 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImplicit Subgoal Planning with Variational Autoencoders for Long-Horizon Sparse Reward Robotic Tasks
Dec 25, 2023



The challenges inherent to long-horizon tasks in robotics persist due to the typical inefficient exploration and sparse rewards in traditional reinforcement learning approaches. To alleviate these challenges, we introduce a novel algorithm, Variational Autoencoder-based Subgoal Inference (VAESI), to accomplish long-horizon tasks through a divide-and-conquer manner. VAESI consists of three components: a Variational Autoencoder (VAE)-based Subgoal Generator, a Hindsight Sampler, and a Value Selector. The VAE-based Subgoal Generator draws inspiration from the human capacity to infer subgoals and reason about the final goal in the context of these subgoals. It is composed of an explicit encoder model, engineered to generate subgoals, and an implicit decoder model, designed to enhance the quality of the generated subgoals by predicting the final goal. Additionally, the Hindsight Sampler selects valid subgoals from an offline dataset to enhance the feasibility of the generated subgoals. The Value Selector utilizes the value function in reinforcement learning to filter the optimal subgoals from subgoal candidates. To validate our method, we conduct several long-horizon tasks in both simulation and the real world, including one locomotion task and three manipulation tasks. The obtained quantitative and qualitative data indicate that our approach achieves promising performance compared to other baseline methods. These experimental results can be seen in the website \url{https://sites.google.com/view/vaesi/home}.
PSO-Based Optimal Coverage Path Planning for Surface Defect Inspection of 3C Components with a Robotic Line Scanner
Jul 10, 2023



The automatic inspection of surface defects is an important task for quality control in the computers, communications, and consumer electronics (3C) industry. Conventional devices for defect inspection (viz. line-scan sensors) have a limited field of view, thus, a robot-aided defect inspection system needs to scan the object from multiple viewpoints. Optimally selecting the robot's viewpoints and planning a path is regarded as coverage path planning (CPP), a problem that enables inspecting the object's complete surface while reducing the scanning time and avoiding misdetection of defects. However, the development of CPP strategies for robotic line scanners has not been sufficiently studied by researchers. To fill this gap in the literature, in this paper, we present a new approach for robotic line scanners to detect surface defects of 3C free-form objects automatically. Our proposed solution consists of generating a local path by a new hybrid region segmentation method and an adaptive planning algorithm to ensure the coverage of the complete object surface. An optimization method for the global path sequence is developed to maximize the scanning efficiency. To verify our proposed methodology, we conduct detailed simulation-based and experimental studies on various free-form workpieces, and compare its performance with a state-of-the-art solution. The reported results demonstrate the feasibility and effectiveness of our approach.
Efficient Robot Skill Learning with Imitation from a Single Video for Contact-Rich Fabric Manipulation
Apr 24, 2023



Classical policy search algorithms for robotics typically require performing extensive explorations, which are time-consuming and expensive to implement with real physical platforms. To facilitate the efficient learning of robot manipulation skills, in this work, we propose a new approach comprised of three modules: (1) learning of general prior knowledge with random explorations in simulation, including state representations, dynamic models, and the constrained action space of the task; (2) extraction of a state alignment-based reward function from a single demonstration video; (3) real-time optimization of the imitation policy under systematic safety constraints with sampling-based model predictive control. This solution results in an efficient one-shot imitation-from-video strategy that simplifies the learning and execution of robot skills in real applications. Specifically, we learn priors in a scene of a task family and then deploy the policy in a novel scene immediately following a single demonstration, preventing time-consuming and risky explorations in the environment. As we do not make a strong assumption of dynamic consistency between the scenes, learning priors can be conducted in simulation to avoid collecting data in real-world circumstances. We evaluate the effectiveness of our approach in the context of contact-rich fabric manipulation, which is a common scenario in industrial and domestic tasks. Detailed numerical simulations and real-world hardware experiments reveal that our method can achieve rapid skill acquisition for challenging manipulation tasks.
