 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA benchmark multimodal oro-dental dataset for large vision-language models
Nov 07, 2025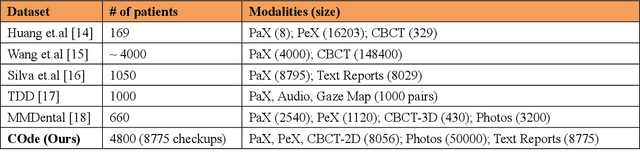
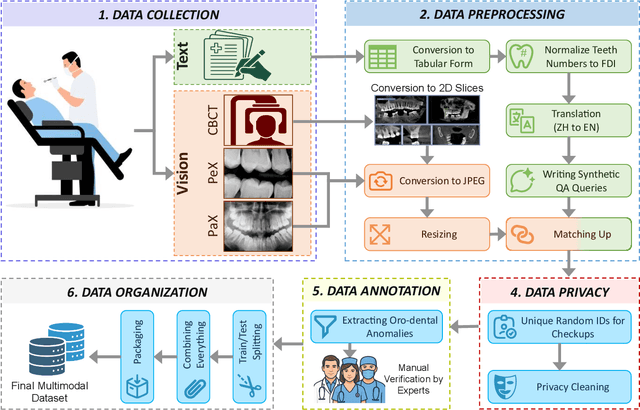
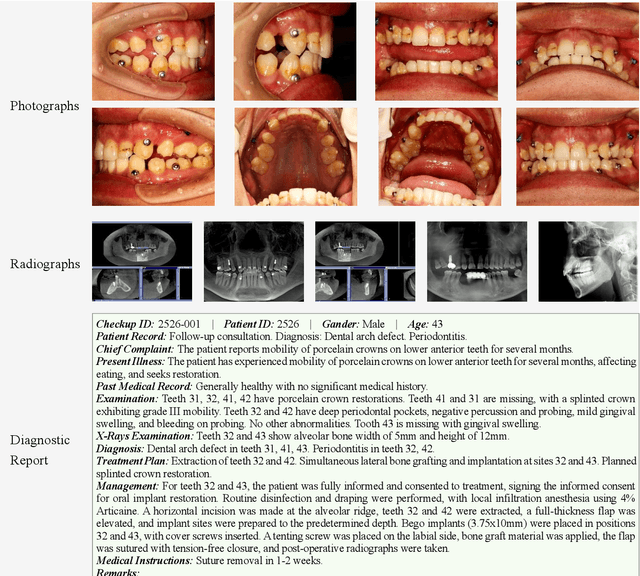
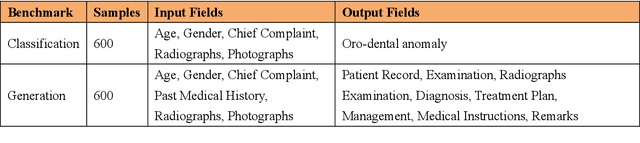
The advancement of artificial intelligence in oral healthcare relies on the availability of large-scale multimodal datasets that capture the complexity of clinical practice. In this paper, we present a comprehensive multimodal dataset, comprising 8775 dental checkups from 4800 patients collected over eight years (2018-2025), with patients ranging from 10 to 90 years of age. The dataset includes 50000 intraoral images, 8056 radiographs, and detailed textual records, including diagnoses, treatment plans, and follow-up notes. The data were collected under standard ethical guidelines and annotated for benchmarking. To demonstrate its utility, we fine-tuned state-of-the-art large vision-language models, Qwen-VL 3B and 7B, and evaluated them on two tasks: classification of six oro-dental anomalies and generation of complete diagnostic reports from multimodal inputs. We compared the fine-tuned models with their base counterparts and GPT-4o. The fine-tuned models achieved substantial gains over these baselines, validating the dataset and underscoring its effectiveness in advancing AI-driven oro-dental healthcare solutions. The dataset is publicly available, providing an essential resource for future research in AI dentistry.
