 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA procedure for automated tree pruning suggestion using LiDAR scans of fruit trees
Feb 07, 2021
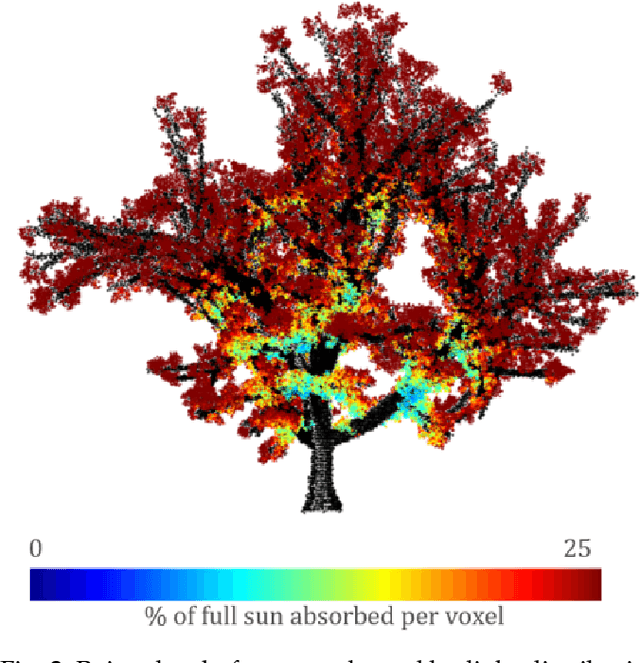
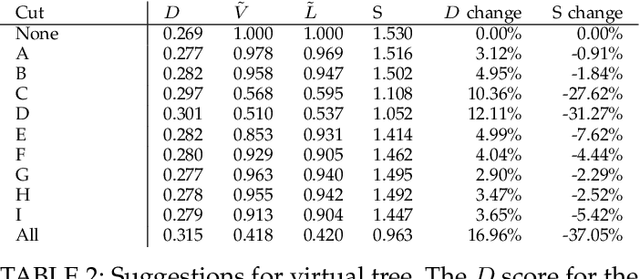
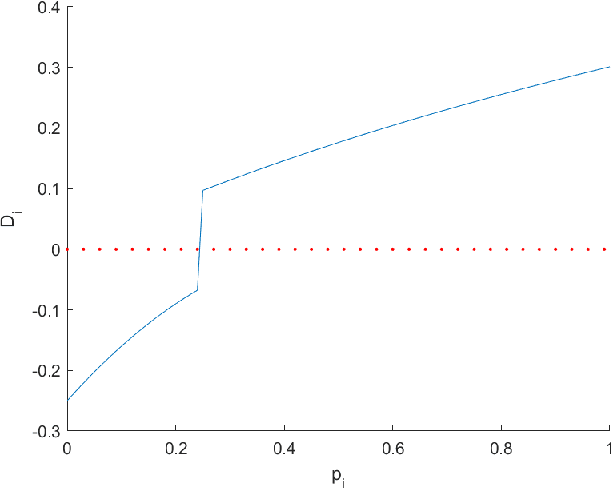
In fruit tree growth, pruning is an important management practice for preventing overcrowding, improving canopy access to light and promoting regrowth. Due to the slow nature of agriculture, decisions in pruning are typically made using tradition or rules of thumb rather than data-driven analysis. Many existing algorithmic, simulation-based approaches rely on high-fidelity digital captures or purely computer-generated fruit trees, and are unable to provide specific results on an orchard scale. We present a framework for suggesting pruning strategies on LiDAR-scanned commercial fruit trees using a scoring function with a focus on improving light distribution throughout the canopy. A scoring function to assess the quality of the tree shape based on its light availability and size was developed for comparative analysis between trees, and was validated against yield characteristics, demonstrating a reasonable correlation against fruit count with an $R^2$ score of 0.615 for avocado and 0.506 for mango. A tool was implemented for simulating pruning by algorithmically estimating which parts of a tree point cloud would be removed given specific cut points using structural analysis of the tree, validated experimentally with an average F1 score of 0.78 across 144 experiments. Finally, new pruning locations were suggested and we used the previous two stages to estimate the improvement of the tree given these suggestions. The light distribution was improved by up to 25.15\%, demonstrating a 16\% improvement over commercial pruning on a real tree, and certain cut points were discovered which improved light distribution with a smaller negative impact on tree volume. The final results suggest value in the framework as a decision making tool for commercial growers, or as a starting point for automated pruning since the entire process can be performed with little human intervention.
