 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompetition over data: how does data purchase affect users?
Jan 26, 2022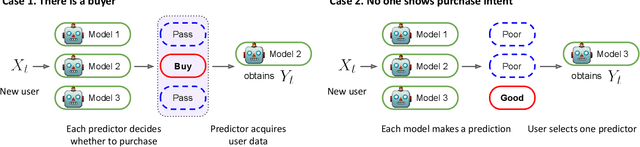
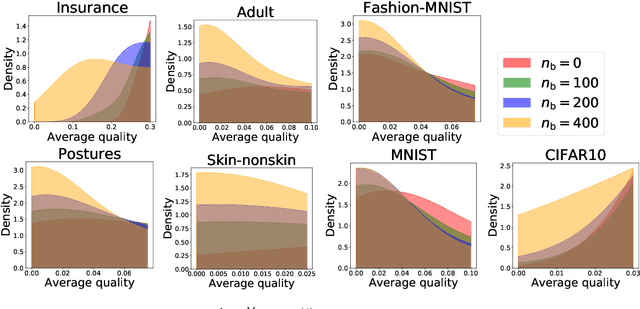
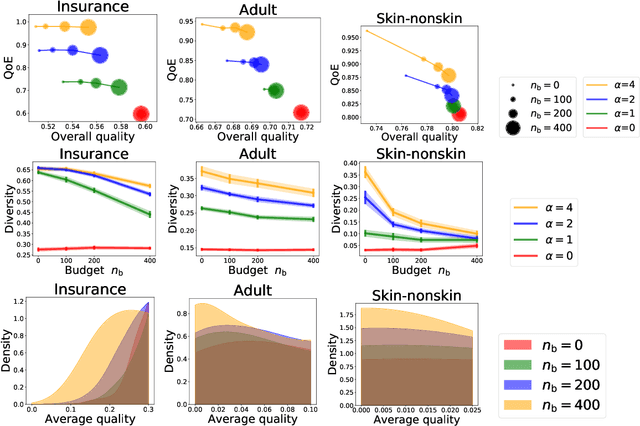
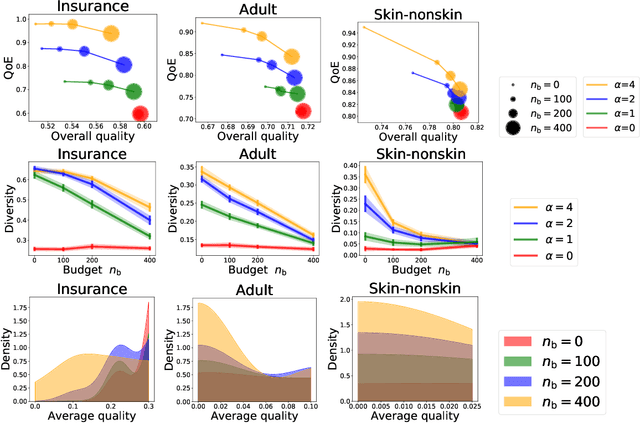
As machine learning (ML) is deployed by many competing service providers, the underlying ML predictors also compete against each other, and it is increasingly important to understand the impacts and biases from such competition. In this paper, we study what happens when the competing predictors can acquire additional labeled data to improve their prediction quality. We introduce a new environment that allows ML predictors to use active learning algorithms to purchase labeled data within their budgets while competing against each other to attract users. Our environment models a critical aspect of data acquisition in competing systems which has not been well-studied before. We found that the overall performance of an ML predictor improves when predictors can purchase additional labeled data. Surprisingly, however, the quality that users experience -- i.e. the accuracy of the predictor selected by each user -- can decrease even as the individual predictors get better. We show that this phenomenon naturally arises due to a trade-off whereby competition pushes each predictor to specialize in a subset of the population while data purchase has the effect of making predictors more uniform. We support our findings with both experiments and theories.
