 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhysics Encoded Blocks in Residual Neural Network Architectures for Digital Twin Models
Nov 18, 2024



Physics Informed Machine Learning has emerged as a popular approach in modelling and simulation for digital twins to generate accurate models of processes and behaviours of real-world systems. However, despite their success in generating accurate and reliable models, the existing methods either use simple regularizations in loss functions to offer limited physics integration or are too specific in architectural definitions to be generalized to a wide variety of physical systems. This paper presents a generic approach based on a novel physics-encoded residual neural network architecture to combine data-driven and physics-based analytical models to address these limitations. Our method combines physics blocks as mathematical operators from physics-based models with learning blocks comprising feed-forward layers. Intermediate residual blocks are incorporated for stable gradient flow as they train on physical system observation data. This way, the model learns to comply with the geometric and kinematic aspects of the physical system. Compared to conventional neural network-based methods, our method improves generalizability with substantially low data requirements and model complexity in terms of parameters, especially in scenarios where prior physics knowledge is either elementary or incomplete. We investigate our approach in two application domains. The first is a basic robotic motion model using Euler Lagrangian equations of motion as physics prior. The second application is a complex scenario of a steering model for a self-driving vehicle in a simulation. In both applications, our method outperforms both conventional neural network based approaches as-well as state-of-the-art Physics Informed Machine Learning methods.
Synaptic Modulation using Interspike Intervals Increases Energy Efficiency of Spiking Neural Networks
Aug 06, 2024


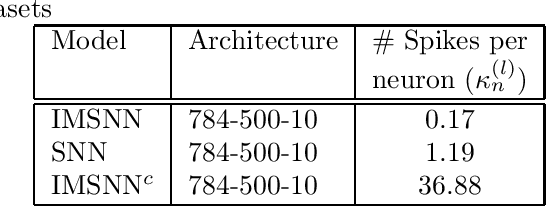
Despite basic differences between Spiking Neural Networks (SNN) and Artificial Neural Networks (ANN), most research on SNNs involve adapting ANN-based methods for SNNs. Pruning (dropping connections) and quantization (reducing precision) are often used to improve energy efficiency of SNNs. These methods are very effective for ANNs whose energy needs are determined by signals transmitted on synapses. However, the event-driven paradigm in SNNs implies that energy is consumed by spikes. In this paper, we propose a new synapse model whose weights are modulated by Interspike Intervals (ISI) i.e. time difference between two spikes. SNNs composed of this synapse model, termed ISI Modulated SNNs (IMSNN), can use gradient descent to estimate how the ISI of a neuron changes after updating its synaptic parameters. A higher ISI implies fewer spikes and vice-versa. The learning algorithm for IMSNNs exploits this information to selectively propagate gradients such that learning is achieved by increasing the ISIs resulting in a network that generates fewer spikes. The performance of IMSNNs with dense and convolutional layers have been evaluated in terms of classification accuracy and the number of spikes using the MNIST and FashionMNIST datasets. The performance comparison with conventional SNNs shows that IMSNNs exhibit upto 90% reduction in the number of spikes while maintaining similar classification accuracy.