SimTreeLS: Simulating aerial and terrestrial laser scans of trees
Nov 24, 2020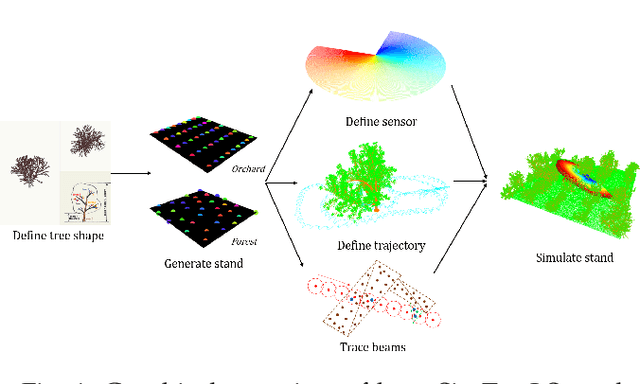

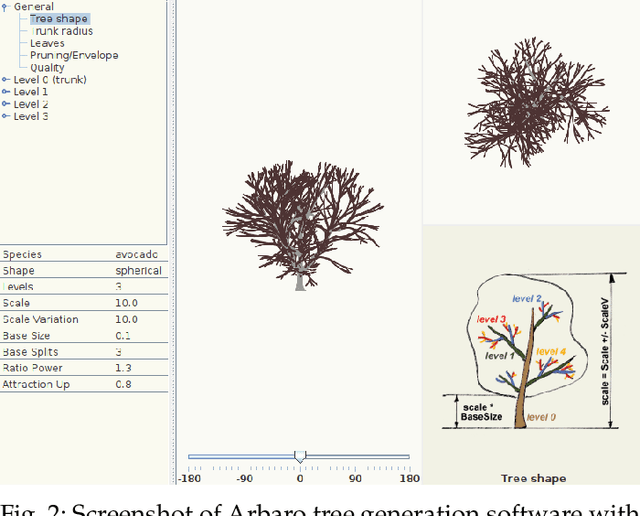
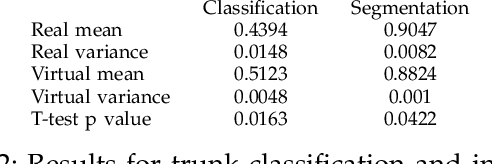
There are numerous emerging applications for digitizing trees using terrestrial and aerial laser scanning, particularly in the fields of agriculture and forestry. Interpretation of LiDAR point clouds is increasingly relying on data-driven methods (such as supervised machine learning) that rely on large quantities of hand-labelled data. As this data is potentially expensive to capture, and difficult to clearly visualise and label manually, a means of supplementing real LiDAR scans with simulated data is becoming a necessary step in realising the potential of these methods. We present an open source tool, SimTreeLS (Simulated Tree Laser Scans), for generating point clouds which simulate scanning with user-defined sensor, trajectory, tree shape and layout parameters. Upon simulation, material classification is kept in a pointwise fashion so leaf and woody matter are perfectly known, and unique identifiers separate individual trees, foregoing post-simulation labelling. This allows for an endless supply of procedurally generated data with similar characteristics to real LiDAR captures, which can then be used for development of data processing techniques or training of machine learning algorithms. To validate our method, we compare the characteristics of a simulated scan with a real scan using similar trees and the same sensor and trajectory parameters. Results suggest the simulated data is significantly more similar to real data than a sample-based control. We also demonstrate application of SimTreeLS on contexts beyond the real data available, simulating scans of new tree shapes, new trajectories and new layouts, with results presenting well. SimTreeLS is available as an open source resource built on publicly available libraries.
