 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSAiW: Source-Attributable Invisible Watermarking for Proactive Deepfake Defense
Mar 24, 2026Deepfakes generated by modern generative models pose a serious threat to information integrity, digital identity, and public trust. Existing detection methods are largely reactive, attempting to identify manipulations after they occur and often failing to generalize across evolving generation techniques. This motivates the need for proactive mechanisms that secure media authenticity at the time of creation. In this work, we introduce SAiW, a Source-Attributed Invisible watermarking Framework for proactive deepfake defense and media provenance verification. Unlike conventional watermarking methods that treat watermark payloads as generic signals, SAiW formulates watermark embedding as a source-conditioned representation learning problem, where watermark identity encodes the originating source and modulates the embedding process to produce discriminative and traceable signatures. The framework integrates feature-wise linear modulation to inject source identity into the embedding network, enabling scalable multi-source watermark generation. A perceptual guidance module derived from human visual system priors ensures that watermark perturbations remain visually imperceptible while maintaining robustness. In addition, a dual-purpose forensic decoder simultaneously reconstructs the embedded watermark and performs source attribution, providing both automated verification and interpretable forensic evidence. Extensive experiments across multiple deepfake datasets demonstrate that SAiW achieves high perceptual quality while maintaining strong robustness against compression, filtering, noise, geometric transformations, and adversarial perturbations. By binding digital media to its origin through invisible yet verifiable markers, SAiW enables reliable authentication and source attribution, providing a scalable foundation for proactive deepfake defense and trustworthy media provenance.
Blurb-Refined Inference from Crowdsourced Book Reviews using Hierarchical Genre Mining with Dual-Path Graph Convolutions
Dec 24, 2025Accurate book genre classification is fundamental to digital library organization, content discovery, and personalized recommendation. Existing approaches typically model genre prediction as a flat, single-label task, ignoring hierarchical genre structure and relying heavily on noisy, subjective user reviews, which often degrade classification reliability. We propose HiGeMine, a two-phase hierarchical genre mining framework that robustly integrates user reviews with authoritative book blurbs. In the first phase, HiGeMine employs a zero-shot semantic alignment strategy to filter reviews, retaining only those semantically consistent with the corresponding blurb, thereby mitigating noise, bias, and irrelevance. In the second phase, we introduce a dual-path, two-level graph-based classification architecture: a coarse-grained Level-1 binary classifier distinguishes fiction from non-fiction, followed by Level-2 multi-label classifiers for fine-grained genre prediction. Inter-genre dependencies are explicitly modeled using a label co-occurrence graph, while contextual representations are derived from pretrained language models applied to the filtered textual content. To facilitate systematic evaluation, we curate a new hierarchical book genre dataset. Extensive experiments demonstrate that HiGeMine consistently outperformed strong baselines across hierarchical genre classification tasks. The proposed framework offers a principled and effective solution for leveraging both structured and unstructured textual data in hierarchical book genre analysis.
Agentic Multi-Persona Framework for Evidence-Aware Fake News Detection
Dec 24, 2025The rapid proliferation of online misinformation poses significant risks to public trust, policy, and safety, necessitating reliable automated fake news detection. Existing methods often struggle with multimodal content, domain generalization, and explainability. We propose AMPEND-LS, an agentic multi-persona evidence-grounded framework with LLM-SLM synergy for multimodal fake news detection. AMPEND-LS integrates textual, visual, and contextual signals through a structured reasoning pipeline powered by LLMs, augmented with reverse image search, knowledge graph paths, and persuasion strategy analysis. To improve reliability, we introduce a credibility fusion mechanism combining semantic similarity, domain trustworthiness, and temporal context, and a complementary SLM classifier to mitigate LLM uncertainty and hallucinations. Extensive experiments across three benchmark datasets demonstrate that AMPEND-LS consistently outperformed state-of-the-art baselines in accuracy, F1 score, and robustness. Qualitative case studies further highlight its transparent reasoning and resilience against evolving misinformation. This work advances the development of adaptive, explainable, and evidence-aware systems for safeguarding online information integrity.