The least-used key selection method for information retrieval in large-scale Cloud-based service repositories
Aug 16, 2022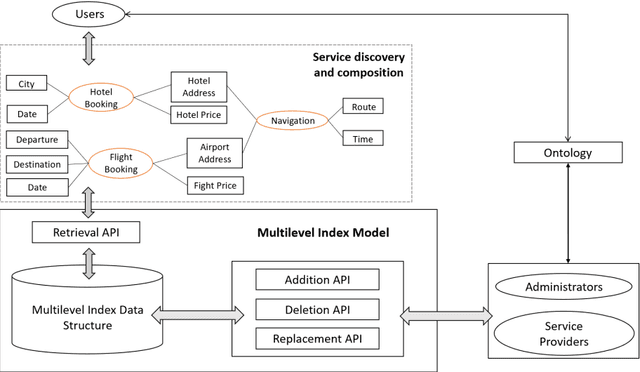
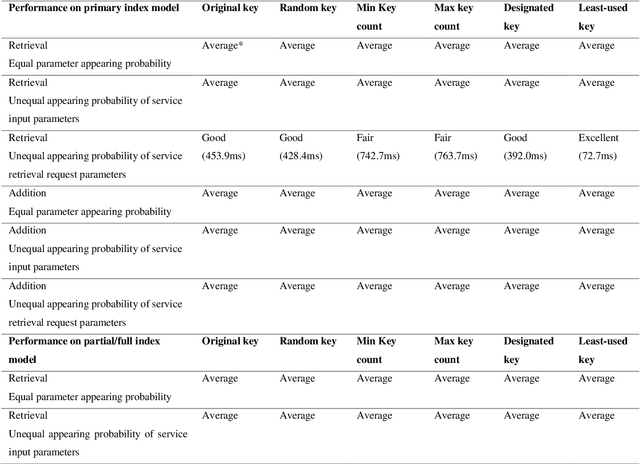

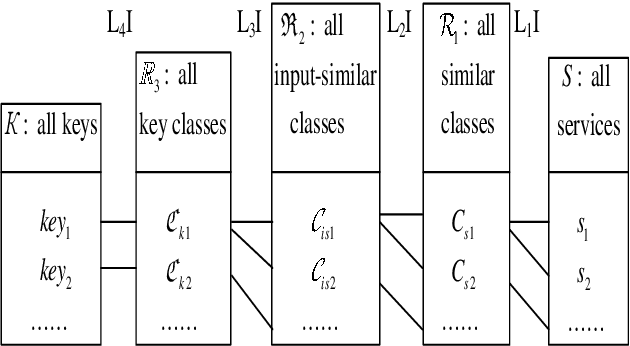
As the number of devices connected to the Internet of Things (IoT) increases significantly, it leads to an exponential growth in the number of services that need to be processed and stored in the large-scale Cloud-based service repositories. An efficient service indexing model is critical for service retrieval and management of large-scale Cloud-based service repositories. The multilevel index model is the state-of-art service indexing model in recent years to improve service discovery and combination. This paper aims to optimize the model to consider the impact of unequal appearing probability of service retrieval request parameters and service input parameters on service retrieval and service addition operations. The least-used key selection method has been proposed to narrow the search scope of service retrieval and reduce its time. The experimental results show that the proposed least-used key selection method improves the service retrieval efficiency significantly compared with the designated key selection method in the case of the unequal appearing probability of parameters in service retrieval requests under three indexing models.
Digital Twinning Remote Laboratories for Online Practical Learning
Dec 13, 2021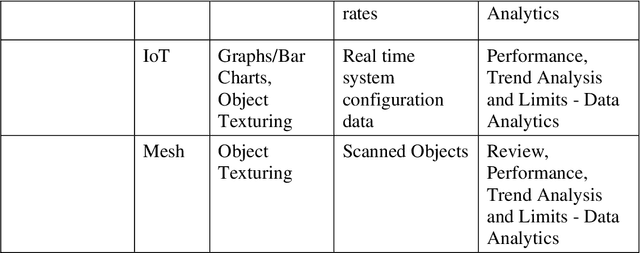
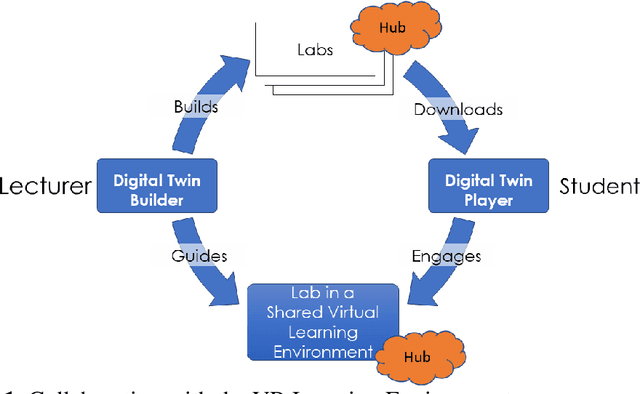
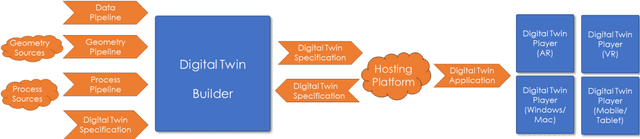
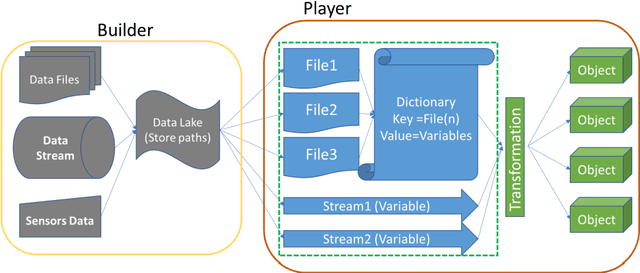
