 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReal-Time Retargeting Using Controllability Boundary for Chandrayaan-3 Lunar Landing
May 28, 2026This paper presents the real-time retargeting guidance policy developed for the Chandrayaan-3 lunar landing mission. The baseline guidance generates approximate fuel-optimal descent trajectories, while a high-level policy enables safe retargeting to alternate sites when the nominal site becomes infeasible. The retargeting strategy leverages a convex representation of the controllability boundary, allowing rapid feasibility checks and real-time target updates. To the best of the authors knowledge, this represents the first application of a data-driven retargeting framework in an operational lunar landing mission. Pre-flight simulations and Chandrayaan-3 flight results validate the effectiveness of the proposed approach.
Decoupled Thrust-Axis Attitude Control Using Quaternions for Chandrayaan-3 Lunar Landing Mission
May 28, 2026Chandrayaan-3 mission achieved a historic milestone with its successful soft landing near the lunar south pole, highlighting the critical role of the navigation, guidance, and control (NGC) system. Navigation provided vehicle state estimates relative to the Moon center, while a polynomial based guidance scheme computed the required acceleration profile to meet terminal landing conditions. This acceleration demand was translated into total thrust magnitude and attitude commands generation. Attitude command generation involved aligning the thrust axis with the required acceleration vector and constraining rotation about the thrust axis, typically governed by mission-specific requirements. Although quaternion-based control laws are preferred for their singularity-free representation, they inherently couple all three rotational axes. This coupling can lead to undesirable interactions between guidance and control, especially during large rotations about the thrust axis, due to the quaternion shortest-path property. This paper proposes a novel quaternion-based decoupling method that enables independent thrust-axis control, mitigating guidance-control interaction and ensuring proper attitude commands generation for lander attitude control.
Blurb-Refined Inference from Crowdsourced Book Reviews using Hierarchical Genre Mining with Dual-Path Graph Convolutions
Dec 24, 2025Accurate book genre classification is fundamental to digital library organization, content discovery, and personalized recommendation. Existing approaches typically model genre prediction as a flat, single-label task, ignoring hierarchical genre structure and relying heavily on noisy, subjective user reviews, which often degrade classification reliability. We propose HiGeMine, a two-phase hierarchical genre mining framework that robustly integrates user reviews with authoritative book blurbs. In the first phase, HiGeMine employs a zero-shot semantic alignment strategy to filter reviews, retaining only those semantically consistent with the corresponding blurb, thereby mitigating noise, bias, and irrelevance. In the second phase, we introduce a dual-path, two-level graph-based classification architecture: a coarse-grained Level-1 binary classifier distinguishes fiction from non-fiction, followed by Level-2 multi-label classifiers for fine-grained genre prediction. Inter-genre dependencies are explicitly modeled using a label co-occurrence graph, while contextual representations are derived from pretrained language models applied to the filtered textual content. To facilitate systematic evaluation, we curate a new hierarchical book genre dataset. Extensive experiments demonstrate that HiGeMine consistently outperformed strong baselines across hierarchical genre classification tasks. The proposed framework offers a principled and effective solution for leveraging both structured and unstructured textual data in hierarchical book genre analysis.
Agentic Multi-Persona Framework for Evidence-Aware Fake News Detection
Dec 24, 2025The rapid proliferation of online misinformation poses significant risks to public trust, policy, and safety, necessitating reliable automated fake news detection. Existing methods often struggle with multimodal content, domain generalization, and explainability. We propose AMPEND-LS, an agentic multi-persona evidence-grounded framework with LLM-SLM synergy for multimodal fake news detection. AMPEND-LS integrates textual, visual, and contextual signals through a structured reasoning pipeline powered by LLMs, augmented with reverse image search, knowledge graph paths, and persuasion strategy analysis. To improve reliability, we introduce a credibility fusion mechanism combining semantic similarity, domain trustworthiness, and temporal context, and a complementary SLM classifier to mitigate LLM uncertainty and hallucinations. Extensive experiments across three benchmark datasets demonstrate that AMPEND-LS consistently outperformed state-of-the-art baselines in accuracy, F1 score, and robustness. Qualitative case studies further highlight its transparent reasoning and resilience against evolving misinformation. This work advances the development of adaptive, explainable, and evidence-aware systems for safeguarding online information integrity.