Adaptive Security Policy Management in Cloud Environments Using Reinforcement Learning
May 13, 2025The security of cloud environments, such as Amazon Web Services (AWS), is complex and dynamic. Static security policies have become inadequate as threats evolve and cloud resources exhibit elasticity [1]. This paper addresses the limitations of static policies by proposing a security policy management framework that uses reinforcement learning (RL) to adapt dynamically. Specifically, we employ deep reinforcement learning algorithms, including deep Q Networks and proximal policy optimization, enabling the learning and continuous adjustment of controls such as firewall rules and Identity and Access Management (IAM) policies. The proposed RL based solution leverages cloud telemetry data (AWS Cloud Trail logs, network traffic data, threat intelligence feeds) to continuously refine security policies, maximizing threat mitigation, and compliance while minimizing resource impact. Experimental results demonstrate that our adaptive RL based framework significantly outperforms static policies, achieving higher intrusion detection rates (92% compared to 82% for static policies) and substantially reducing incident detection and response times by 58%. In addition, it maintains high conformity with security requirements and efficient resource usage. These findings validate the effectiveness of adaptive reinforcement learning approaches in improving cloud security policy management.
RDD4D: 4D Attention-Guided Road Damage Detection And Classification
Jan 06, 2025Road damage detection and assessment are crucial components of infrastructure maintenance. However, current methods often struggle with detecting multiple types of road damage in a single image, particularly at varying scales. This is due to the lack of road datasets with various damage types having varying scales. To overcome this deficiency, first, we present a novel dataset called Diverse Road Damage Dataset (DRDD) for road damage detection that captures the diverse road damage types in individual images, addressing a crucial gap in existing datasets. Then, we provide our model, RDD4D, that exploits Attention4D blocks, enabling better feature refinement across multiple scales. The Attention4D module processes feature maps through an attention mechanism combining positional encoding and "Talking Head" components to capture local and global contextual information. In our comprehensive experimental analysis comparing various state-of-the-art models on our proposed, our enhanced model demonstrated superior performance in detecting large-sized road cracks with an Average Precision (AP) of 0.458 and maintained competitive performance with an overall AP of 0.445. Moreover, we also provide results on the CrackTinyNet dataset; our model achieved around a 0.21 increase in performance. The code, model weights, dataset, and our results are available on \href{https://github.com/msaqib17/Road_Damage_Detection}{https://github.com/msaqib17/Road\_Damage\_Detection}.
Cefdet: Cognitive Effectiveness Network Based on Fuzzy Inference for Action Detection
Oct 08, 2024
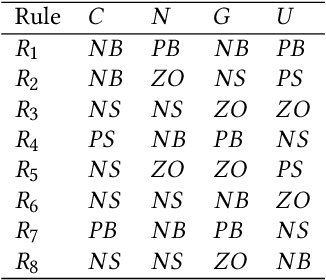
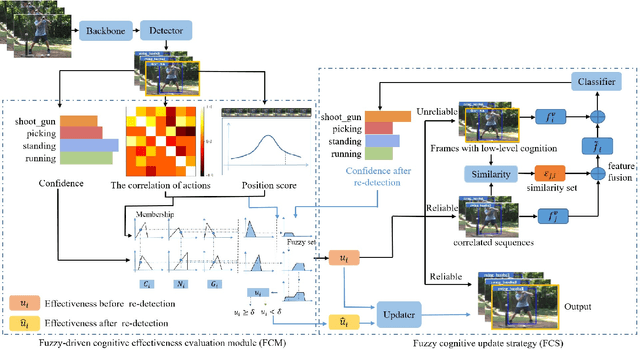
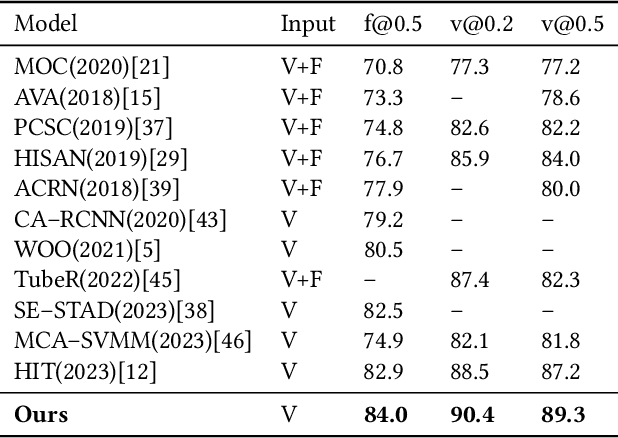
Action detection and understanding provide the foundation for the generation and interaction of multimedia content. However, existing methods mainly focus on constructing complex relational inference networks, overlooking the judgment of detection effectiveness. Moreover, these methods frequently generate detection results with cognitive abnormalities. To solve the above problems, this study proposes a cognitive effectiveness network based on fuzzy inference (Cefdet), which introduces the concept of "cognition-based detection" to simulate human cognition. First, a fuzzy-driven cognitive effectiveness evaluation module (FCM) is established to introduce fuzzy inference into action detection. FCM is combined with human action features to simulate the cognition-based detection process, which clearly locates the position of frames with cognitive abnormalities. Then, a fuzzy cognitive update strategy (FCS) is proposed based on the FCM, which utilizes fuzzy logic to re-detect the cognition-based detection results and effectively update the results with cognitive abnormalities. Experimental results demonstrate that Cefdet exhibits superior performance against several mainstream algorithms on the public datasets, validating its effectiveness and superiority.
