 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSignal-SGN: A Spiking Graph Convolutional Network for Skeletal Action Recognition via Learning Temporal-Frequency Dynamics
Paper and Code
Aug 03, 2024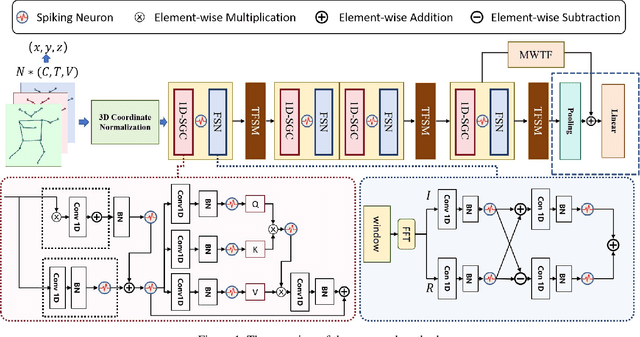
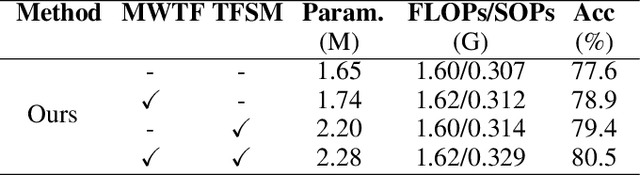
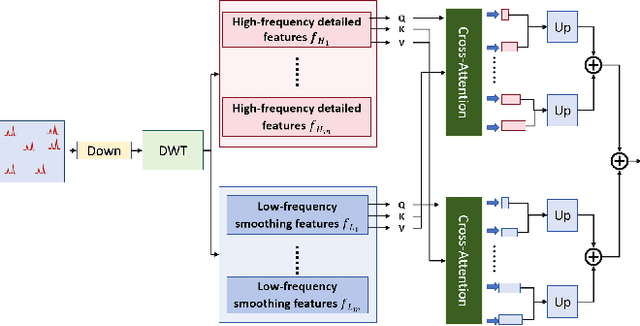
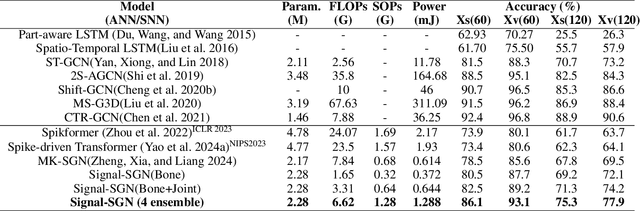
In skeletal-based action recognition, Graph Convolutional Networks (GCNs) based methods face limitations due to their complexity and high energy consumption. Spiking Neural Networks (SNNs) have gained attention in recent years for their low energy consumption, but existing methods combining GCNs and SNNs fail to fully utilize the temporal characteristics of skeletal sequences, leading to increased storage and computational costs. To address this issue, we propose a Signal-SGN(Spiking Graph Convolutional Network), which leverages the temporal dimension of skeletal sequences as the spiking timestep and treats features as discrete stochastic signals. The core of the network consists of a 1D Spiking Graph Convolutional Network (1D-SGN) and a Frequency Spiking Convolutional Network (FSN). The SGN performs graph convolution on single frames and incorporates spiking network characteristics to capture inter-frame temporal relationships, while the FSN uses Fast Fourier Transform (FFT) and complex convolution to extract temporal-frequency features. We also introduce a multi-scale wavelet transform feature fusion module(MWTF) to capture spectral features of temporal signals, enhancing the model's classification capability. We propose a pluggable temporal-frequency spatial semantic feature extraction module(TFSM) to enhance the model's ability to distinguish features without increasing inference-phase consumption. Our numerous experiments on the NTU RGB+D, NTU RGB+D 120, and NW-UCLA datasets demonstrate that the proposed models not only surpass existing SNN-based methods in accuracy but also reduce computational and storage costs during training. Furthermore, they achieve competitive accuracy compared to corresponding GCN-based methods, which is quite remarkable.