 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComparing Machine Learning Techniques for Alfalfa Biomass Yield Prediction
Oct 20, 2022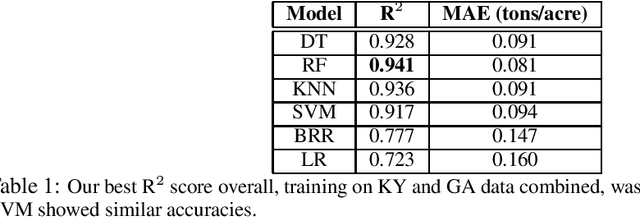
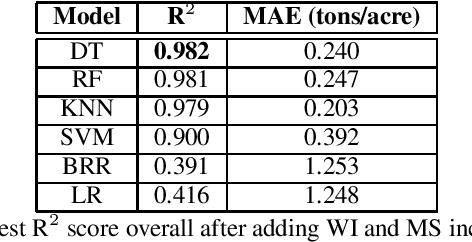
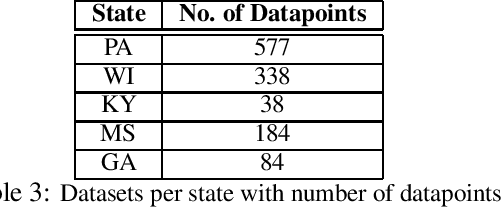
The alfalfa crop is globally important as livestock feed, so highly efficient planting and harvesting could benefit many industries, especially as the global climate changes and traditional methods become less accurate. Recent work using machine learning (ML) to predict yields for alfalfa and other crops has shown promise. Previous efforts used remote sensing, weather, planting, and soil data to train machine learning models for yield prediction. However, while remote sensing works well, the models require large amounts of data and cannot make predictions until the harvesting season begins. Using weather and planting data from alfalfa variety trials in Kentucky and Georgia, our previous work compared feature selection techniques to find the best technique and best feature set. In this work, we trained a variety of machine learning models, using cross validation for hyperparameter optimization, to predict biomass yields, and we showed better accuracy than similar work that employed more complex techniques. Our best individual model was a random forest with a mean absolute error of 0.081 tons/acre and R{$^2$} of 0.941. Next, we expanded this dataset to include Wisconsin and Mississippi, and we repeated our experiments, obtaining a higher best R{$^2$} of 0.982 with a regression tree. We then isolated our testing datasets by state to explore this problem's eligibility for domain adaptation (DA), as we trained on multiple source states and tested on one target state. This Trivial DA (TDA) approach leaves plenty of room for improvement through exploring more complex DA techniques in forthcoming work.