The COVID19 pandemic has demonstrated a need for remote learning and virtual learning applications such as virtual reality (VR) and tablet-based solutions. Creating complex learning scenarios by developers is highly time-consuming and can take over a year. It is also costly to employ teams of system analysts, developers and 3D artists. There is a requirement to provide a simple method to enable lecturers to create their own content for their laboratory tutorials. Research has been undertaken into developing generic models to enable the semi-automatic creation of a virtual learning tools for subjects that require practical interactions with the lab resources. In addition to the system for creating digital twins, a case study describing the creation of a virtual learning application for an electrical laboratory tutorial has been presented.
Optimization of Service Addition in Multilevel Index Model for Edge Computing
Jun 19, 2021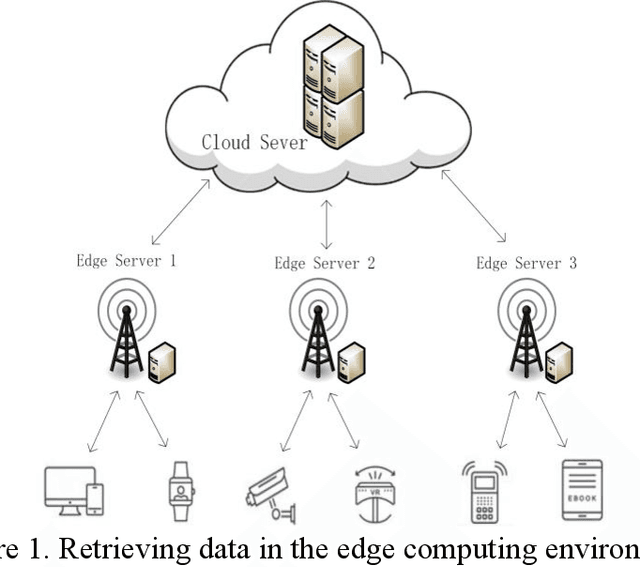
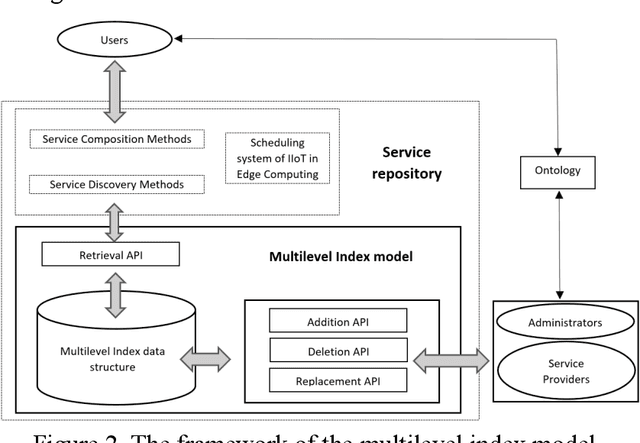
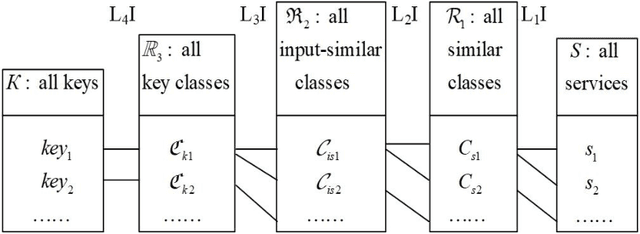
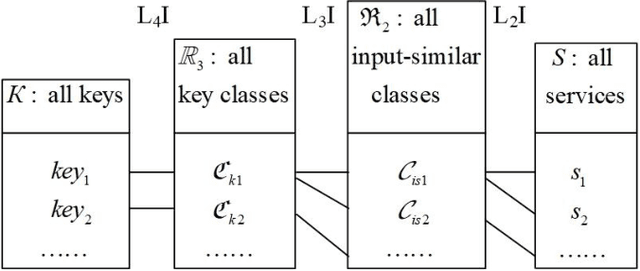
With the development of Edge Computing and Artificial Intelligence (AI) technologies, edge devices are witnessed to generate data at unprecedented volume. The Edge Intelligence (EI) has led to the emergence of edge devices in various application domains. The EI can provide efficient services to delay-sensitive applications, where the edge devices are deployed as edge nodes to host the majority of execution, which can effectively manage services and improve service discovery efficiency. The multilevel index model is a well-known model used for indexing service, such a model is being introduced and optimized in the edge environments to efficiently services discovery whilst managing large volumes of data. However, effectively updating the multilevel