that estimates pose categories in a plug-and-play manner. Additionally, we utilize various approximation techniques for noisy states, significantly improving system performance. Our experimental results demonstrate that RecDreamer effectively mitigates the Multi-Face Janus problem, leading to more consistent 3D asset generation across different poses.
Rotation-Adaptive Point Cloud Domain Generalization via Intricate Orientation Learning
Feb 04, 2025



The vulnerability of 3D point cloud analysis to unpredictable rotations poses an open yet challenging problem: orientation-aware 3D domain generalization. Cross-domain robustness and adaptability of 3D representations are crucial but not easily achieved through rotation augmentation. Motivated by the inherent advantages of intricate orientations in enhancing generalizability, we propose an innovative rotation-adaptive domain generalization framework for 3D point cloud analysis. Our approach aims to alleviate orientational shifts by leveraging intricate samples in an iterative learning process. Specifically, we identify the most challenging rotation for each point cloud and construct an intricate orientation set by optimizing intricate orientations. Subsequently, we employ an orientation-aware contrastive learning framework that incorporates an orientation consistency loss and a margin separation loss, enabling effective learning of categorically discriminative and generalizable features with rotation consistency. Extensive experiments and ablations conducted on 3D cross-domain benchmarks firmly establish the state-of-the-art performance of our proposed approach in the context of orientation-aware 3D domain generalization.
VrdONE: One-stage Video Visual Relation Detection
Aug 18, 2024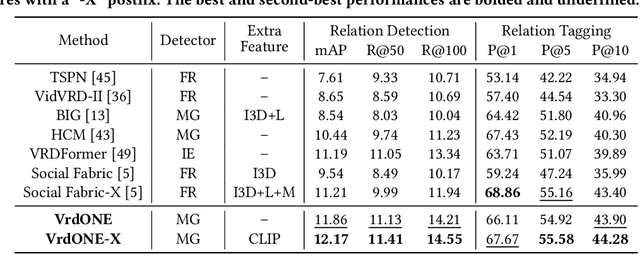

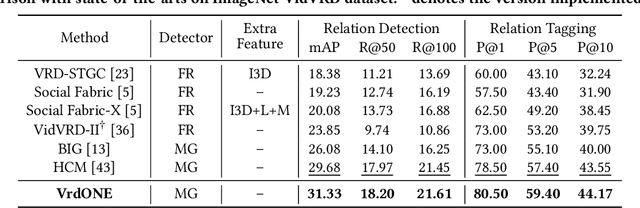

Video Visual Relation Detection (VidVRD) focuses on understanding how entities interact over time and space in videos, a key step for gaining deeper insights into video scenes beyond basic visual tasks. Traditional methods for VidVRD, challenged by its complexity, typically split the task into two parts: one for identifying what relation categories are present and another for determining their temporal boundaries. This split overlooks the inherent connection between these elements. Addressing the need to recognize entity pairs' spatiotemporal interactions across a range of durations, we propose VrdONE, a streamlined yet efficacious one-stage model. VrdONE combines the features of subjects and objects, turning predicate detection into 1D instance segmentation on their combined representations. This setup allows for both relation category identification and binary mask generation in one go, eliminating the need for extra steps like proposal generation or post-processing. VrdONE facilitates the interaction of features across various frames, adeptly capturing both short-lived and enduring relations. Additionally, we introduce the Subject-Object Synergy (SOS) module, enhancing how subjects and objects perceive each other before combining. VrdONE achieves state-of-the-art performances on the VidOR benchmark and ImageNet-VidVRD, showcasing its superior capability in discerning relations across different temporal scales. The code is available at \textcolor[RGB]{228,58,136}{\href{https://github.com/lucaspk512/vrdone}{https://github.com/lucaspk512/vrdone}}.
Learning with Unreliability: Fast Few-shot Voxel Radiance Fields with Relative Geometric Consistency
Mar 26, 2024We propose a voxel-based optimization framework, ReVoRF, for few-shot radiance fields that strategically address the unreliability in pseudo novel view synthesis. Our method pivots on the insight that relative depth relationships within neighboring regions are more reliable than the absolute color values in disoccluded areas. Consequently, we devise a bilateral geometric consistency loss that carefully navigates the trade-off between color fidelity and geometric accuracy in the context of depth consistency for uncertain regions. Moreover, we present a reliability-guided learning strategy to discern and utilize the variable quality across synthesized views, complemented by a reliability-aware voxel smoothing algorithm that smoothens the transition between reliable and unreliable data patches. Our approach allows for a more nuanced use of all available data, promoting enhanced learning from regions previously considered unsuitable for high-quality reconstruction. Extensive experiments across diverse datasets reveal that our approach attains significant gains in efficiency and accuracy, delivering rendering speeds of 3 FPS, 7 mins to train a $360^\circ$ scene, and a 5\% improvement in PSNR over existing few-shot methods. Code is available at https://github.com/HKCLynn/ReVoRF.