SHARP-QoS: Sparsely-gated Hierarchical Adaptive Routing for joint Prediction of QoS
Dec 19, 2025Dependable service-oriented computing relies on multiple Quality of Service (QoS) parameters that are essential to assess service optimality. However, real-world QoS data are extremely sparse, noisy, and shaped by hierarchical dependencies arising from QoS interactions, and geographical and network-level factors, making accurate QoS prediction challenging. Existing methods often predict each QoS parameter separately, requiring multiple similar models, which increases computational cost and leads to poor generalization. Although recent joint QoS prediction studies have explored shared architectures, they suffer from negative transfer due to loss-scaling caused by inconsistent numerical ranges across QoS parameters and further struggle with inadequate representation learning, resulting in degraded accuracy. This paper presents an unified strategy for joint QoS prediction, called SHARP-QoS, that addresses these issues using three components. First, we introduce a dual mechanism to extract the hierarchical features from both QoS and contextual structures via hyperbolic convolution formulated in the Poincaré ball. Second, we propose an adaptive feature-sharing mechanism that allows feature exchange across informative QoS and contextual signals. A gated feature fusion module is employed to support dynamic feature selection among structural and shared representations. Third, we design an EMA-based loss balancing strategy that allows stable joint optimization, thereby mitigating the negative transfer. Evaluations on three datasets with two, three, and four QoS parameters demonstrate that SHARP-QoS outperforms both single- and multi-task baselines. Extensive study shows that our model effectively addresses major challenges, including sparsity, robustness to outliers, and cold-start, while maintaining moderate computational overhead, underscoring its capability for reliable joint QoS prediction.
ProtoSiTex: Learning Semi-Interpretable Prototypes for Multi-label Text Classification
Oct 14, 2025



The surge in user-generated reviews has amplified the need for interpretable models that can provide fine-grained insights. Existing prototype-based models offer intuitive explanations but typically operate at coarse granularity (sentence or document level) and fail to address the multi-label nature of real-world text classification. We propose ProtoSiTex, a semi-interpretable framework designed for fine-grained multi-label text classification. ProtoSiTex employs a dual-phase alternating training strategy: an unsupervised prototype discovery phase that learns semantically coherent and diverse prototypes, and a supervised classification phase that maps these prototypes to class labels. A hierarchical loss function enforces consistency across sub-sentence, sentence, and document levels, enhancing interpretability and alignment. Unlike prior approaches, ProtoSiTex captures overlapping and conflicting semantics using adaptive prototypes and multi-head attention. We also introduce a benchmark dataset of hotel reviews annotated at the sub-sentence level with multiple labels. Experiments on this dataset and two public benchmarks (binary and multi-class) show that ProtoSiTex achieves state-of-the-art performance while delivering faithful, human-aligned explanations, establishing it as a robust solution for semi-interpretable multi-label text classification.
