 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetecting Severity of Diabetic Retinopathy from Fundus Images using Ensembled Transformers
Paper and Code
Jan 03, 2023
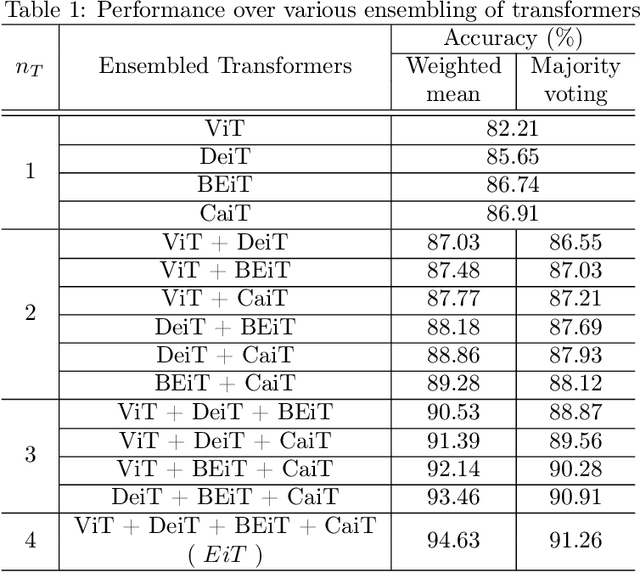

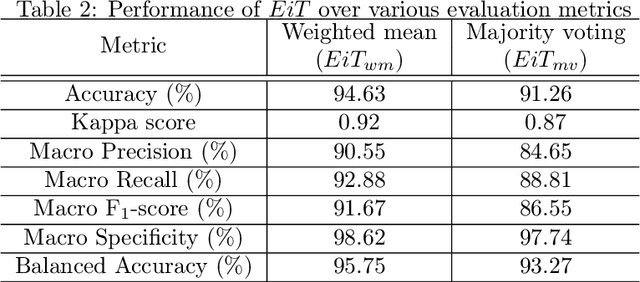
Diabetic Retinopathy (DR) is considered one of the primary concerns due to its effect on vision loss among most people with diabetes globally. The severity of DR is mostly comprehended manually by ophthalmologists from fundus photography-based retina images. This paper deals with an automated understanding of the severity stages of DR. In the literature, researchers have focused on this automation using traditional machine learning-based algorithms and convolutional architectures. However, the past works hardly focused on essential parts of the retinal image to improve the model performance. In this paper, we adopt transformer-based learning models to capture the crucial features of retinal images to understand DR severity better. We work with ensembling image transformers, where we adopt four models, namely ViT (Vision Transformer), BEiT (Bidirectional Encoder representation for image Transformer), CaiT (Class-Attention in Image Transformers), and DeiT (Data efficient image Transformers), to infer the degree of DR severity from fundus photographs. For experiments, we used the publicly available APTOS-2019 blindness detection dataset, where the performances of the transformer-based models were quite encouraging.