index model by adding new services timely and precisely in the dynamic Edge Computing environments is still a challenge. Addressing this issue, this paper proposes a designated key selection method to improve the efficiency of adding services in the multilevel index models. Our experimental results show that in the partial index and the full index of multilevel index model, our method reduces the service addition time by around 84% and 76%, respectively when compared with the original key selection method and by around 78% and 66%, respectively when compared with the random selection method. Our proposed method significantly improves the service addition efficiency in the multilevel index model, when compared with existing state-of-the-art key selection methods, without compromising the service retrieval stability to any notable level.
Cloud based Scalable Object Recognition from Video Streams using Orientation Fusion and Convolutional Neural Networks
Jun 19, 2021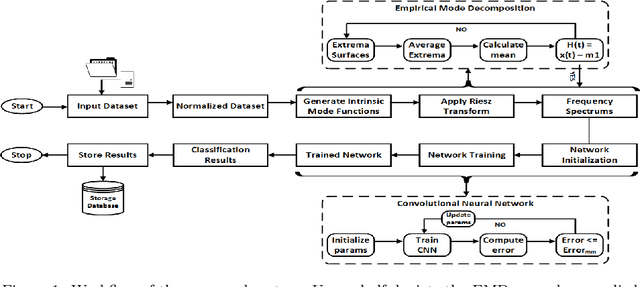
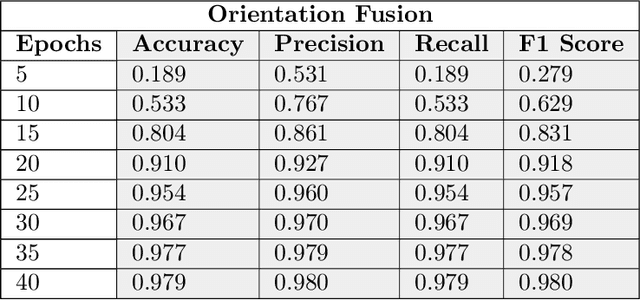
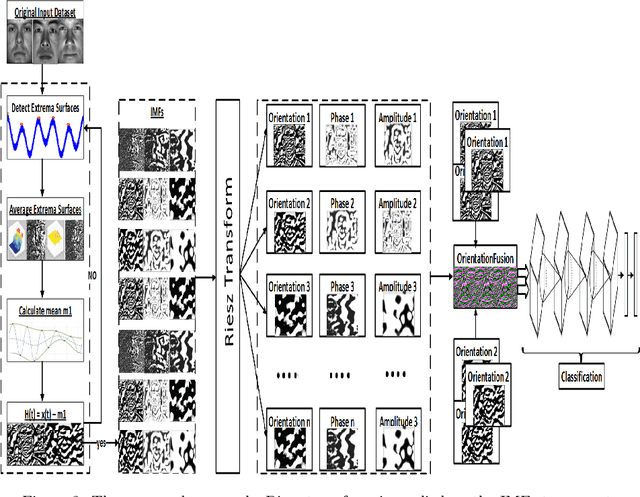

Object recognition from live video streams comes with numerous challenges such as the variation in illumination conditions and poses. Convolutional neural networks (CNNs) have been widely used to perform intelligent visual object recognition. Yet, CNNs still suffer from severe accuracy degradation, particularly on illumination-variant datasets. To address this problem, we propose a new CNN method based on orientation fusion for visual object recognition. The proposed cloud-based video analytics system pioneers the use of bi-dimensional empirical mode decomposition to split a video frame into intrinsic mode functions (IMFs). We further propose