Submix: Practical Private Prediction for Large-Scale Language Models
Jan 04, 2022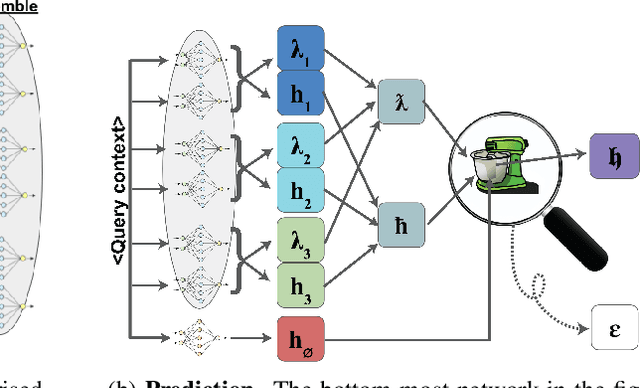

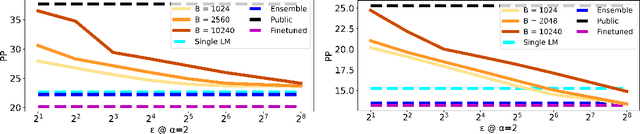
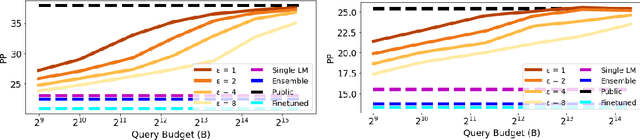
Recent data-extraction attacks have exposed that language models can memorize some training samples verbatim. This is a vulnerability that can compromise the privacy of the model's training data. In this work, we introduce SubMix: a practical protocol for private next-token prediction designed to prevent privacy violations by language models that were fine-tuned on a private corpus after pre-training on a public corpus. We show that SubMix limits the leakage of information that is unique to any individual user in the private corpus via a relaxation of group differentially private prediction. Importantly, SubMix admits a tight, data-dependent privacy accounting mechanism, which allows it to thwart existing data-extraction attacks while maintaining the utility of the language model. SubMix is the first protocol that maintains privacy even when publicly releasing tens of thousands of next-token predictions made by large transformer-based models such as GPT-2.
MLDemon: Deployment Monitoring for Machine Learning Systems
May 05, 2021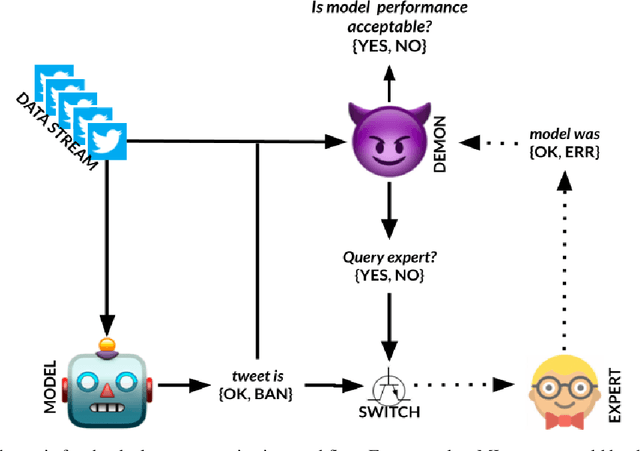
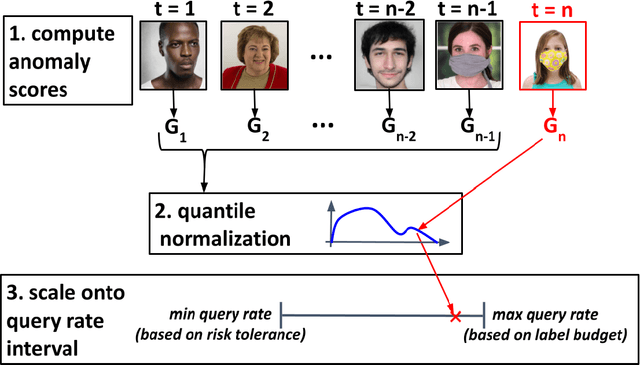

Post-deployment monitoring of the performance of ML systems is critical for ensuring reliability, especially as new user inputs can differ from the training distribution. Here we propose a novel approach, MLDemon, for ML DEployment MONitoring. MLDemon integrates both unlabeled features and a small amount of on-demand labeled examples over time to produce a real-time estimate of the ML model's current performance on a given data stream. Subject to budget constraints, MLDemon decides when to acquire additional, potentially costly, supervised labels to verify the model. On temporal datasets with diverse distribution drifts and models, MLDemon substantially outperforms existing monitoring approaches. Moreover, we provide theoretical analysis to show that MLDemon is minimax rate optimal up to logarithmic factors and is provably robust against broad distribution drifts whereas prior approaches are not.