HazeSpace2M: A Dataset for Haze Aware Single Image Dehazing
Sep 25, 2024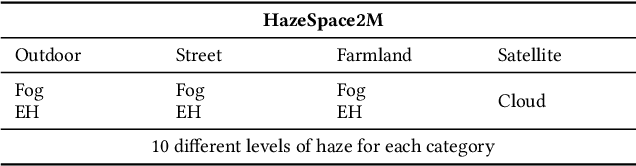
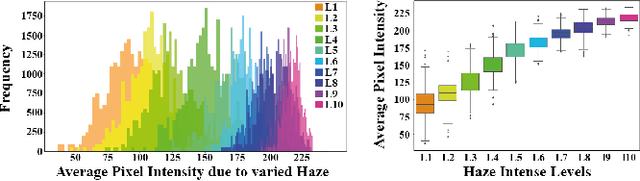
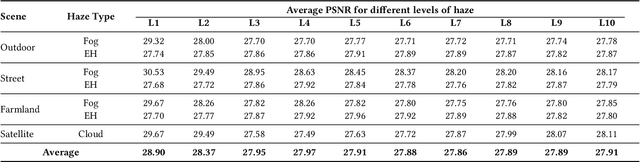
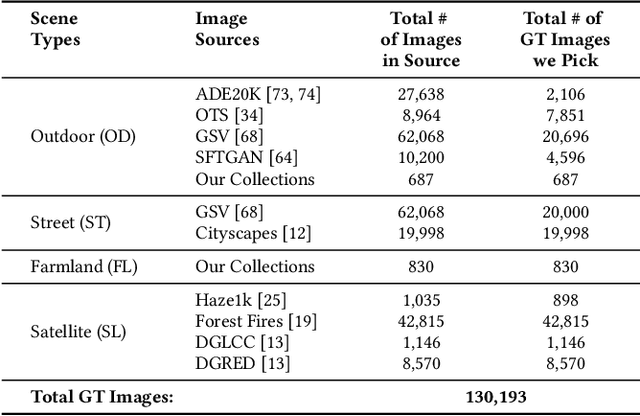
Reducing the atmospheric haze and enhancing image clarity is crucial for computer vision applications. The lack of real-life hazy ground truth images necessitates synthetic datasets, which often lack diverse haze types, impeding effective haze type classification and dehazing algorithm selection. This research introduces the HazeSpace2M dataset, a collection of over 2 million images designed to enhance dehazing through haze type classification. HazeSpace2M includes diverse scenes with 10 haze intensity levels, featuring Fog, Cloud, and Environmental Haze (EH). Using the dataset, we introduce a technique of haze type classification followed by specialized dehazers to clear hazy images. Unlike conventional methods, our approach classifies haze types before applying type-specific dehazing, improving clarity in real-life hazy images. Benchmarking with state-of-the-art (SOTA) models, ResNet50 and AlexNet achieve 92.75\% and 92.50\% accuracy, respectively, against existing synthetic datasets. However, these models achieve only 80% and 70% accuracy, respectively, against our Real Hazy Testset (RHT), highlighting the challenging nature of our HazeSpace2M dataset. Additional experiments show that haze type classification followed by specialized dehazing improves results by 2.41% in PSNR, 17.14% in SSIM, and 10.2\% in MSE over general dehazers. Moreover, when testing with SOTA dehazing models, we found that applying our proposed framework significantly improves their performance. These results underscore the significance of HazeSpace2M and our proposed framework in addressing atmospheric haze in multimedia processing. Complete code and dataset is available on \href{https://github.com/tanvirnwu/HazeSpace2M} {\textcolor{blue}{\textbf{GitHub}}}.