An Adaptive Data-Resilient Multi-Modal Framework for Hierarchical Multi-Label Book Genre Identification
May 05, 2025
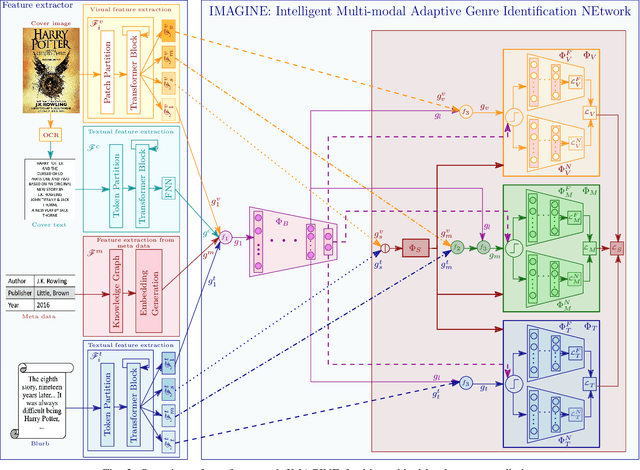


Identifying the finer details of a book's genres enhances user experience by enabling efficient book discovery and personalized recommendations, ultimately improving reader engagement and satisfaction. It also provides valuable insights into market trends and consumer preferences, allowing publishers and marketers to make data-driven decisions regarding book production and marketing strategies. While traditional book genre classification methods primarily rely on review data or textual analysis, incorporating additional modalities, such as book covers, blurbs, and metadata, can offer richer context and improve prediction accuracy. However, the presence of incomplete or noisy information across these modalities presents a significant challenge. This paper introduces IMAGINE (Intelligent Multi-modal Adaptive Genre Identification NEtwork), a framework designed to address these complexities. IMAGINE extracts robust feature representations from multiple modalities and dynamically selects the most informative sources based on data availability. It employs a hierarchical classification strategy to capture genre relationships and remains adaptable to varying input conditions. Additionally, we curate a hierarchical genre classification dataset that structures genres into a well-defined taxonomy, accommodating the diverse nature of literary works. IMAGINE integrates information from multiple sources and assigns multiple genre labels to each book, ensuring a more comprehensive classification. A key feature of our framework is its resilience to incomplete data, enabling accurate predictions even when certain modalities, such as text, images, or metadata, are missing or incomplete. Experimental results show that IMAGINE outperformed existing baselines in genre classification accuracy, particularly in scenarios with insufficient modality-specific data.
Anomaly Resilient Temporal QoS Prediction using Hypergraph Convoluted Transformer Network
Oct 23, 2024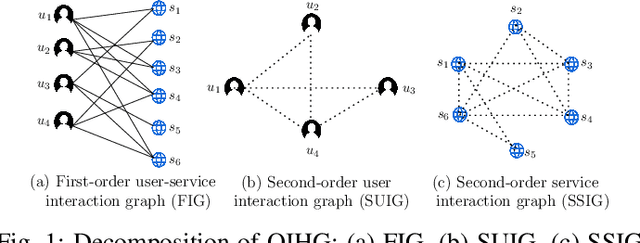
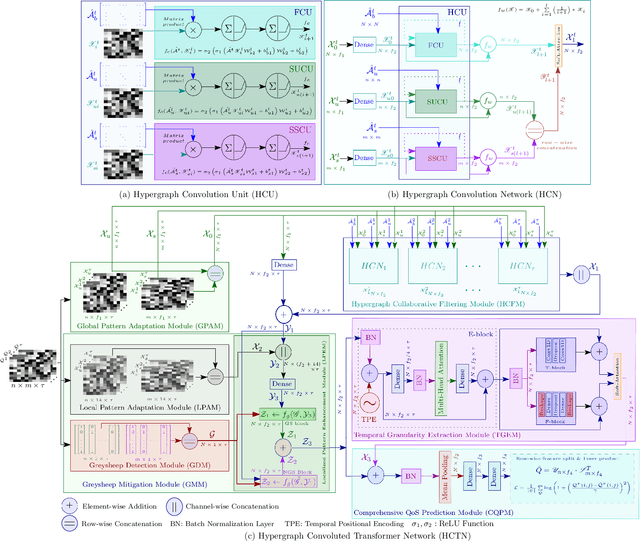
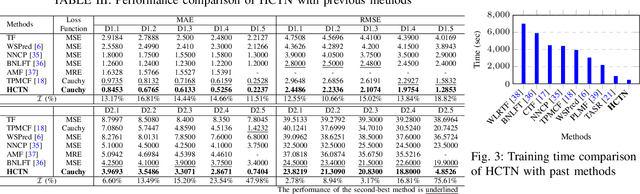
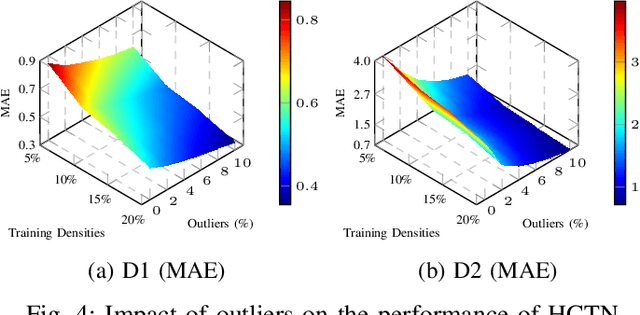
