 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenAI o1 System Card
Dec 21, 2024



The o1 model series is trained with large-scale reinforcement learning to reason using chain of thought. These advanced reasoning capabilities provide new avenues for improving the safety and robustness of our models. In particular, our models can reason about our safety policies in context when responding to potentially unsafe prompts, through deliberative alignment. This leads to state-of-the-art performance on certain benchmarks for risks such as generating illicit advice, choosing stereotyped responses, and succumbing to known jailbreaks. Training models to incorporate a chain of thought before answering has the potential to unlock substantial benefits, while also increasing potential risks that stem from heightened intelligence. Our results underscore the need for building robust alignment methods, extensively stress-testing their efficacy, and maintaining meticulous risk management protocols. This report outlines the safety work carried out for the OpenAI o1 and OpenAI o1-mini models, including safety evaluations, external red teaming, and Preparedness Framework evaluations.
A real-time spatiotemporal AI model analyzes skill in open surgical videos
Dec 14, 2021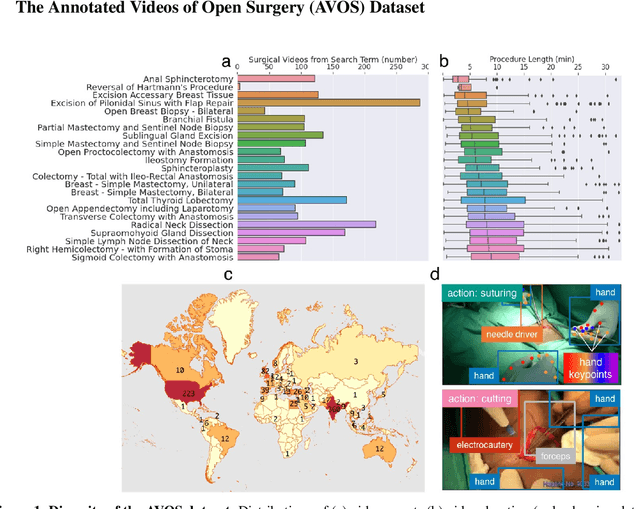
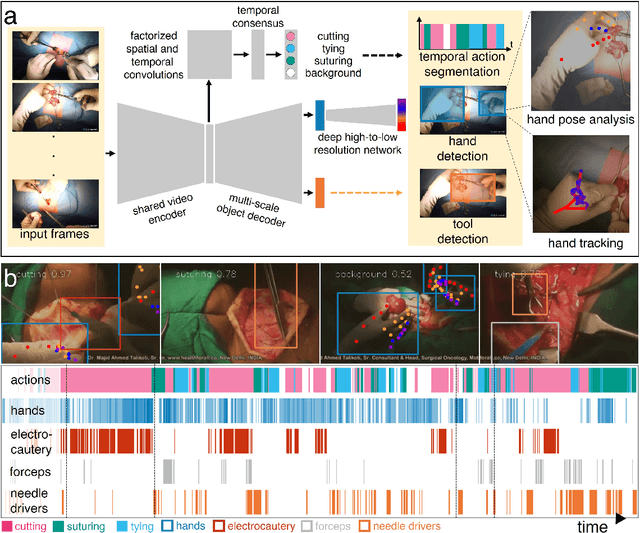
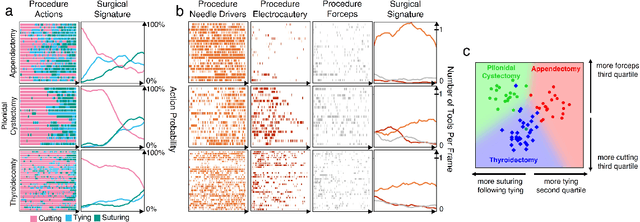
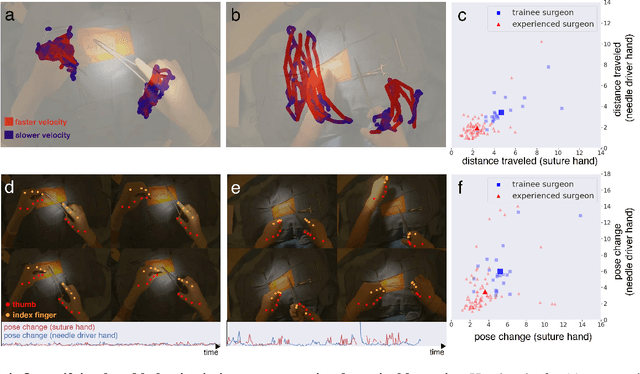
Open procedures represent the dominant form of surgery worldwide. Artificial intelligence (AI) has the potential to optimize surgical practice and improve patient outcomes, but efforts have focused primarily on minimally invasive techniques. Our work overcomes existing data limitations for training AI models by curating, from YouTube, the largest dataset of open surgical videos to date: 1997 videos from 23 surgical procedures uploaded from 50 countries. Using this dataset, we developed a multi-task AI model capable of real-time understanding of surgical behaviors, hands, and tools - the building blocks of procedural flow and surgeon skill. We show that our model generalizes across diverse surgery types and environments. Illustrating this generalizability, we directly applied our YouTube-trained model to analyze open surgeries prospectively collected at an academic medical center and identified kinematic descriptors of surgical skill related to efficiency of hand motion. Our Annotated Videos of Open Surgery (AVOS) dataset and trained model will be made available for further development of surgical AI.