* Accepted by ACM Multimedia 2024
A Comprehensive Overview of Large Language Models
Jul 12, 2023


Large Language Models (LLMs) have shown excellent generalization capabilities that have led to the development of numerous models. These models propose various new architectures, tweaking existing architectures with refined training strategies, increasing context length, using high-quality training data, and increasing training time to outperform baselines. Analyzing new developments is crucial for identifying changes that enhance training stability and improve generalization in LLMs. This survey paper comprehensively analyses the LLMs architectures and their categorization, training strategies, training datasets, and performance evaluations and discusses future research directions. Moreover, the paper also discusses the basic building blocks and concepts behind LLMs, followed by a complete overview of LLMs, including their important features and functions. Finally, the paper summarizes significant findings from LLM research and consolidates essential architectural and training strategies for developing advanced LLMs. Given the continuous advancements in LLMs, we intend to regularly update this paper by incorporating new sections and featuring the latest LLM models.
Detecting Severity of Diabetic Retinopathy from Fundus Images using Ensembled Transformers
Jan 03, 2023Diabetic Retinopathy (DR) is considered one of the primary concerns due to its effect on vision loss among most people with diabetes globally. The severity of DR is mostly comprehended manually by ophthalmologists from fundus photography-based retina images. This paper deals with an automated understanding of the severity stages of DR. In the literature, researchers have focused on this automation using traditional machine learning-based algorithms and convolutional architectures. However, the past works hardly focused on essential parts of the retinal image to improve the model performance. In this paper, we adopt transformer-based learning models to capture the crucial features of retinal images to understand DR severity better. We work with ensembling image transformers, where we adopt four models, namely ViT (Vision Transformer), BEiT (Bidirectional Encoder representation for image Transformer), CaiT (Class-Attention in Image Transformers), and DeiT (Data efficient image Transformers), to infer the degree of DR severity from fundus photographs. For experiments, we used the publicly available APTOS-2019 blindness detection dataset, where the performances of the transformer-based models were quite encouraging.