Quality-of-Service (QoS) prediction is a critical task in the service lifecycle, enabling precise and adaptive service recommendations by anticipating performance variations over time in response to evolving network uncertainties and user preferences. However, contemporary QoS prediction methods frequently encounter data sparsity and cold-start issues, which hinder accurate QoS predictions and limit the ability to capture diverse user preferences. Additionally, these methods often assume QoS data reliability, neglecting potential credibility issues such as outliers and the presence of greysheep users and services with atypical invocation patterns. Furthermore, traditional approaches fail to leverage diverse features, including domain-specific knowledge and complex higher-order patterns, essential for accurate QoS predictions. In this paper, we introduce a real-time, trust-aware framework for temporal QoS prediction to address the aforementioned challenges, featuring an end-to-end deep architecture called the Hypergraph Convoluted Transformer Network (HCTN). HCTN combines a hypergraph structure with graph convolution over hyper-edges to effectively address high-sparsity issues by capturing complex, high-order correlations. Complementing this, the transformer network utilizes multi-head attention along with parallel 1D convolutional layers and fully connected dense blocks to capture both fine-grained and coarse-grained dynamic patterns. Additionally, our approach includes a sparsity-resilient solution for detecting greysheep users and services, incorporating their unique characteristics to improve prediction accuracy. Trained with a robust loss function resistant to outliers, HCTN demonstrated state-of-the-art performance on the large-scale WSDREAM-2 datasets for response time and throughput.
SafeTail: Efficient Tail Latency Optimization in Edge Service Scheduling via Computational Redundancy Management
Aug 30, 2024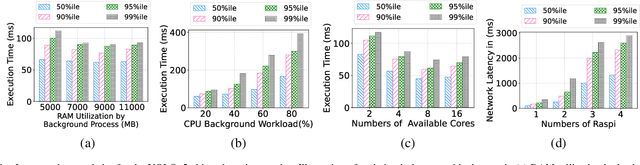
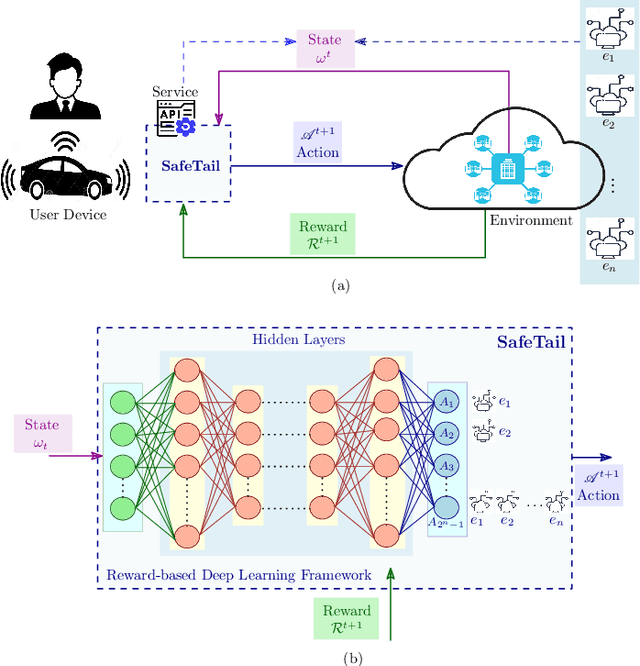
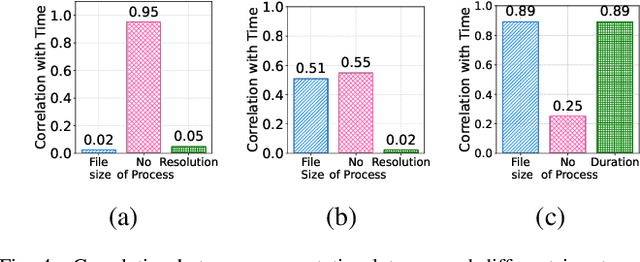
Optimizing tail latency while efficiently managing computational resources is crucial for delivering high-performance, latency-sensitive services in edge computing. Emerging applications, such as augmented reality, require low-latency computing services with high reliability on user devices, which often have limited computational capabilities. Consequently, these devices depend on nearby edge servers for processing. However, inherent uncertainties in network and computation latencies stemming from variability in wireless networks and fluctuating server loads make service delivery on time challenging. Existing approaches often focus on optimizing median latency but fall short of addressing the specific challenges of tail latency