 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAAN: Attributes-Aware Network for Temporal Action Detection
Paper and Code
Sep 01, 2023
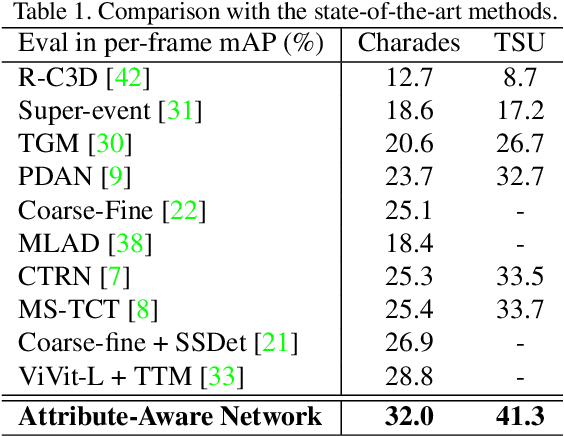
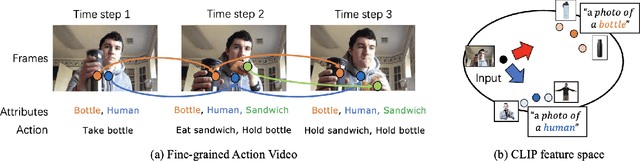
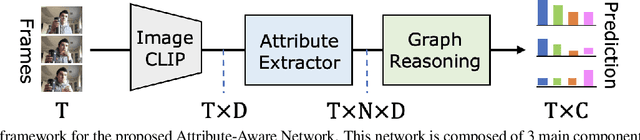
The challenge of long-term video understanding remains constrained by the efficient extraction of object semantics and the modelling of their relationships for downstream tasks. Although the CLIP visual features exhibit discriminative properties for various vision tasks, particularly in object encoding, they are suboptimal for long-term video understanding. To address this issue, we present the Attributes-Aware Network (AAN), which consists of two key components: the Attributes Extractor and a Graph Reasoning block. These components facilitate the extraction of object-centric attributes and the modelling of their relationships within the video. By leveraging CLIP features, AAN outperforms state-of-the-art approaches on two popular action detection datasets: Charades and Toyota Smarthome Untrimmed datasets.