Competing AI: How competition feedback affects machine learning
Oct 02, 2020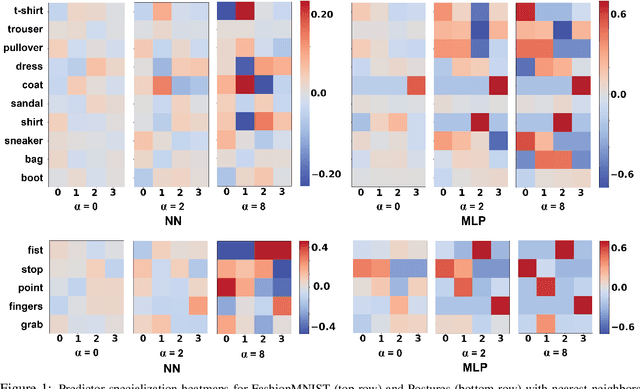
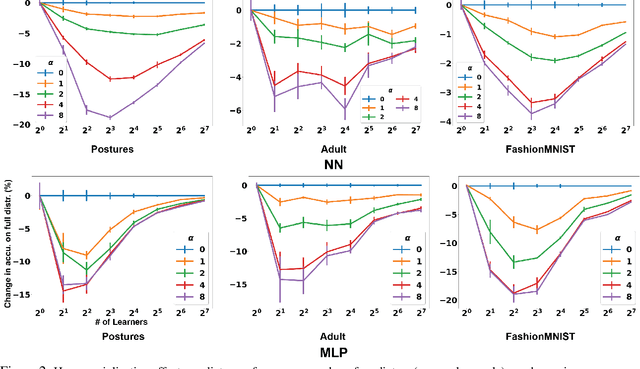
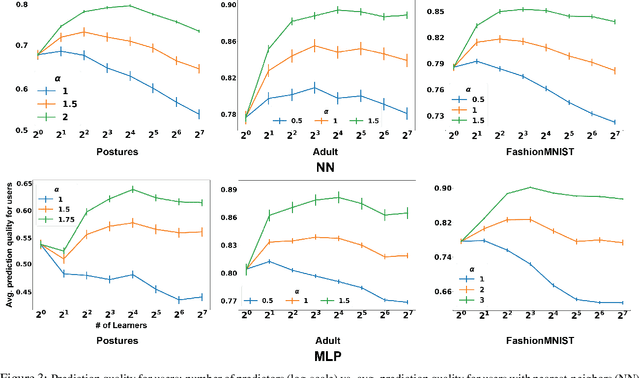
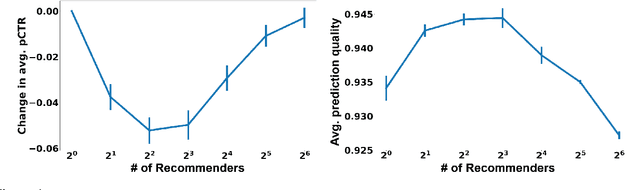
This papers studies how competition affects machine learning (ML) predictors. As ML becomes more ubiquitous, it is often deployed by companies to compete over customers. For example, digital platforms like Yelp use ML to predict user preference and make recommendations. A service that is more often queried by users, perhaps because it more accurately anticipates user preferences, is also more likely to obtain additional user data (e.g. in the form of a Yelp review). Thus, competing predictors cause feedback loops whereby a predictor's performance impacts what training data it receives and biases its predictions over time. We introduce a flexible model of competing ML predictors that enables both rapid experimentation and theoretical tractability. We show with empirical and mathematical analysis that competition causes predictors to specialize for specific sub-populations at the cost of worse performance over the general population. We further analyze the impact of predictor specialization on the overall prediction quality experienced by users. We show that having too few or too many competing predictors in a market can hurt the overall prediction quality. Our theory is complemented by experiments on several real datasets using popular learning algorithms, such as neural networks and nearest neighbor methods.
Mixed Dimension Embeddings with Application to Memory-Efficient Recommendation Systems
Sep 25, 2019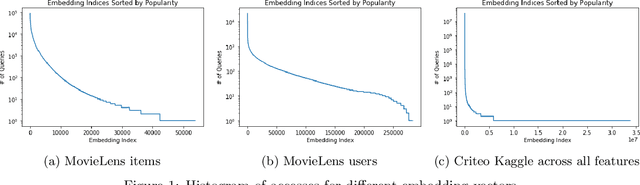
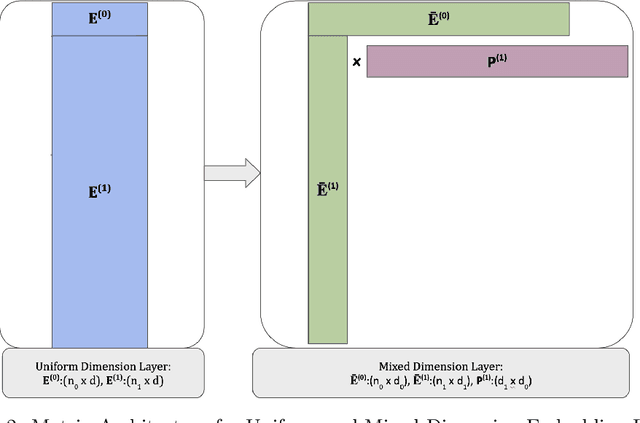
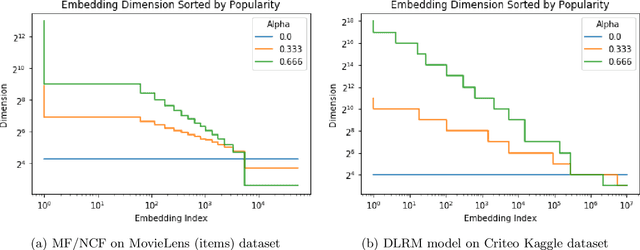
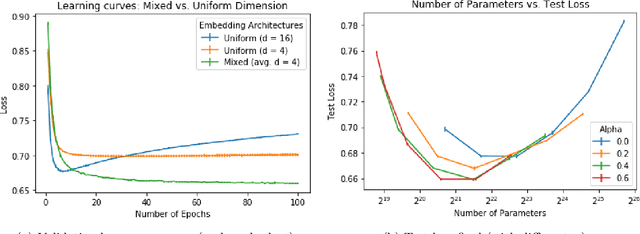
