 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResolving Primitive-Sharing Ambiguity in Long-Tailed Industrial Point Cloud Segmentation via Spatial Context Constraints
Jan 27, 2026Industrial point cloud segmentation for Digital Twin construction faces a persistent challenge: safety-critical components such as reducers and valves are systematically misclassified. These failures stem from two compounding factors: such components are rare in training data, yet they share identical local geometry with dominant structures like pipes. This work identifies a dual crisis unique to industrial 3D data extreme class imbalance 215:1 ratio compounded by geometric ambiguity where most tail classes share cylindrical primitives with head classes. Existing frequency-based re-weighting methods address statistical imbalance but cannot resolve geometric ambiguity. We propose spatial context constraints that leverage neighborhood prediction consistency to disambiguate locally similar structures. Our approach extends the Class-Balanced (CB) Loss framework with two architecture-agnostic mechanisms: (1) Boundary-CB, an entropy-based constraint that emphasizes ambiguous boundaries, and (2) Density-CB, a density-based constraint that compensates for scan-dependent variations. Both integrate as plug-and-play modules without network modifications, requiring only loss function replacement. On the Industrial3D dataset (610M points from water treatment facilities), our method achieves 55.74% mIoU with 21.7% relative improvement on tail-class performance (29.59% vs. 24.32% baseline) while preserving head-class accuracy (88.14%). Components with primitive-sharing ambiguity show dramatic gains: reducer improves from 0% to 21.12% IoU; valve improves by 24.3% relative. This resolves geometric ambiguity without the typical head-tail trade-off, enabling reliable identification of safety-critical components for automated knowledge extraction in Digital Twin applications.
Multilingual Pretraining and Instruction Tuning Improve Cross-Lingual Knowledge Alignment, But Only Shallowly
Apr 06, 2024
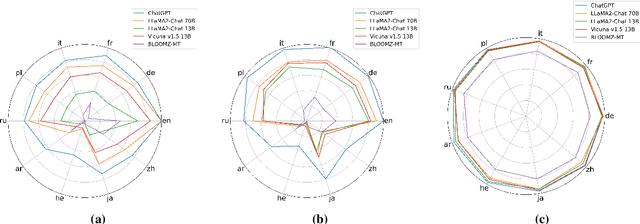


Despite their strong ability to retrieve knowledge in English, current large language models show imbalance abilities in different languages. Two approaches are proposed to address this, i.e., multilingual pretraining and multilingual instruction tuning. However, whether and how do such methods contribute to the cross-lingual knowledge alignment inside the models is unknown. In this paper, we propose CLiKA, a systematic framework to assess the cross-lingual knowledge alignment of LLMs in the Performance, Consistency and Conductivity levels, and explored the effect of multilingual pretraining and instruction tuning on the degree of alignment. Results show that: while both multilingual pretraining and instruction tuning are beneficial for cross-lingual knowledge alignment, the training strategy needs to be carefully designed. Namely, continued pretraining improves the alignment of the target language at the cost of other languages, while mixed pretraining affect other languages less. Also, the overall cross-lingual knowledge alignment, especially in the conductivity level, is unsatisfactory for all tested LLMs, and neither multilingual pretraining nor instruction tuning can substantially improve the cross-lingual knowledge conductivity.