 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepMSRF: A novel Deep Multimodal Speaker Recognition framework with Feature selection
Paper and Code
Jul 21, 2020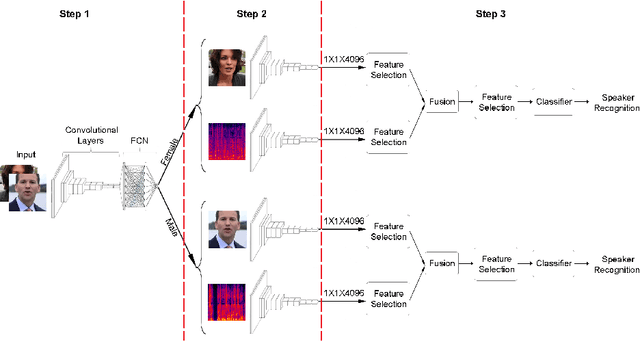
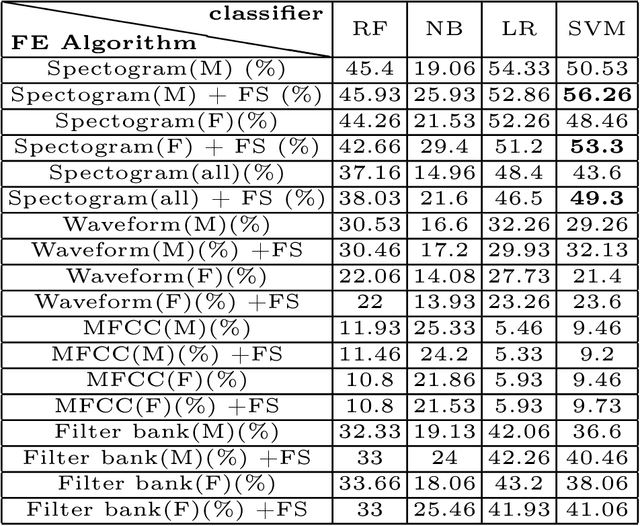
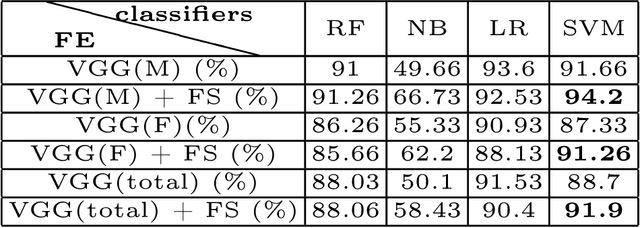
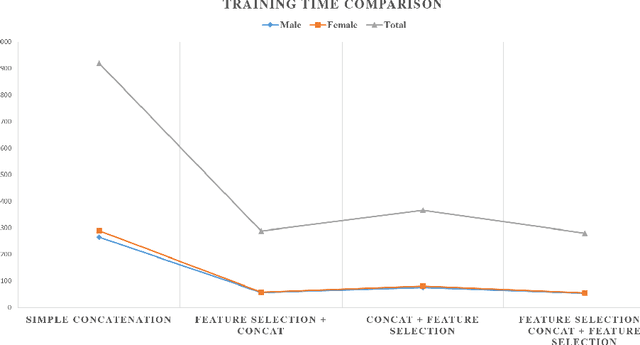
For recognizing speakers in video streams, significant research studies have been made to obtain a rich machine learning model by extracting high-level speaker's features such as facial expression, emotion, and gender. However, generating such a model is not feasible by using only single modality feature extractors that exploit either audio signals or image frames, extracted from video streams. In this paper, we address this problem from a different perspective and propose an unprecedented multimodality data fusion framework called DeepMSRF, Deep Multimodal Speaker Recognition with Feature selection. We execute DeepMSRF by feeding features of the two modalities, namely speakers' audios and face images. DeepMSRF uses a two-stream VGGNET to train on both modalities to reach a comprehensive model capable of accurately recognizing the speaker's identity. We apply DeepMSRF on a subset of VoxCeleb2 dataset with its metadata merged with VGGFace2 dataset. The goal of DeepMSRF is to identify the gender of the speaker first, and further to recognize his or her name for any given video stream. The experimental results illustrate that DeepMSRF outperforms single modality speaker recognition methods with at least 3 percent accuracy.