A Dual-Arm Collaborative Framework for Dexterous Manipulation in Unstructured Environments with Contrastive Planning
Sep 13, 2022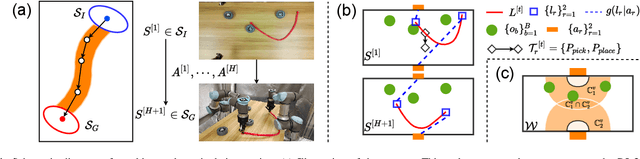
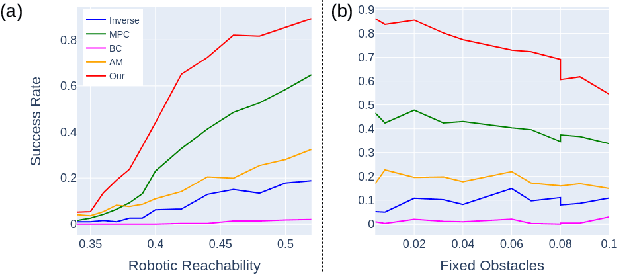
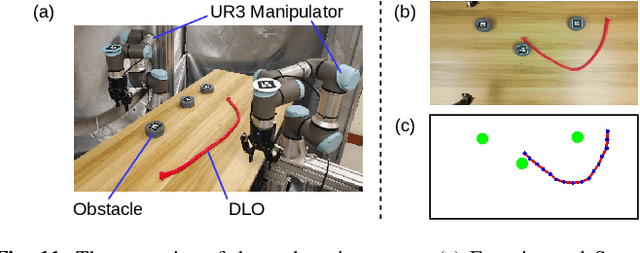
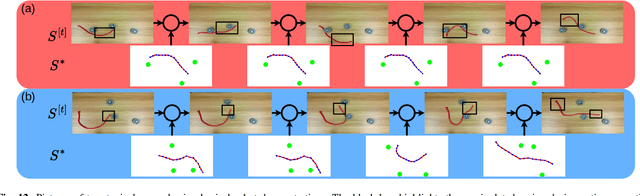
Most object manipulation strategies for robots are based on the assumption that the object is rigid (i.e., with fixed geometry) and the goal's details have been fully specified (e.g., the exact target pose). However, there are many tasks that involve spatial relations in human environments where these conditions may be hard to satisfy, e.g., bending and placing a cable inside an unknown container. To develop advanced robotic manipulation capabilities in unstructured environments that avoid these assumptions, we propose a novel long-horizon framework that exploits contrastive planning in finding promising collaborative actions. Using simulation data collected by random actions, we learn an embedding model in a contrastive manner that encodes the spatio-temporal information from successful experiences, which facilitates the subgoal planning through clustering in the latent space. Based on the keypoint correspondence-based action parameterization, we design a leader-follower control scheme for the collaboration between dual arms. All models of our policy are automatically trained in simulation and can be directly transferred to real-world environments. To validate the proposed framework, we conduct a detailed experimental study on a complex scenario subject to environmental and reachability constraints in both simulation and real environments.