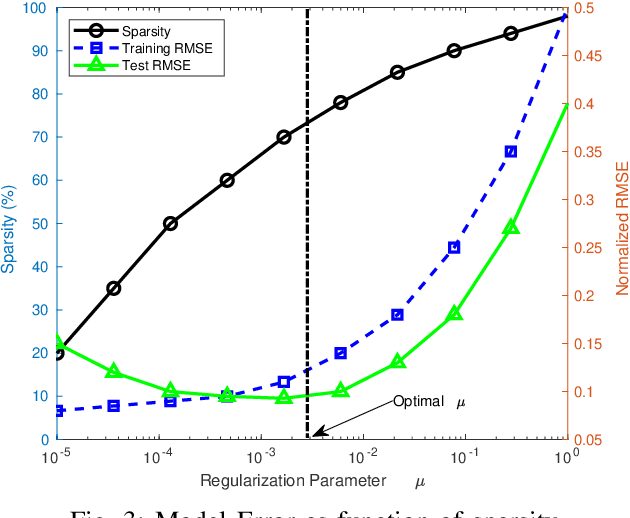
SHARP-QoS: Sparsely-gated Hierarchical Adaptive Routing for joint Prediction of QoS
Dec 19, 2025Dependable service-oriented computing relies on multiple Quality of Service (QoS) parameters that are essential to assess service optimality. However, real-world QoS data are extremely sparse, noisy, and shaped by hierarchical dependencies arising from QoS interactions, and geographical and network-level factors, making accurate QoS prediction challenging. Existing methods often predict each QoS parameter separately, requiring multiple similar models, which increases computational cost and leads to poor generalization. Although recent joint QoS prediction studies have explored shared architectures, they suffer from negative transfer due to loss-scaling caused by inconsistent numerical ranges across QoS parameters and further struggle with inadequate representation learning, resulting in degraded accuracy. This paper presents an unified strategy for joint QoS prediction, called SHARP-QoS, that addresses these issues using three components. First, we introduce a dual mechanism to extract the hierarchical features from both QoS and contextual structures via hyperbolic convolution formulated in the Poincaré ball. Second, we propose an adaptive feature-sharing mechanism that allows feature exchange across informative QoS and contextual signals. A gated feature fusion module is employed to support dynamic feature selection among structural and shared representations. Third, we design an EMA-based loss balancing strategy that allows stable joint optimization, thereby mitigating the negative transfer. Evaluations on three datasets with two, three, and four QoS parameters demonstrate that SHARP-QoS outperforms both single- and multi-task baselines. Extensive study shows that our model effectively addresses major challenges, including sparsity, robustness to outliers, and cold-start, while maintaining moderate computational overhead, underscoring its capability for reliable joint QoS prediction.
Learning based Modelling of Throttleable Engine Dynamics for Lunar Landing Mission
Nov 05, 2025


Typical lunar landing missions involve multiple phases of braking to achieve soft-landing. The propulsion system configuration for these missions consists of throttleable engines. This configuration involves complex interconnected hydraulic, mechanical, and pneumatic components each exhibiting non-linear dynamic characteristics. Accurate modelling of the propulsion dynamics is essential for analyzing closed-loop guidance and control schemes during descent. This paper presents a learning-based system identification approach for modelling of throttleable engine dynamics using data obtained from high-fidelity propulsion model. The developed model is validated with experimental results and used for closed-loop guidance and control simulations.
ProtoSiTex: Learning Semi-Interpretable Prototypes for Multi-label Text Classification
Oct 14, 2025



The surge in user-generated reviews has amplified the need for interpretable models that can provide fine-grained insights. Existing prototype-based models offer intuitive explanations but typically operate at coarse granularity (sentence or document level) and fail to address the multi-label nature of real-world text classification. We propose ProtoSiTex, a semi-interpretable framework designed for fine-grained multi-label text classification. ProtoSiTex employs a dual-phase alternating training strategy: an unsupervised prototype discovery phase that learns semantically coherent and diverse prototypes, and a supervised classification phase that maps these prototypes to class labels. A hierarchical loss function enforces consistency across sub-sentence, sentence, and document levels, enhancing interpretability and alignment. Unlike prior approaches, ProtoSiTex captures overlapping and conflicting semantics using adaptive prototypes and multi-head attention. We also introduce a benchmark dataset of hotel reviews annotated at the sub-sentence level with multiple labels. Experiments on this dataset and two public benchmarks (binary and multi-class) show that ProtoSiTex achieves state-of-the-art performance while delivering faithful, human-aligned explanations, establishing it as a robust solution for semi-interpretable multi-label text classification.