Deep Analysis of Visual Product Reviews
Jul 19, 2022
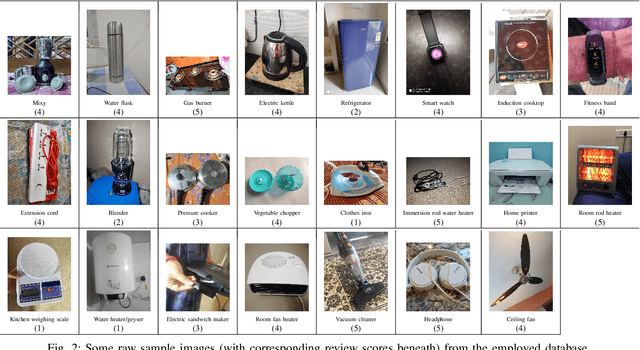
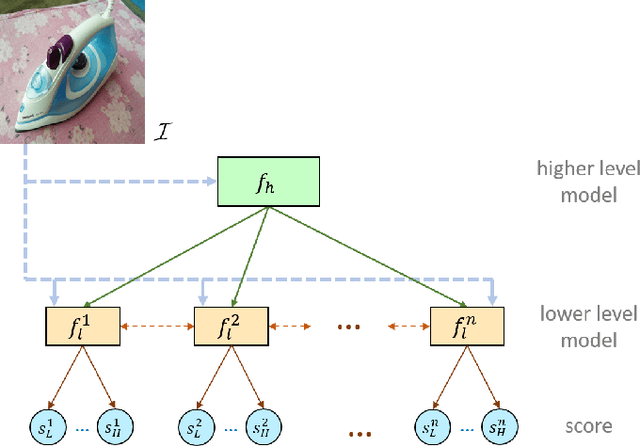
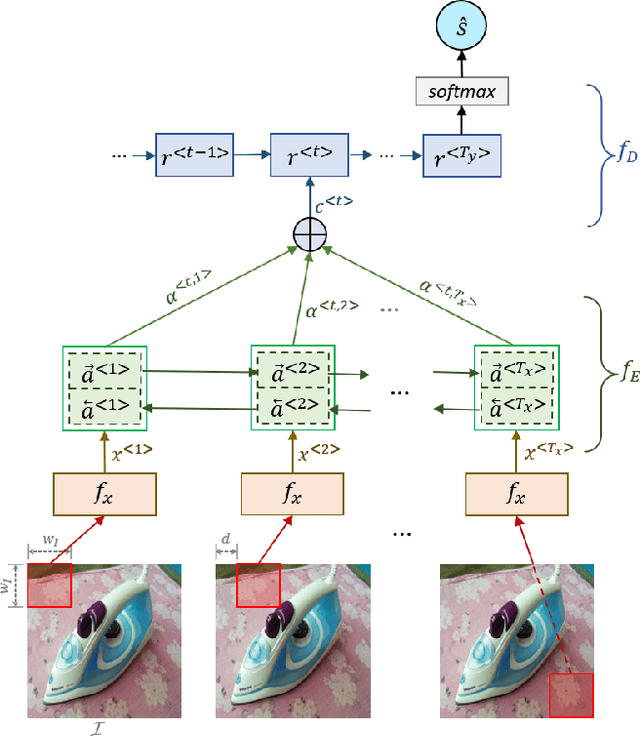
With the proliferation of the e-commerce industry, analyzing customer feedback is becoming indispensable to a service provider. In recent days, it can be noticed that customers upload the purchased product images with their review scores. In this paper, we undertake the task of analyzing such visual reviews, which is very new of its kind. In the past, the researchers worked on analyzing language feedback, but here we do not take any assistance from linguistic reviews that may be absent, since a recent trend can be observed where customers prefer to quickly upload the visual feedback instead of typing language feedback. We propose a hierarchical architecture, where the higher-level model engages in product categorization, and the lower-level model pays attention to predicting the review score from a customer-provided product image. We generated a database by procuring real visual product reviews, which was quite challenging. Our architecture obtained some promising results by performing extensive experiments on the employed database. The proposed hierarchical architecture attained a 57.48% performance improvement over the single-level best comparable architecture.
VisDrone-CC2020: The Vision Meets Drone Crowd Counting Challenge Results
Jul 19, 2021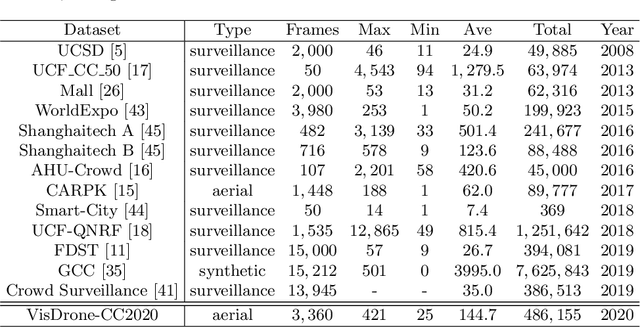

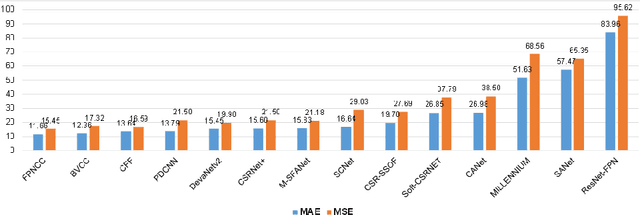
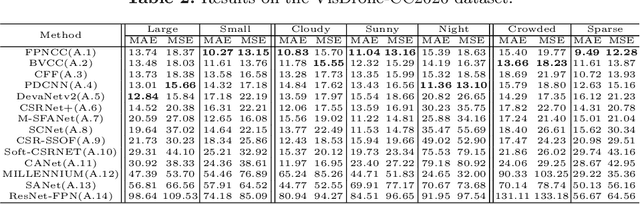
Crowd counting on the drone platform is an interesting topic in computer vision, which brings new challenges such as small object inference, background clutter and wide viewpoint. However, there are few algorithms focusing on crowd counting on the drone-captured data due to the lack of comprehensive datasets. To this end, we collect a large-scale dataset and organize the Vision Meets Drone Crowd Counting Challenge (VisDrone-CC2020) in conjunction with the 16th European Conference on Computer Vision (ECCV 2020) to promote the developments in the related fields. The collected dataset is formed by $3,360$ images, including $2,460$ images for training, and $900$ images for testing. Specifically, we manually annotate persons with points in each video frame. There are $14$ algorithms from $15$ institutes submitted to the VisDrone-CC2020 Challenge. We provide a detailed analysis of the evaluation results and conclude the challenge. More information can be found at the website: \url{http://www.aiskyeye.com/}.
