 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIPNET:Influential Prototypical Networks for Few Shot Learning
Aug 19, 2022Prototypical network (PN) is a simple yet effective few shot learning strategy. It is a metric-based meta-learning technique where classification is performed by computing Euclidean distances to prototypical representations of each class. Conventional PN attributes equal importance to all samples and generates prototypes by simply averaging the support sample embeddings belonging to each class. In this work, we propose a novel version of PN that attributes weights to support samples corresponding to their influence on the support sample distribution. Influence weights of samples are calculated based on maximum mean discrepancy (MMD) between the mean embeddings of sample distributions including and excluding the sample. Further, the influence factor of a sample is measured using MMD based on the shift in the distribution in the absence of that sample.
Influential Prototypical Networks for Few Shot Learning: A Dermatological Case Study
Nov 11, 2021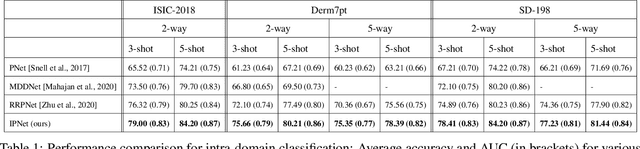
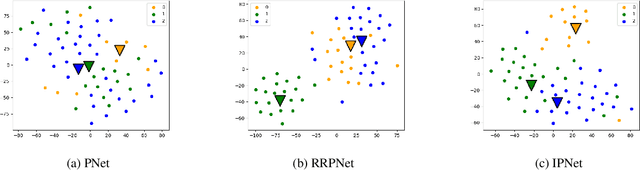
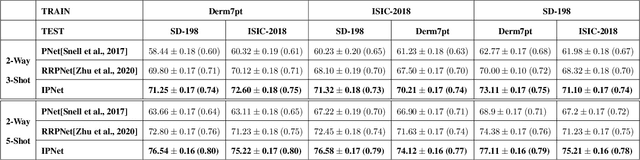
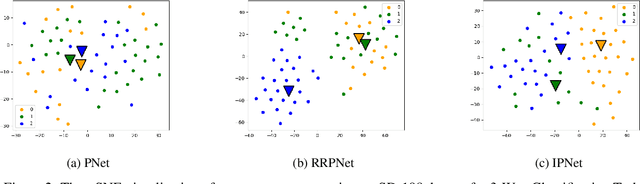
Prototypical network (PN) is a simple yet effective few shot learning strategy. It is a metric-based meta-learning technique where classification is performed by computing Euclidean distances to prototypical representations of each class. Conventional PN attributes equal importance to all samples and generates prototypes by simply averaging the support sample embeddings belonging to each class. In this work, we propose a novel version of PN that attributes weights to support samples corresponding to their influence on the support sample distribution. Influence weights of samples are calculated based on maximum mean discrepancy (MMD) between the mean embeddings of sample distributions including and excluding the sample. Comprehensive evaluation of our proposed influential PN (IPNet) is performed by comparing its performance with other baseline PNs on three different benchmark dermatological datasets. IPNet outperforms all baseline models with compelling results across all three datasets and various N-way, K-shot classification tasks. Findings from cross-domain adaptation experiments further establish the robustness and generalizability of IPNet.