An Adaptive Data-Resilient Multi-Modal Framework for Hierarchical Multi-Label Book Genre Identification
May 05, 2025
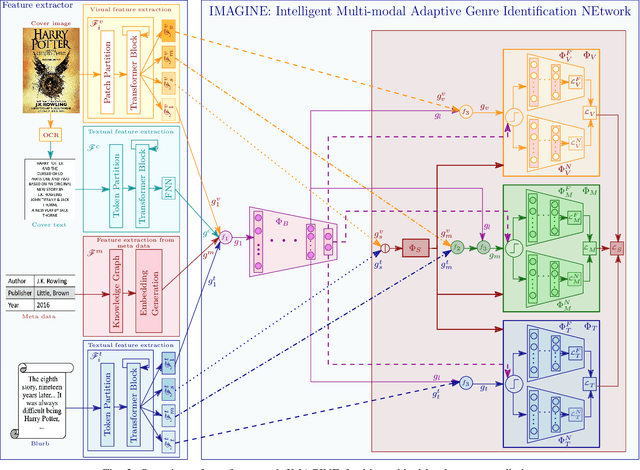


Identifying the finer details of a book's genres enhances user experience by enabling efficient book discovery and personalized recommendations, ultimately improving reader engagement and satisfaction. It also provides valuable insights into market trends and consumer preferences, allowing publishers and marketers to make data-driven decisions regarding book production and marketing strategies. While traditional book genre classification methods primarily rely on review data or textual analysis, incorporating additional modalities, such as book covers, blurbs, and metadata, can offer richer context and improve prediction accuracy. However, the presence of incomplete or noisy information across these modalities presents a significant challenge. This paper introduces IMAGINE (Intelligent Multi-modal Adaptive Genre Identification NEtwork), a framework designed to address these complexities. IMAGINE extracts robust feature representations from multiple modalities and dynamically selects the most informative sources based on data availability. It employs a hierarchical classification strategy to capture genre relationships and remains adaptable to varying input conditions. Additionally, we curate a hierarchical genre classification dataset that structures genres into a well-defined taxonomy, accommodating the diverse nature of literary works. IMAGINE integrates information from multiple sources and assigns multiple genre labels to each book, ensuring a more comprehensive classification. A key feature of our framework is its resilience to incomplete data, enabling accurate predictions even when certain modalities, such as text, images, or metadata, are missing or incomplete. Experimental results show that IMAGINE outperformed existing baselines in genre classification accuracy, particularly in scenarios with insufficient modality-specific data.
Anomaly Resilient Temporal QoS Prediction using Hypergraph Convoluted Transformer Network
Oct 23, 2024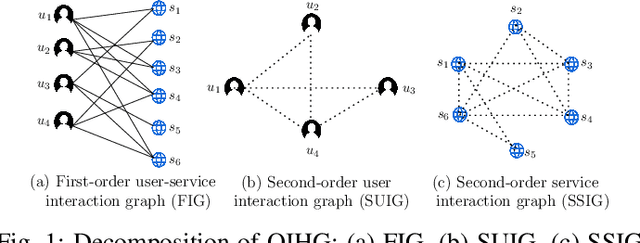
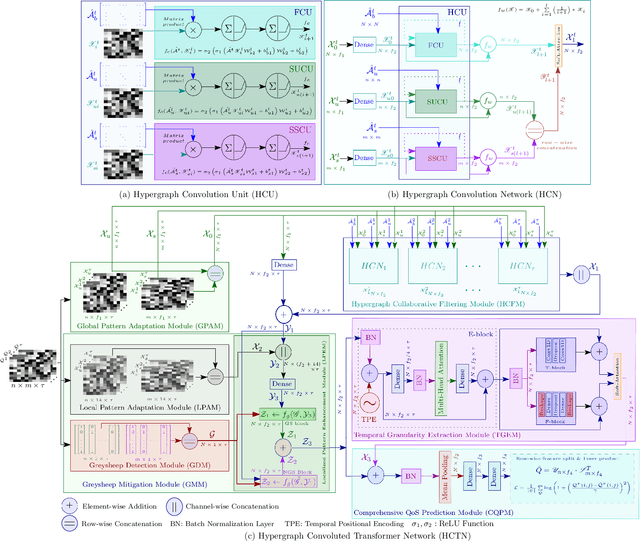
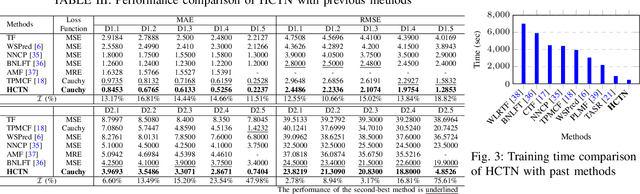
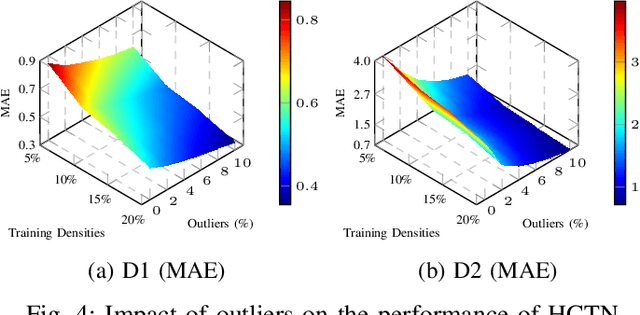