* The method description of A7 Mutil-Scale Aware based SFANet (M-SFANet) is updated and missing references are added
Recognizing Facial Expressions in the Wild using Multi-Architectural Representations based Ensemble Learning with Distillation
Jul 04, 2021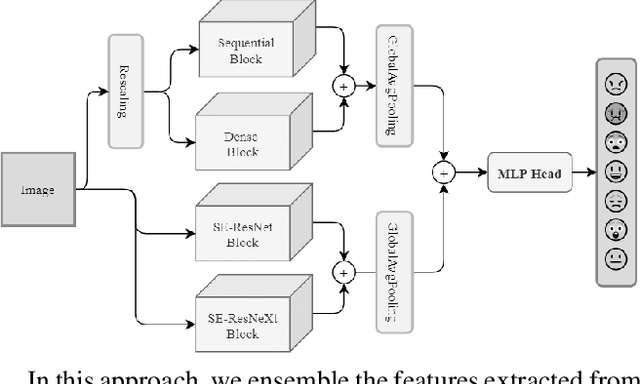
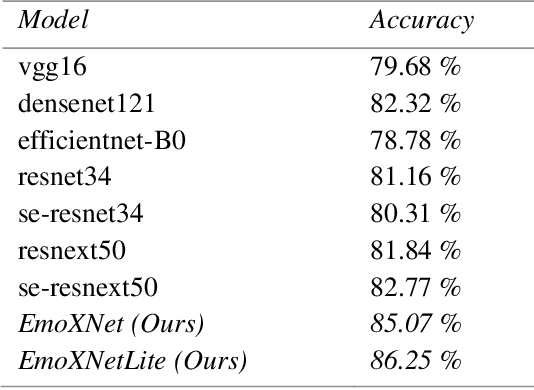
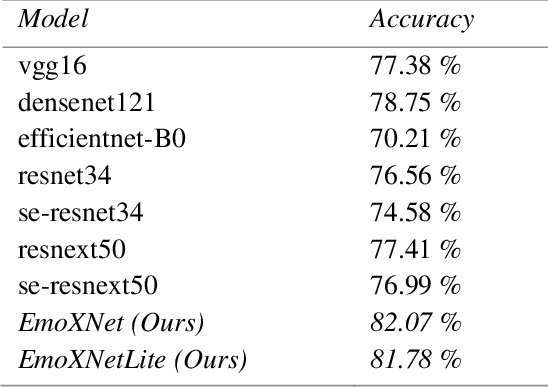

Facial expressions are the most common universal forms of body language. In the past few years, automatic facial expression recognition (FER) has been an active field of research. However, it is still a challenging task due to different uncertainties and complications. Nevertheless, efficiency and performance are yet essential aspects for building robust systems. In this work, we propose two models named EmoXNet and EmoXNetLite. EmoXNet is an ensemble learning technique for learning convoluted facial representations, whereas EmoXNetLite is a distillation technique for transferring the knowledge from our ensemble model to an efficient deep neural network using label-smoothen soft labels to detect expressions effectively in real-time. Both models attained better accuracy level in comparison to the models reported to date. The ensemble model (EmoXNet) attained 85.07% test accuracy on FER-2013 with FER+ annotations and 86.25% test accuracy on Real-world Affective Faces Database (RAF-DB). Whereas, the distilled model (EmoXNetLite) attained 82.07% test accuracy on FER-2013 with FER+ annotations and 81.78% test accuracy on RAF-DB. Results show that our models seem to generalize well on new data and are learned to focus on relevant facial representations for expressions recognition.