 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSafeTail: Efficient Tail Latency Optimization in Edge Service Scheduling via Computational Redundancy Management
Paper and Code
Aug 30, 2024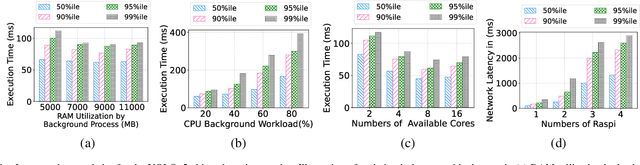
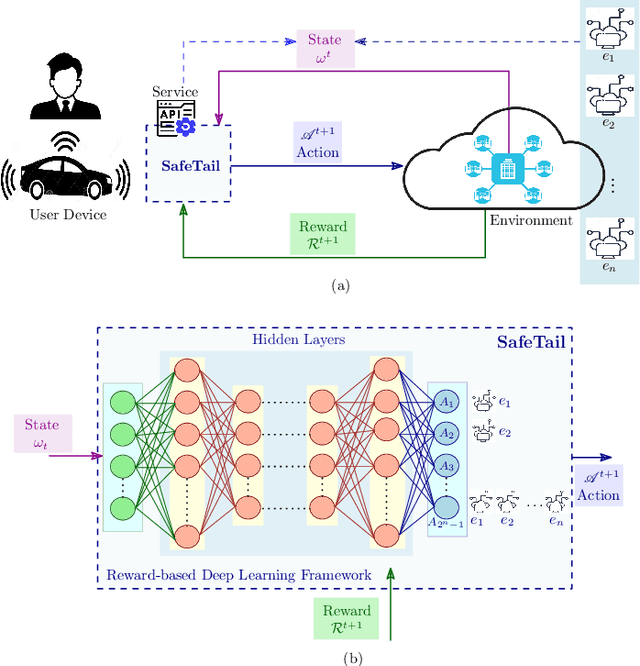
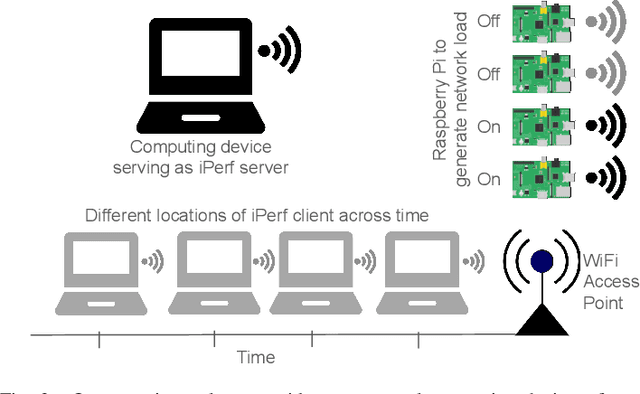
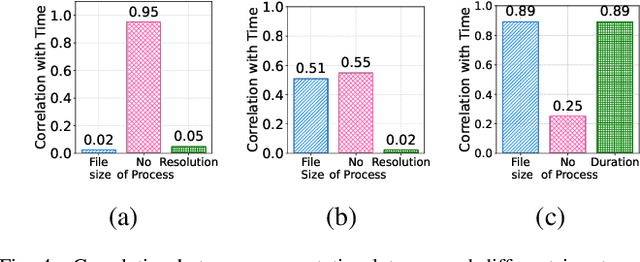
Optimizing tail latency while efficiently managing computational resources is crucial for delivering high-performance, latency-sensitive services in edge computing. Emerging applications, such as augmented reality, require low-latency computing services with high reliability on user devices, which often have limited computational capabilities. Consequently, these devices depend on nearby edge servers for processing. However, inherent uncertainties in network and computation latencies stemming from variability in wireless networks and fluctuating server loads make service delivery on time challenging. Existing approaches often focus on optimizing median latency but fall short of addressing the specific challenges of tail latency in edge environments, particularly under uncertain network and computational conditions. Although some methods do address tail latency, they typically rely on fixed or excessive redundancy and lack adaptability to dynamic network conditions, often being designed for cloud environments rather than the unique demands of edge computing. In this paper, we introduce SafeTail, a framework that meets both median and tail response time targets, with tail latency defined as latency beyond the 90^th percentile threshold. SafeTail addresses this challenge by selectively replicating services across multiple edge servers to meet target latencies. SafeTail employs a reward-based deep learning framework to learn optimal placement strategies, balancing the need to achieve target latencies with minimizing additional resource usage. Through trace-driven simulations, SafeTail demonstrated near-optimal performance and outperformed most baseline strategies across three diverse services.