Monocular Camera Based Fruit Counting and Mapping with Semantic Data Association
Mar 18, 2019



We present a cheap, lightweight, and fast fruit counting pipeline that uses a single monocular camera. Our pipeline that relies only on a monocular camera, achieves counting performance comparable to state-of-the-art fruit counting system that utilizes an expensive sensor suite including LiDAR and GPS/INS on a mango dataset. Our monocular camera pipeline begins with a fruit detection component that uses a deep neural network. It then uses semantic structure from motion (SFM) to convert these detections into fruit counts by estimating landmark locations of the fruit in 3D, and using these landmarks to identify double counting scenarios. There are many benefits of developing a low cost and lightweight fruit counting system, including applicability to agriculture in developing countries, where monetary constraints or unstructured environments necessitate cheaper hardware solutions.
Multi-Modal Obstacle Detection in Unstructured Environments with Conditional Random Fields
Mar 13, 2019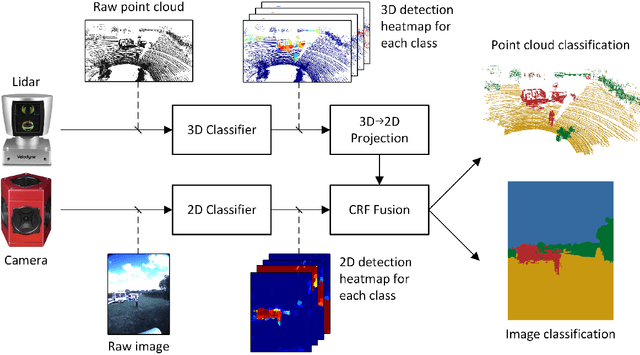
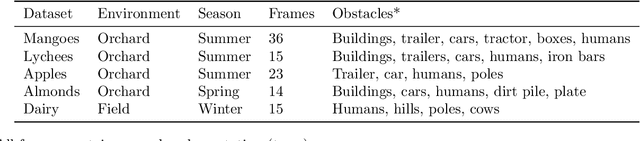
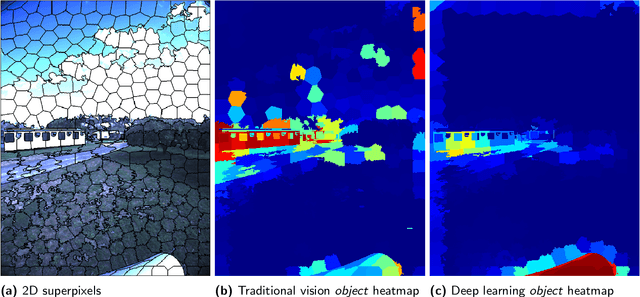
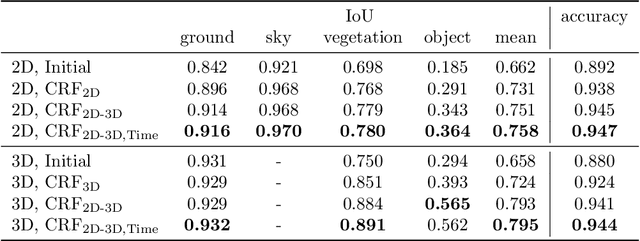
Reliable obstacle detection and classification in rough and unstructured terrain such as agricultural fields or orchards remains a challenging problem. These environments involve large variations in both geometry and appearance, challenging perception systems that rely on only a single sensor modality. Geometrically, tall grass, fallen leaves, or terrain roughness can mistakenly be perceived as nontraversable or might even obscure actual obstacles. Likewise, traversable grass or dirt roads and obstacles such as trees and bushes might be visually ambiguous. In this paper, we combine appearance- and geometry-based detection methods by probabilistically fusing lidar and camera sensing with semantic segmentation using a conditional random field. We apply a state-of-the-art multimodal fusion algorithm from the scene analysis domain and adjust it for obstacle detection in agriculture with moving ground vehicles. This involves explicitly handling sparse point cloud data and exploiting both spatial, temporal, and multimodal links between corresponding 2D and 3D regions. The proposed method was evaluated on a diverse data set, comprising a dairy paddock and different orchards gathered with a perception research robot in Australia. Results showed that for a two-class classification problem (ground and nonground), only the camera leveraged from information provided by the other modality with an increase in the mean classification score of 0.5%. However, as more classes were introduced (ground, sky, vegetation, and object), both modalities complemented each other with improvements of 1.4% in 2D and 7.9% in 3D. Finally, introducing temporal links between successive frames resulted in improvements of 0.2% in 2D and 1.5% in 3D.