FES: A Fast Efficient Scalable QoS Prediction Framework
Mar 16, 2021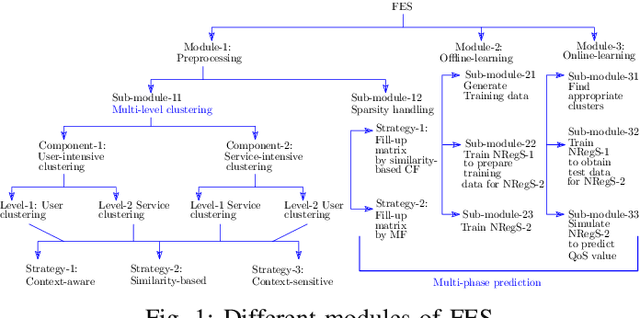
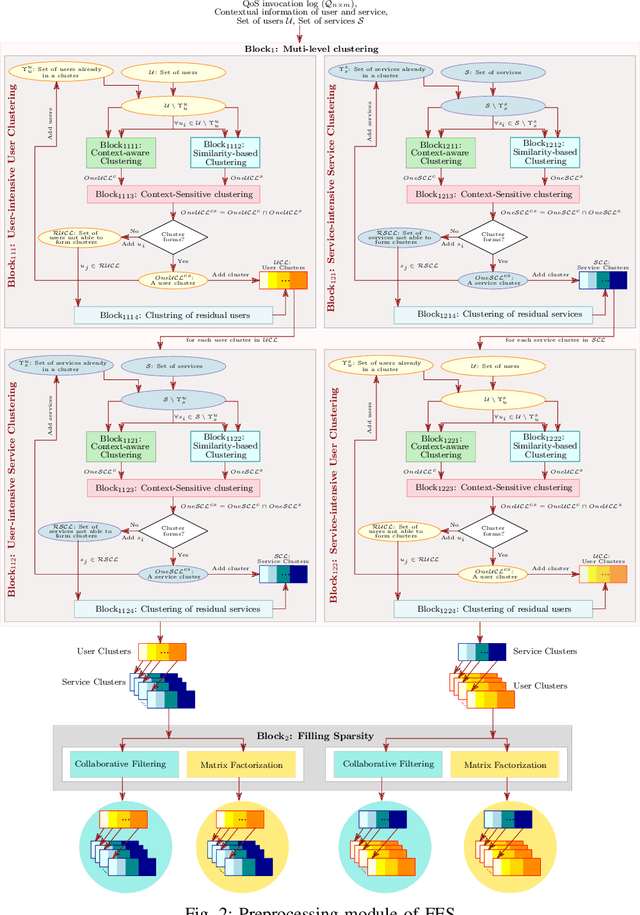
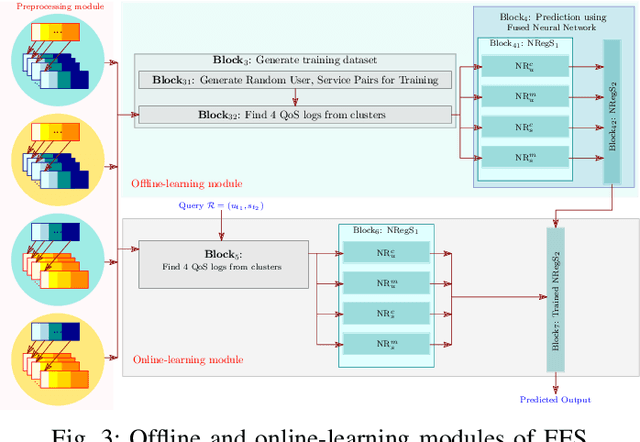
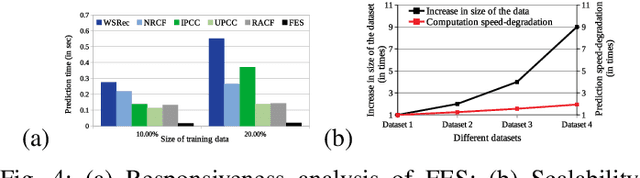
Quality-of-Service prediction of web service is an integral part of services computing due to its diverse applications in the various facets of a service life cycle, such as service composition, service selection, service recommendation. One of the primary objectives of designing a QoS prediction algorithm is to achieve satisfactory prediction accuracy. However, accuracy is not the only criteria to meet while developing a QoS prediction algorithm. The algorithm has to be faster in terms of prediction time so that it can be integrated into a real-time recommendation or composition system. The other important factor to consider while designing the prediction algorithm is scalability to ensure that the prediction algorithm can tackle large-scale datasets. The existing algorithms on QoS prediction often compromise on one goal while ensuring the others. In this paper, we propose a semi-offline QoS prediction model to achieve three important goals simultaneously: higher accuracy, faster prediction time, scalability. Here, we aim to predict the QoS value of service that varies across users. Our framework consists of multi-phase prediction algorithms: preprocessing-phase prediction, online prediction, and prediction using the pre-trained model. In the preprocessing phase, we first apply multi-level clustering on the dataset to obtain correlated users and services. We then preprocess the clusters using collaborative filtering to remove the sparsity of the given QoS invocation log matrix. Finally, we create a two-staged, semi-offline regression model using neural networks to predict the QoS value of service to be invoked by a user in real-time. Our experimental results on four publicly available WS-DREAM datasets show the efficiency in terms of accuracy, scalability, fast responsiveness of our framework as compared to the state-of-the-art methods.