Action Planning for Packing Long Linear Elastic Objects into Compact Boxes with Bimanual Robotic Manipulation
Oct 22, 2021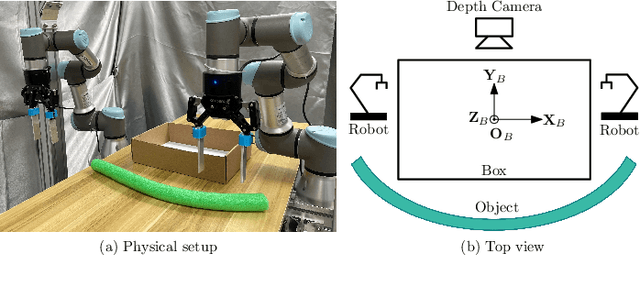
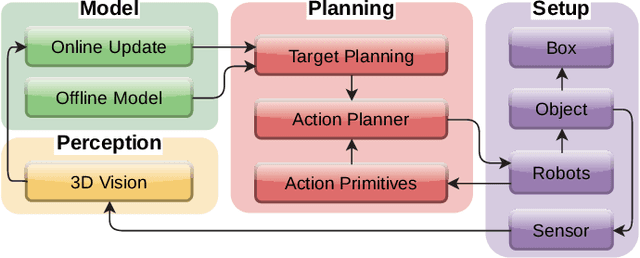
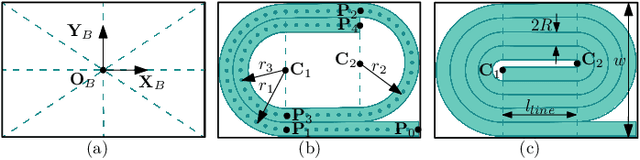
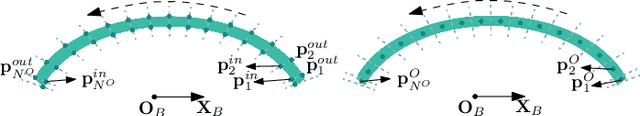
Automatic packing of objects is a critical component for efficient shipping in the Industry 4.0 era. Although robots have shown great success in pick-and-place operations with rigid products, the autonomous shaping and packing of elastic materials into compact boxes remains one of the most challenging problems in robotics; The automation of packing tasks is crucial at this moment given the accelerating shift towards e-commerce (which requires to manipulate multiple types of materials). In this paper, we propose a new action planning approach to automatically pack long linear elastic objects into common-size boxes with a bimanual robotic system. For that, we developed an efficient vision-based method to compute the objects' geometry and track its deformation in real-time and without special markers; The algorithm filters and orders the feedback point cloud that is captured by a depth sensor. A reference object model is introduced to plan the manipulation targets and to complete occluded parts of the object. Action primitives are used to construct high-level behaviors, which enable the execution of all packing steps. To validate the proposed theory, we conduct a detailed experimental study with multiple types and lengths of objects and packing boxes. The proposed methodology is original and its demonstrated manipulation capabilities have not (to the best of the authors knowledge) been previously reported in the literature.
Keypoint-Based Bimanual Shaping of Deformable Linear Objects under Environmental Constraints using Hierarchical Action Planning
Oct 18, 2021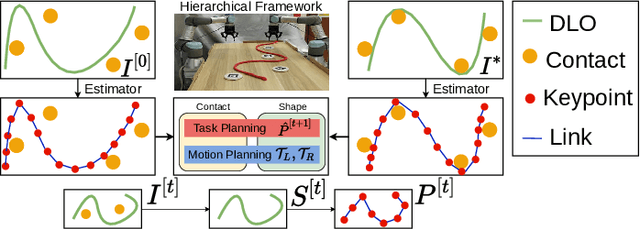
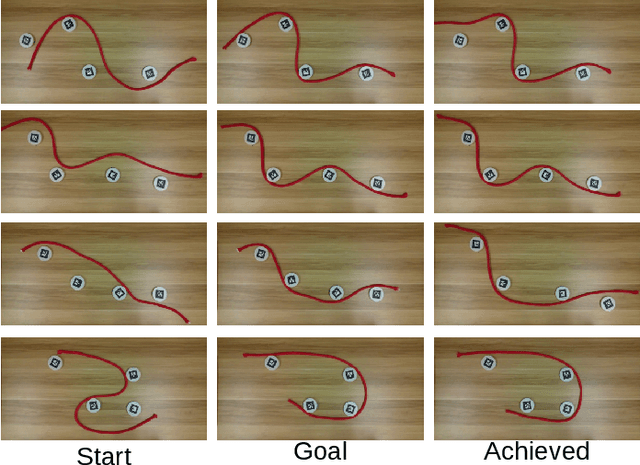
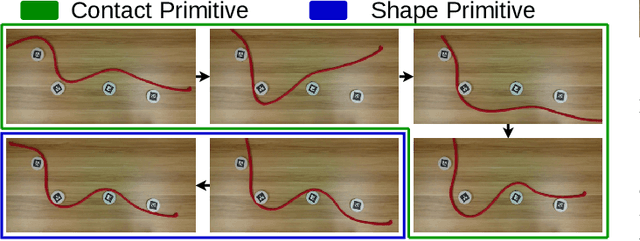
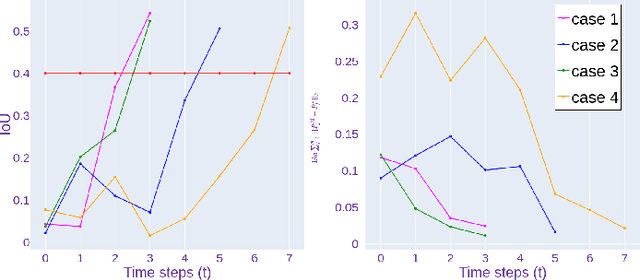
This paper addresses the problem of contact-based manipulation of deformable linear objects (DLOs) towards desired shapes with a dual-arm robotic system. To alleviate the burden of high-dimensional continuous state-action spaces, we model the DLO as a kinematic multibody system via our proposed keypoint detection network. This new perception network is trained on a synthetic