 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSubmix: Practical Private Prediction for Large-Scale Language Models
Paper and Code
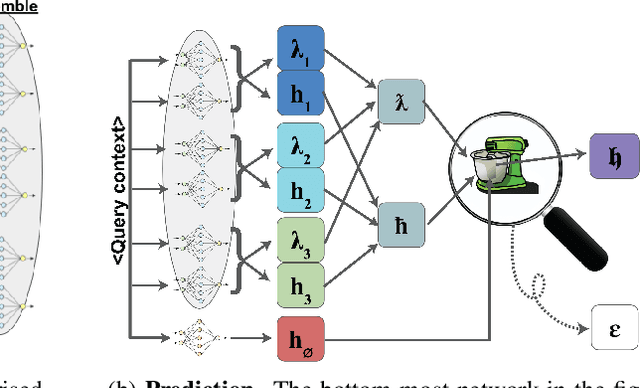

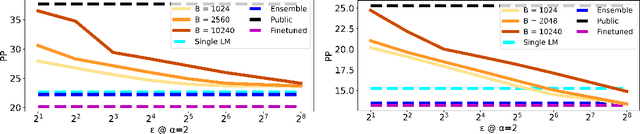
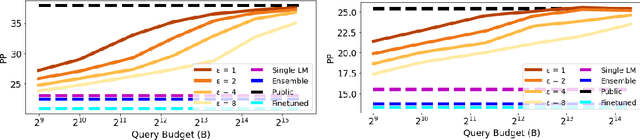
Recent data-extraction attacks have exposed that language models can memorize some training samples verbatim. This is a vulnerability that can compromise the privacy of the model's training data. In this work, we introduce SubMix: a practical protocol for private next-token prediction designed to prevent privacy violations by language models that were fine-tuned on a private corpus after pre-training on a public corpus. We show that SubMix limits the leakage of information that is unique to any individual user in the private corpus via a relaxation of group differentially private prediction. Importantly, SubMix admits a tight, data-dependent privacy accounting mechanism, which allows it to thwart existing data-extraction attacks while maintaining the utility of the language model. SubMix is the first protocol that maintains privacy even when publicly releasing tens of thousands of next-token predictions made by large transformer-based models such as GPT-2.