Quality-of-Service (QoS) prediction is a critical task in the service lifecycle, enabling precise and adaptive service recommendations by anticipating performance variations over time in response to evolving network uncertainties and user preferences. However, contemporary QoS prediction methods frequently encounter data sparsity and cold-start issues, which hinder accurate QoS predictions and limit the ability to capture diverse user preferences. Additionally, these methods often assume QoS data reliability, neglecting potential credibility issues such as outliers and the presence of greysheep users and services with atypical invocation patterns. Furthermore, traditional approaches fail to leverage diverse features, including domain-specific knowledge and complex higher-order patterns, essential for accurate QoS predictions. In this paper, we introduce a real-time, trust-aware framework for temporal QoS prediction to address the aforementioned challenges, featuring an end-to-end deep architecture called the Hypergraph Convoluted Transformer Network (HCTN). HCTN combines a hypergraph structure with graph convolution over hyper-edges to effectively address high-sparsity issues by capturing complex, high-order correlations. Complementing this, the transformer network utilizes multi-head attention along with parallel 1D convolutional layers and fully connected dense blocks to capture both fine-grained and coarse-grained dynamic patterns. Additionally, our approach includes a sparsity-resilient solution for detecting greysheep users and services, incorporating their unique characteristics to improve prediction accuracy. Trained with a robust loss function resistant to outliers, HCTN demonstrated state-of-the-art performance on the large-scale WSDREAM-2 datasets for response time and throughput.
Discrete time model predictive control for humanoid walking with step adjustment
Oct 09, 2024
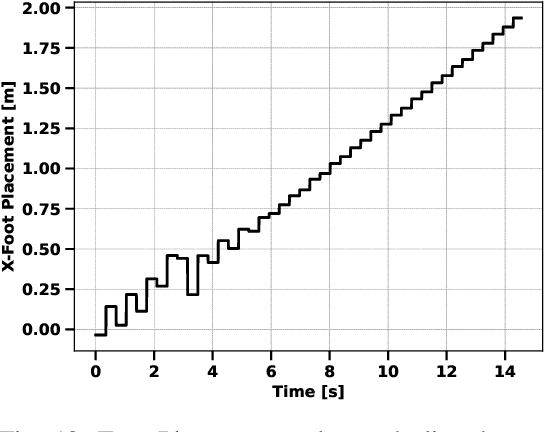
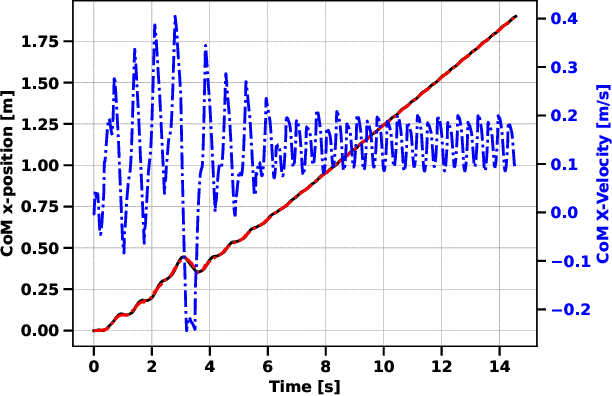
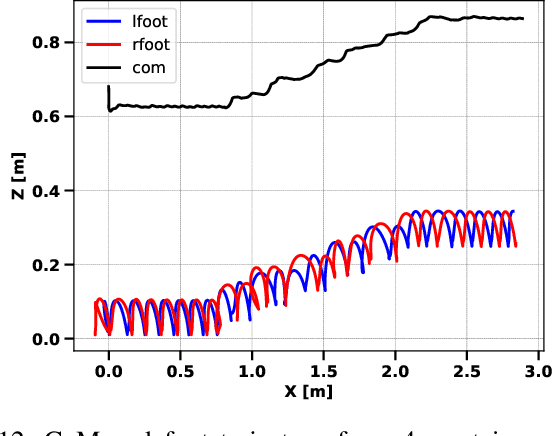
This paper presents a Discrete-Time Model Predictive Controller (MPC) for humanoid walking with online footstep adjustment. The proposed controller utilizes a hierarchical control approach. The high-level controller uses a low-dimensional Linear Inverted Pendulum Model (LIPM) to determine desired foot placement and Center of Mass (CoM) motion, to prevent falls while maintaining the desired velocity. A Task Space Controller (TSC) then tracks the desired motion obtained from the high-level controller, exploiting the whole-body dynamics of the humanoid. Our approach differs from existing MPC methods for walking pattern generation by not relying on a predefined foot-plan or a reference center of pressure (CoP) trajectory. The overall approach is tested in simulation on a torque-controlled Humanoid Robot. Results show that proposed control approach generates stable walking and prevents fall against push disturbances.