these IMFs to endure Reisz transform to produce monogenic object components, which are in turn used for the training of CNNs. Past works have demonstrated how the object orientation component may be used to pursue accuracy levels as high as 93\%. Herein we demonstrate how a feature-fusion strategy of the orientation components leads to further improving visual recognition accuracy to 97\%. We also assess the scalability of our method, looking at both the number and the size of the video streams under scrutiny. We carry out extensive experimentation on the publicly available Yale dataset, including also a self generated video datasets, finding significant improvements (both in accuracy and scale), in comparison to AlexNet, LeNet and SE-ResNeXt, which are the three most commonly used deep learning models for visual object recognition and classification.
Virtual Reality based Digital Twin System for remote laboratories and online practical learning
Jun 17, 2021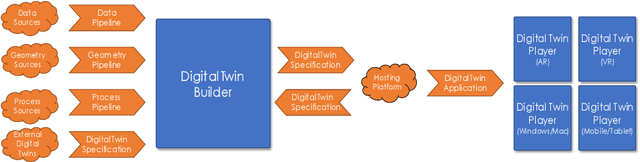

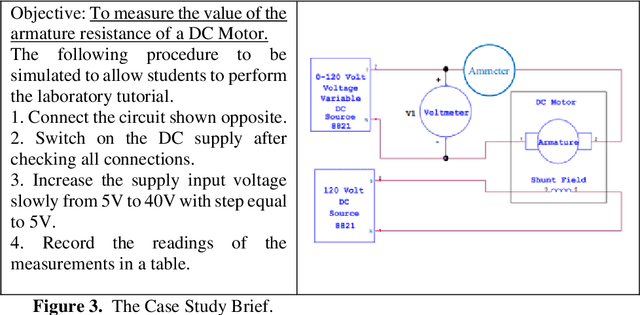
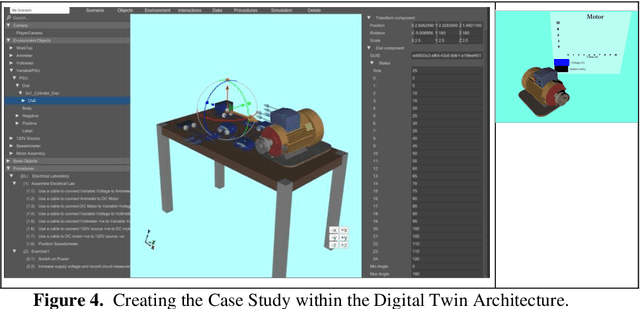
There is a need for remote learning and virtual learning applications such as virtual reality (VR) and tablet-based solutions which the current pandemic has demonstrated. Creating complex learning scenarios by developers is highly time-consuming and can take over a year. There is a need to provide a simple method to enable lecturers to create their own content for their laboratory tutorials. Research is currently being undertaken into developing generic models to enable the semi-automatic creation of a virtual learning application. A case study describing the creation of a virtual learning application for an electrical laboratory tutorial is presented.
