 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModel Robustness Meets Data Privacy: Adversarial Robustness Distillation without Original Data
Paper and Code
Mar 21, 2023
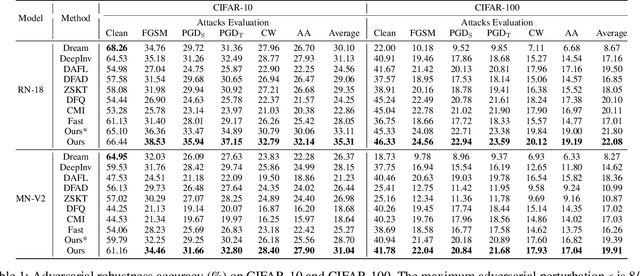


Large-scale deep learning models have achieved great performance based on large-scale datasets. Moreover, the existing Adversarial Training (AT) can further improve the robustness of these large models. However, these large models are difficult to deploy to mobile devices, and the effect of AT on small models is very limited. In addition, the data privacy issue (e.g., face data and diagnosis report) may lead to the original data being unavailable, which relies on data-free knowledge distillation technology for training. To tackle these issues, we propose a challenging novel task called Data-Free Adversarial Robustness Distillation (DFARD), which tries to train small, easily deployable, robust models without relying on the original data. We find the combination of existing techniques resulted in degraded model performance due to fixed training objectives and scarce information content. First, an interactive strategy is designed for more efficient knowledge transfer to find more suitable training objectives at each epoch. Then, we explore an adaptive balance method to suppress information loss and obtain more data information than previous methods. Experiments show that our method improves baseline performance on the novel task.