labeled image dataset and transferred to real manipulation scenarios without conducting any manual annotations. Our goal-conditioned policy can efficiently learn to rearrange the configuration of the DLO based on the detected keypoints. The proposed hierarchical action framework tackles the manipulation problem in a coarse-to-fine manner (with high-level task planning and low-level motion control) by leveraging on two action primitives. The identification of deformation properties is avoided since the algorithm replans its motion after each bimanual execution. The conducted experimental results reveal that our method achieves high performance in state representation of the DLO, and is robust to uncertain environmental constraints.
Learning Cloth Folding Tasks with Refined Flow Based Spatio-Temporal Graphs
Oct 16, 2021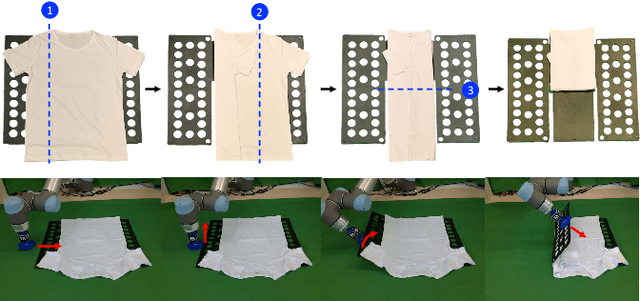
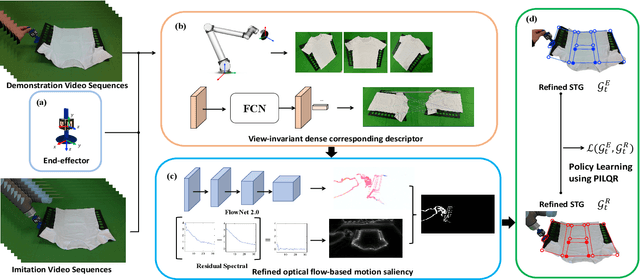
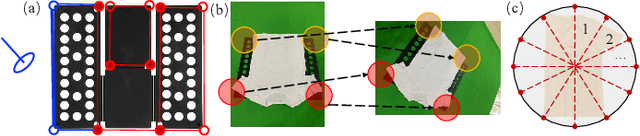
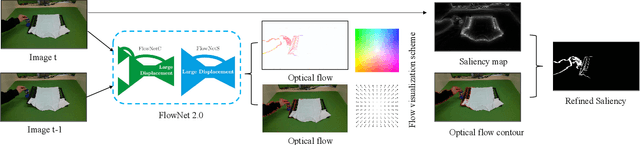
Cloth folding is a widespread domestic task that is seemingly performed by humans but which is highly challenging for autonomous robots to execute due to the highly deformable nature of textiles; It is hard to engineer and learn manipulation pipelines to efficiently execute it. In this paper, we propose a new solution for robotic cloth folding (using a standard folding board) via learning from demonstrations. Our demonstration video encoding is based on a high-level abstraction, namely, a refined optical flow-based spatiotemporal graph, as opposed to a low-level encoding such as image pixels. By constructing a new spatiotemporal graph with an advanced visual corresponding descriptor, the policy learning can focus on key points and relations with a 3D spatial configuration, which allows to quickly generalize across different environments. To further boost the policy searching, we combine optical flow and static motion saliency maps to discriminate the dominant motions for better handling the system dynamics in real-time, which aligns with the attentional motion mechanism that dominates the human imitation process. To validate the proposed approach, we analyze the manual folding procedure and developed a custom-made end-effector to efficiently interact with the folding board. Multiple experiments on a real robotic platform were conducted to validate the effectiveness and robustness of the proposed method.