Multiclass Disease Predictions Based on Integrated Clinical and Genomics Datasets
Jun 14, 2020
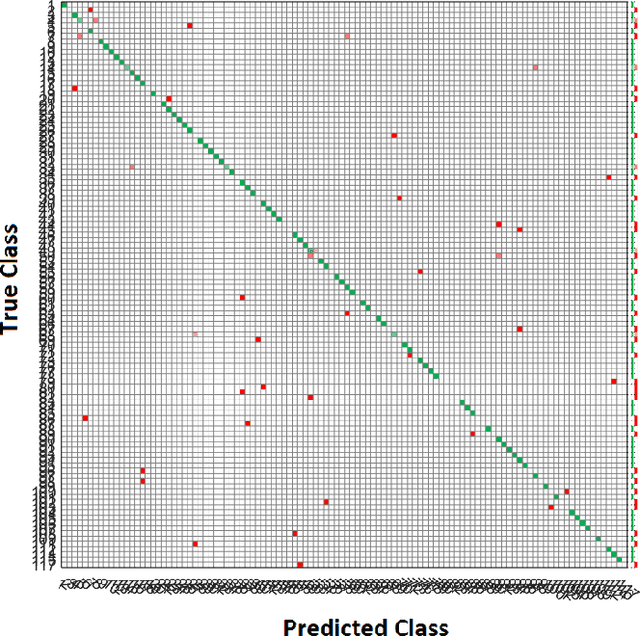

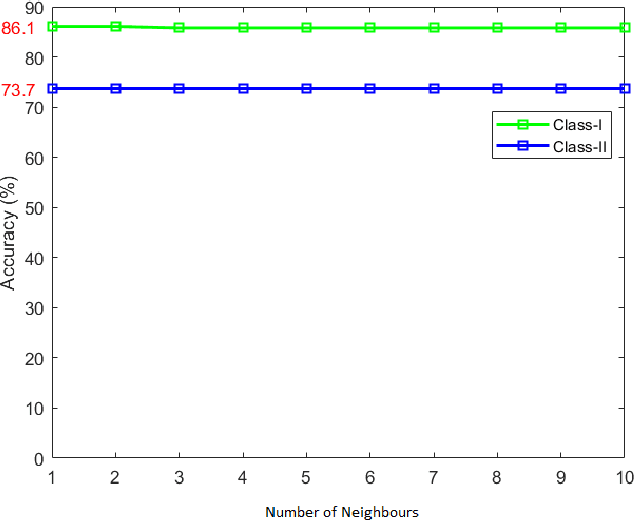
Clinical predictions using clinical data by computational methods are common in bioinformatics. However, clinical predictions using information from genomics datasets as well is not a frequently observed phenomenon in research. Precision medicine research requires information from all available datasets to provide intelligent clinical solutions. In this paper, we have attempted to create a prediction model which uses information from both clinical and genomics datasets. We have demonstrated multiclass disease predictions based on combined clinical and genomics datasets using machine learning methods. We have created an integrated dataset, using a clinical (ClinVar) and a genomics (gene expression) dataset, and trained it using instance-based learner to predict clinical diseases. We have used an innovative but simple way for multiclass classification, where the number of output classes is as high as 75. We have used Principal Component Analysis for feature selection. The classifier predicted diseases with 73\% accuracy on the integrated dataset. The results were consistent and competent when compared with other classification models. The results show that genomics information can be reliably included in datasets for clinical predictions and it can prove to be valuable in clinical diagnostics and precision medicine.