Making AI Forget You: Data Deletion in Machine Learning
Jul 11, 2019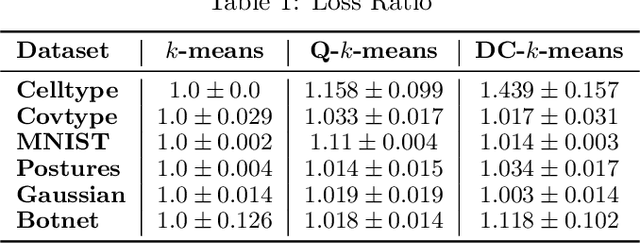
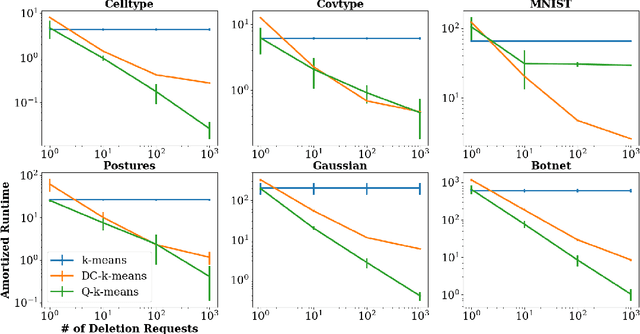
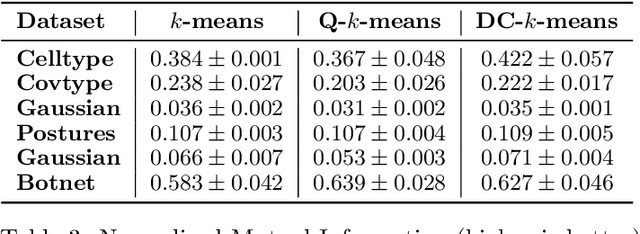
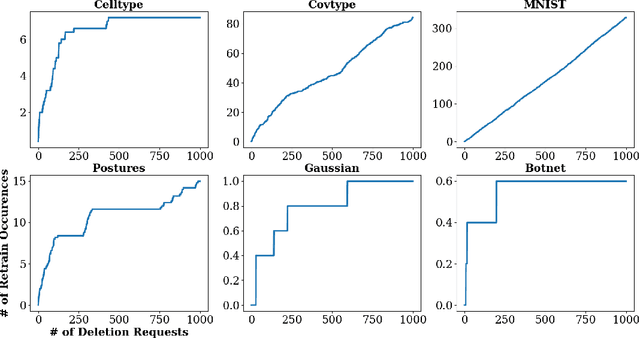
Intense recent discussions have focused on how to provide individuals with control over when their data can and cannot be used -- the EU's Right To Be Forgotten regulation is an example of this effort. In this paper we initiate a framework studying what to do when it is no longer permissible to deploy models derivative from specific user data. In particular, we formulate the problem of how to efficiently delete individual data points from trained machine learning models. For many standard ML models, the only way to completely remove an individual's data is to retrain the whole model from scratch on the remaining data, which is often not computationally practical. We investigate algorithmic principles that enable efficient data deletion in ML. For the specific setting of k-means clustering, we propose two provably deletion efficient algorithms which achieve an average of over 100X improvement in deletion efficiency across 6 datasets, while producing clusters of comparable statistical quality to a canonical k-means++ baseline.