in edge environments, particularly under uncertain network and computational conditions. Although some methods do address tail latency, they typically rely on fixed or excessive redundancy and lack adaptability to dynamic network conditions, often being designed for cloud environments rather than the unique demands of edge computing. In this paper, we introduce SafeTail, a framework that meets both median and tail response time targets, with tail latency defined as latency beyond the 90^th percentile threshold. SafeTail addresses this challenge by selectively replicating services across multiple edge servers to meet target latencies. SafeTail employs a reward-based deep learning framework to learn optimal placement strategies, balancing the need to achieve target latencies with minimizing additional resource usage. Through trace-driven simulations, SafeTail demonstrated near-optimal performance and outperformed most baseline strategies across three diverse services.
Demystifying Visual Features of Movie Posters for Multi-Label Genre Identification
Sep 21, 2023

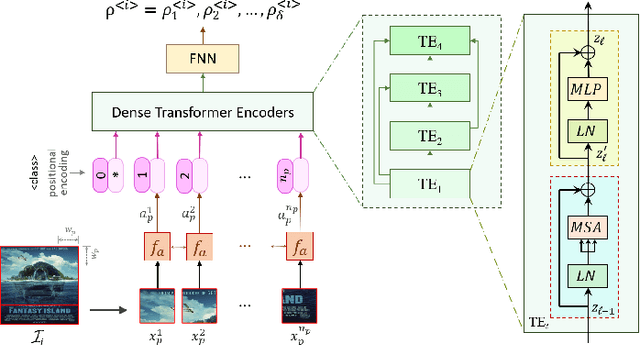
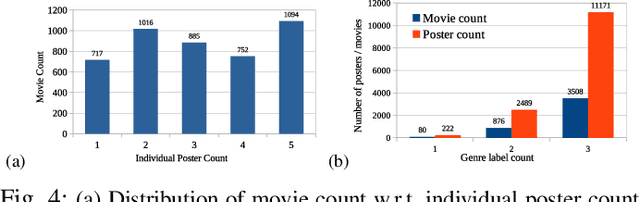
In the film industry, movie posters have been an essential part of advertising and marketing for many decades, and continue to play a vital role even today in the form of digital posters through online, social media and OTT platforms. Typically, movie posters can effectively promote and communicate the essence of a film, such as its genre, visual style/ tone, vibe and storyline cue/ theme, which are essential to attract potential viewers. Identifying the genres of a movie often has significant practical applications in recommending the film to target audiences. Previous studies on movie genre identification are limited to subtitles, plot synopses, and movie scenes that are mostly accessible after the movie release. Posters usually contain pre-release implicit information to generate mass interest. In this paper, we work for automated multi-label genre identification only from movie poster images, without any aid of additional textual/meta-data information about movies, which is one of the earliest attempts of its kind. Here, we present a deep transformer network with a probabilistic module to identify the movie genres exclusively from the poster. For experimental analysis, we procured 13882 number of posters of 13 genres from the Internet Movie Database (IMDb), where our model performances were encouraging and even outperformed some major contemporary architectures.