LaSeSOM: A Latent Representation Framework for Semantic Soft Object Manipulation
Dec 10, 2020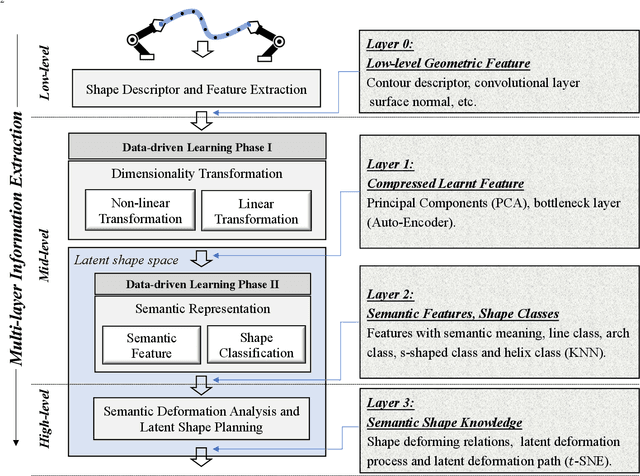
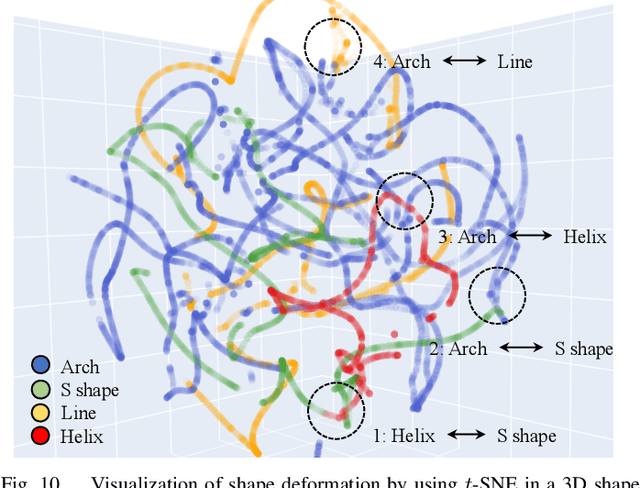
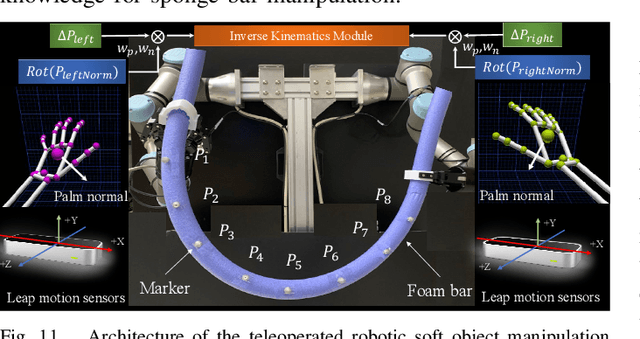

Soft object manipulation has recently gained popularity within the robotics community due to its potential applications in many economically important areas. Although great progress has been recently achieved in these types of tasks, most state-of-the-art methods are case-specific; They can only be used to perform a single deformation task (e.g. bending), as their shape representation algorithms typically rely on "hard-coded" features. In this paper, we present LaSeSOM, a new feedback latent representation framework for semantic soft object manipulation. Our new method introduces internal latent representation layers between low-level geometric feature extraction and high-level semantic shape analysis; This allows the identification of each compressed semantic function and the formation of a valid shape classifier from different feature extraction levels. The proposed latent framework makes soft object representation more generic (independent from the object's geometry and its mechanical properties) and scalable (it can work with 1D/2D/3D tasks). Its high-level semantic layer enables to perform (quasi) shape planning tasks with soft objects, a valuable and underexplored capability in many soft manipulation tasks. To validate this new methodology, we report a detailed experimental study with robotic manipulators.