Extrinsic Parameter Calibration for Line Scanning Cameras on Ground Vehicles with Navigation Systems Using a Calibration Pattern
Feb 12, 2018



Line scanning cameras, which capture only a single line of pixels, have been increasingly used in ground based mobile or robotic platforms. In applications where it is advantageous to directly georeference the camera data to world coordinates, an accurate estimate of the camera's 6D pose is required. This paper focuses on the common case where a mobile platform is equipped with a rigidly mounted line scanning camera, whose pose is unknown, and a navigation system providing vehicle body pose estimates. We propose a novel method that estimates the camera's pose relative to the navigation system. The approach involves imaging and manually labelling a calibration pattern with distinctly identifiable points, triangulating these points from camera and navigation system data and reprojecting them in order to compute a likelihood, which is maximised to estimate the 6D camera pose. Additionally, a Markov Chain Monte Carlo (MCMC) algorithm is used to estimate the uncertainty of the offset. Tested on two different platforms, the method was able to estimate the pose to within 0.06 m / 1.05$^{\circ}$ and 0.18 m / 2.39$^{\circ}$. We also propose several approaches to displaying and interpreting the 6D results in a human readable way.
* Published in MDPI Sensors, 30 October 2017
Deep Fruit Detection in Orchards
Sep 18, 2017
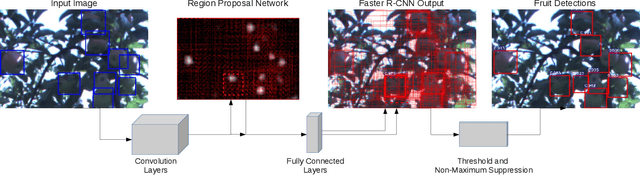
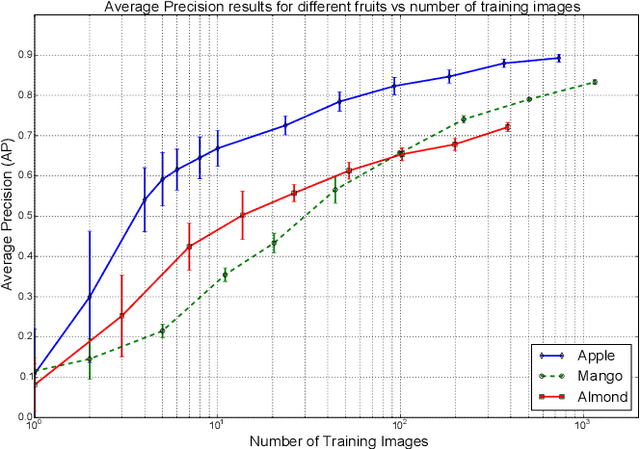
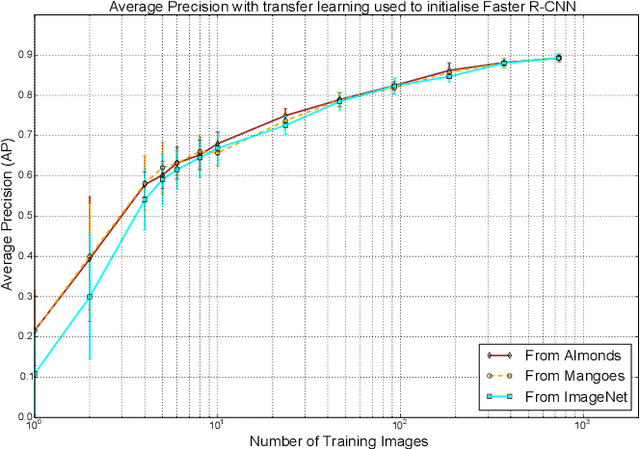
An accurate and reliable image based fruit detection system is critical for supporting higher level agriculture tasks such as yield mapping and robotic harvesting. This paper presents the use of a state-of-the-art object detection framework, Faster R-CNN, in the context of fruit detection in orchards, including mangoes, almonds and apples. Ablation studies are presented to better understand the practical deployment of the detection network, including how much training data is required to capture variability in the dataset. Data augmentation techniques are shown to yield significant performance gains, resulting in a greater than two-fold reduction in the number of training images required. In contrast, transferring