TPMCF: Temporal QoS Prediction using Multi-Source Collaborative Features
Mar 30, 2023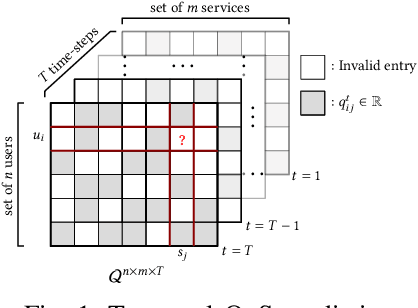
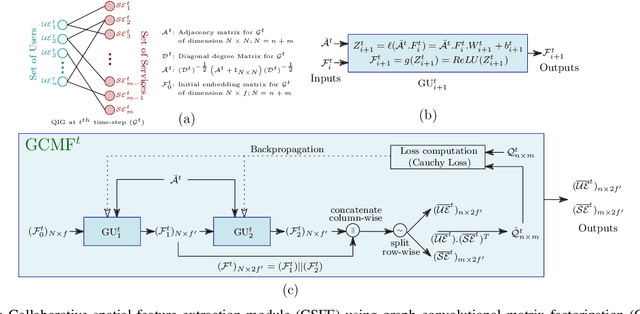
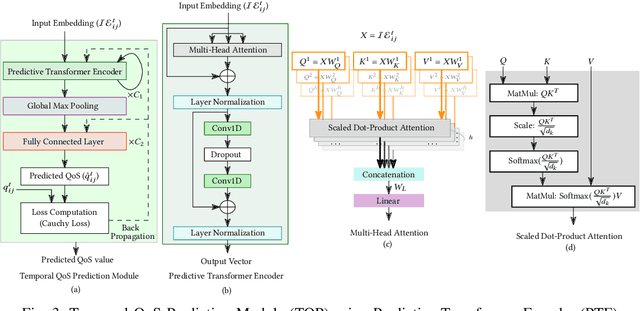
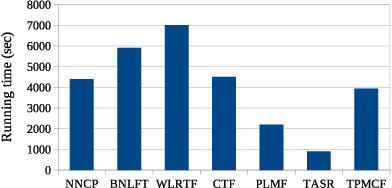
Recently, with the rapid deployment of service APIs, personalized service recommendations have played a paramount role in the growth of the e-commerce industry. Quality-of-Service (QoS) parameters determining the service performance, often used for recommendation, fluctuate over time. Thus, the QoS prediction is essential to identify a suitable service among functionally equivalent services over time. The contemporary temporal QoS prediction methods hardly achieved the desired accuracy due to various limitations, such as the inability to handle data sparsity and outliers and capture higher-order temporal relationships among user-service interactions. Even though some recent recurrent neural-network-based architectures can model temporal relationships among QoS data, prediction accuracy degrades due to the absence of other features (e.g., collaborative features) to comprehend the relationship among the user-service interactions. This paper addresses the above challenges and proposes a scalable strategy for Temporal QoS Prediction using Multi-source Collaborative-Features (TPMCF), achieving high prediction accuracy and faster responsiveness. TPMCF combines the collaborative-features of users/services by exploiting user-service relationship with the spatio-temporal auto-extracted features by employing graph convolution and transformer encoder with multi-head self-attention. We validated our proposed method on WS-DREAM-2 datasets. Extensive experiments showed TPMCF outperformed major state-of-the-art approaches regarding prediction accuracy while ensuring high scalability and reasonably faster responsiveness.