A Robotic Line Scan System with Adaptive ROI for Inspection of Defects over Convex Free-form Specular Surfaces
Aug 25, 2020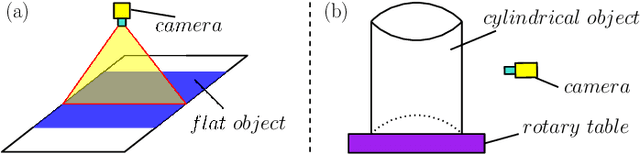
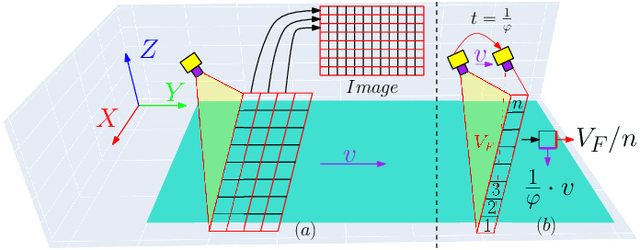
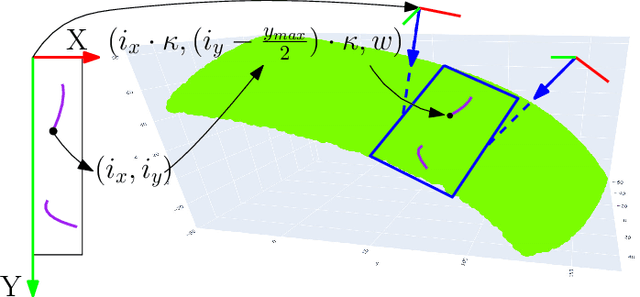
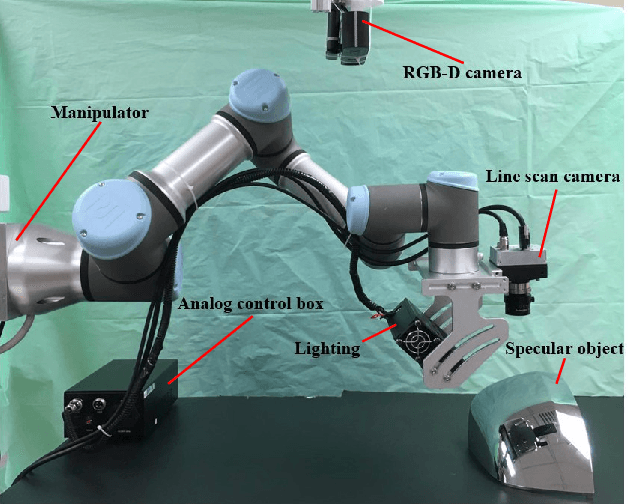
In this paper, we present a new robotic system to perform defect inspection tasks over free-form specular surfaces. The autonomous procedure is achieved by a six-DOF manipulator, equipped with a line scan camera and a high-intensity lighting system. Our method first uses the object's CAD mesh model to implement a K-means unsupervised learning algorithm that segments the object's surface into areas with similar curvature. Then, the scanning path is computed by using an adaptive algorithm that adjusts the camera's ROI to observe regions with irregular shapes properly. A novel iterative closest point-based projection registration method that robustly localizes the object in the robot's coordinate frame system is proposed to deal with the blind spot problem of specular objects captured by depth sensors. Finally, an image processing pipeline automatically detects surface defects in the captured high-resolution images. A detailed experimental study with a vision-guided robotic scanning system is reported to validate the proposed methodology.