 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMROVSeg: Breaking the Resolution Curse of Vision-Language Models in Open-Vocabulary Semantic Segmentation
Aug 27, 2024
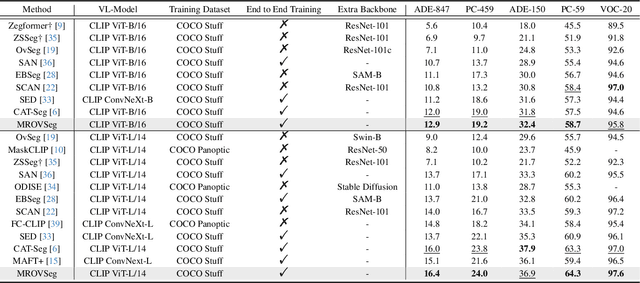

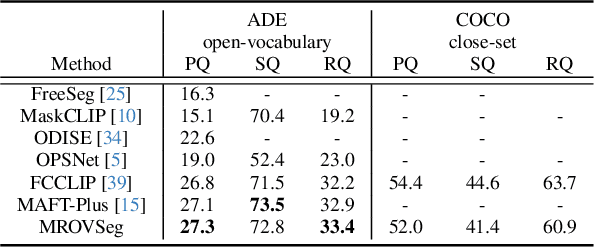
Open-vocabulary semantic segmentation aims to segment and recognize semantically meaningful regions based on text-based descriptions during inference. A typical solution to address this task is to leverage powerful vision-language models (VLMs), such as CLIP, to bridge the gap between open- and close-vocabulary recognition. As VLMs are usually pretrained with low-resolution images (e.g. $224\times224$), most previous methods operate only on downscaled images. We question this design as low resolution features often fail to preserve fine details. Although employing additional image backbones for high-resolution inputs can mitigate this issue, it may also introduce significant computation overhead. Therefore, we propose MROVSeg, a multi-resolution training framework for open-vocabulary semantic segmentation with a single pretrained CLIP backbone, that uses sliding windows to slice the high-resolution input into uniform patches, each matching the input size of the well-trained image encoder. Its key components include a Multi-Res Adapter, which restores the spatial geometry and grasps local-global correspondences across patches by learnable convolutional and scale attention layers. To achieve accurate segmentation, we introduce Multi-grained Masked Attention scheme to aggregate multi-grained semantics by performing cross-attention between object queries and multi-resolution CLIP features within the region of interests. Through comprehensive experiments, we demonstrate the superiority of MROVSeg on well-established open-vocabulary semantic segmentation benchmarks, particularly for high-resolution inputs, establishing new standards for open-vocabulary semantic segmentation.