knowledge between orchards contributed to negligible performance gain over initialising the Deep Convolutional Neural Network directly from ImageNet features. Finally, to operate over orchard data containing between 100-1000 fruit per image, a tiling approach is introduced for the Faster R-CNN framework. The study has resulted in the best yet detection performance for these orchards relative to previous works, with an F1-score of >0.9 achieved for apples and mangoes.
Image Segmentation for Fruit Detection and Yield Estimation in Apple Orchards
Oct 25, 2016
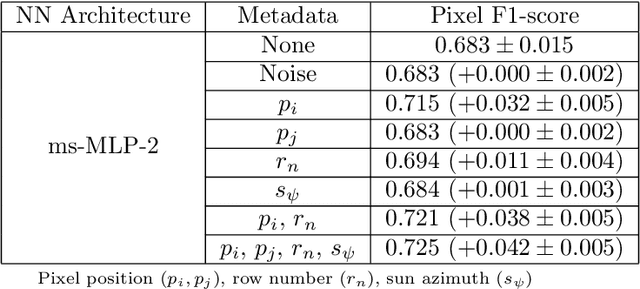


Ground vehicles equipped with monocular vision systems are a valuable source of high resolution image data for precision agriculture applications in orchards. This paper presents an image processing framework for fruit detection and counting using orchard image data. A general purpose image segmentation approach is used, including two feature learning algorithms; multi-scale Multi-Layered Perceptrons (MLP) and Convolutional Neural Networks (CNN). These networks were extended by including contextual information about how the image data was captured (metadata), which correlates with some of the appearance variations and/or class distributions observed in the data. The pixel-wise fruit segmentation output is processed using the Watershed Segmentation (WS) and Circular Hough Transform (CHT) algorithms to detect and count individual fruits. Experiments were conducted in a commercial apple orchard near Melbourne, Australia. The results show an improvement in fruit segmentation performance with the inclusion of metadata on the previously benchmarked MLP network. We extend this work with CNNs, bringing agrovision closer to the state-of-the-art in computer vision, where although metadata had negligible influence, the best pixel-wise F1-score of $0.791$ was achieved. The WS algorithm produced the best apple detection and counting results, with a detection F1-score of $0.858$. As a final step, image fruit counts were accumulated over multiple rows at the orchard and compared against the post-harvest fruit counts that were obtained from a grading and counting machine. The count estimates using CNN and WS resulted in the best performance for this dataset, with a squared correlation coefficient of $r^2=0.826$.