In many real-world applications, e.g. recommendation systems, certain items appear much more frequently than other items. However, standard embedding methods---which form the basis of many ML algorithms---allocate the same dimension to all of the items. This leads to statistical and memory inefficiencies. In this work, we propose mixed dimension embedding layers in which the dimension of a particular embedding vector can depend on the frequency of the item. This approach drastically reduces the memory requirement for the embedding, while maintaining and sometimes improving the ML performance. We show that the proposed mixed dimension layers achieve a higher accuracy, while using 8X fewer parameters, for collaborative filtering on the MovieLens dataset. Also, they improve accuracy by 0.1% using half as many parameters or maintain baseline accuracy using 16X fewer parameters for click-through rate prediction task on the Criteo Kaggle dataset.
Making AI Forget You: Data Deletion in Machine Learning
Jul 11, 2019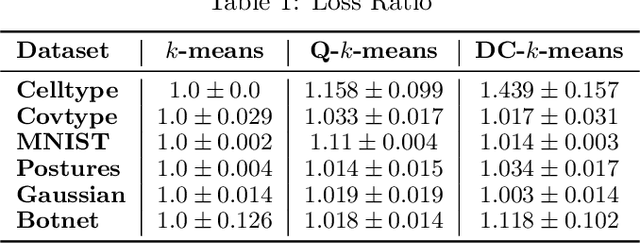
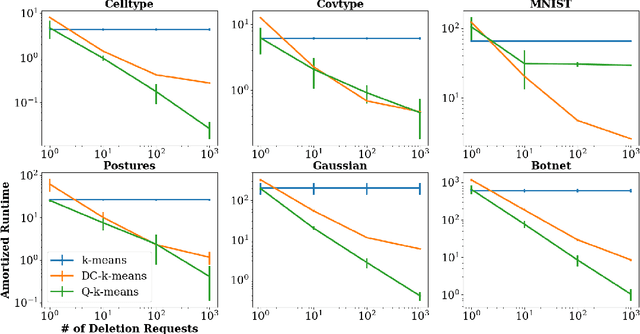
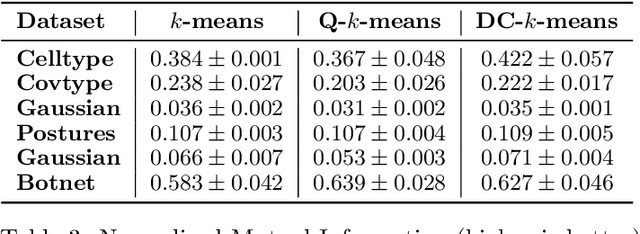
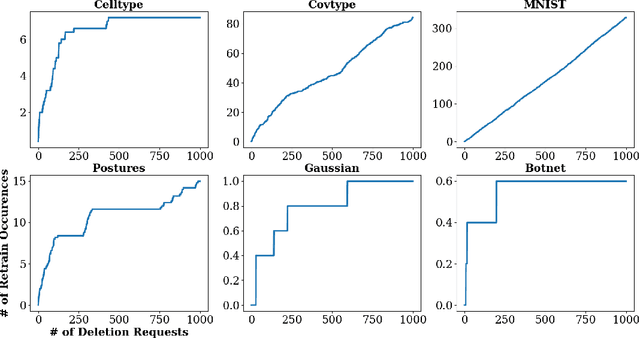
Intense recent discussions have focused on how to provide individuals with control over when their data can and cannot be used -- the EU's Right To Be Forgotten regulation is an example of this effort. In this paper we initiate a framework studying what to do when it is no longer permissible to deploy models derivative from specific user data. In particular, we formulate the problem of how to efficiently delete individual data points from trained machine learning models. For many standard ML models, the only way to completely remove an individual's data is to retrain the whole model from scratch on the remaining data, which is often not computationally practical. We investigate algorithmic principles that enable efficient data deletion in ML. For the specific setting of k-means clustering, we propose two provably deletion efficient algorithms which achieve an average of over 100X improvement in deletion efficiency across 6 datasets, while producing clusters of comparable statistical quality to a canonical k-means++ baseline.