 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChatGPT is a Potential Zero-Shot Dependency Parser
Oct 25, 2023
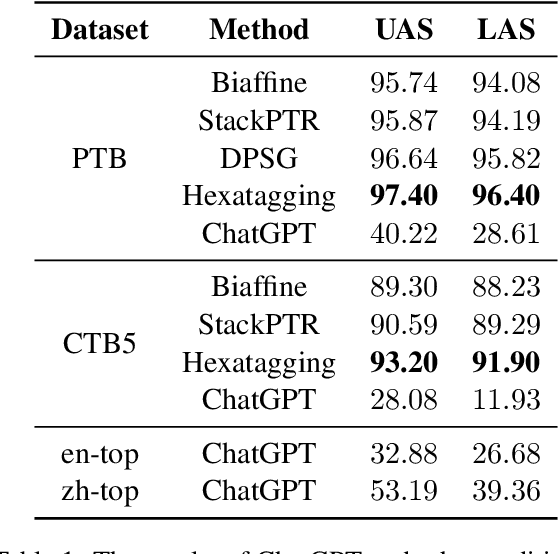
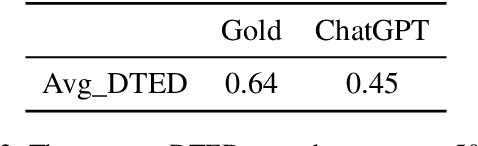

Pre-trained language models have been widely used in dependency parsing task and have achieved significant improvements in parser performance. However, it remains an understudied question whether pre-trained language models can spontaneously exhibit the ability of dependency parsing without introducing additional parser structure in the zero-shot scenario. In this paper, we propose to explore the dependency parsing ability of large language models such as ChatGPT and conduct linguistic analysis. The experimental results demonstrate that ChatGPT is a potential zero-shot dependency parser, and the linguistic analysis also shows some unique preferences in parsing outputs.
Type-aware Decoding via Explicitly Aggregating Event Information for Document-level Event Extraction
Oct 16, 2023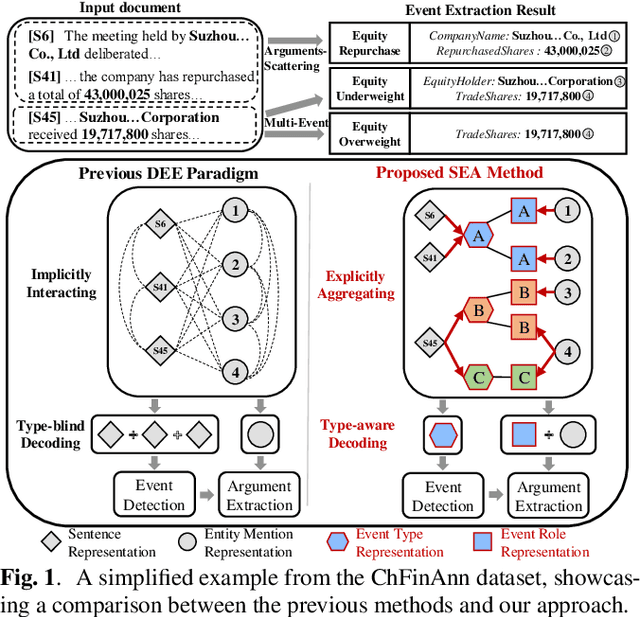



Document-level event extraction (DEE) faces two main challenges: arguments-scattering and multi-event. Although previous methods attempt to address these challenges, they overlook the interference of event-unrelated sentences during event detection and neglect the mutual interference of different event roles during argument extraction. Therefore, this paper proposes a novel Schema-based Explicitly Aggregating~(SEA) model to address these limitations. SEA aggregates event information into event type and role representations, enabling the decoding of event records based on specific type-aware representations. By detecting each event based on its event type representation, SEA mitigates the interference caused by event-unrelated information. Furthermore, SEA extracts arguments for each role based on its role-aware representations, reducing mutual interference between different roles. Experimental results on the ChFinAnn and DuEE-fin datasets show that SEA outperforms the SOTA methods.
DemoSG: Demonstration-enhanced Schema-guided Generation for Low-resource Event Extraction
Oct 16, 2023



Most current Event Extraction (EE) methods focus on the high-resource scenario, which requires a large amount of annotated data and can hardly be applied to low-resource domains. To address EE more effectively with limited resources, we propose the Demonstration-enhanced Schema-guided Generation (DemoSG) model, which benefits low-resource EE from two aspects: Firstly, we propose the demonstration-based learning paradigm for EE to fully use the annotated data, which transforms them into demonstrations to illustrate the extraction process and help the model learn effectively. Secondly, we formulate EE as a natural language generation task guided by schema-based prompts, thereby leveraging label semantics and promoting knowledge transfer in low-resource scenarios. We conduct extensive experiments under in-domain and domain adaptation low-resource settings on three datasets, and study the robustness of DemoSG. The results show that DemoSG significantly outperforms current methods in low-resource scenarios.