 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNegation: A Pink Elephant in the Large Language Models' Room?
Mar 28, 2025



Negations are key to determining sentence meaning, making them essential for logical reasoning. Despite their importance, negations pose a substantial challenge for large language models (LLMs) and remain underexplored. We construct two multilingual natural language inference (NLI) datasets with \textit{paired} examples differing in negation. We investigate how model size and language impact its ability to handle negation correctly by evaluating popular LLMs. Contrary to previous work, we show that increasing the model size consistently improves the models' ability to handle negations. Furthermore, we find that both the models' reasoning accuracy and robustness to negation are language-dependent and that the length and explicitness of the premise have a greater impact on robustness than language. Our datasets can facilitate further research and improvements of language model reasoning in multilingual settings.
Concept-aware Data Construction Improves In-context Learning of Language Models
Mar 08, 2024Many recent language models (LMs) are capable of in-context learning (ICL), manifested in the LMs' ability to perform a new task solely from natural-language instruction. Previous work curating in-context learners assumes that ICL emerges from a vast over-parametrization or the scale of multi-task training. However, recent theoretical work attributes the ICL ability to concept-dependent training data and creates functional in-context learners even in small-scale, synthetic settings. In this work, we practically explore this newly identified axis of ICL quality. We propose Concept-aware Training (CoAT), a framework for constructing training scenarios that make it beneficial for the LM to learn to utilize the analogical reasoning concepts from demonstrations. We find that by using CoAT, pre-trained transformers can learn to better utilise new latent concepts from demonstrations and that such ability makes ICL more robust to the functional deficiencies of the previous models. Finally, we show that concept-aware in-context learning is more effective for a majority of new tasks when compared to traditional instruction tuning, resulting in a performance comparable to the previous in-context learners using magnitudes of more training data.
Think Twice: Measuring the Efficiency of Eliminating Prediction Shortcuts of Question Answering Models
May 11, 2023While the Large Language Models (LLMs) dominate a majority of language understanding tasks, previous work shows that some of these results are supported by modelling spurious correlations of training datasets. Authors commonly assess model robustness by evaluating their models on out-of-distribution (OOD) datasets of the same task, but these datasets might share the bias of the training dataset. We propose a simple method for measuring a scale of models' reliance on any identified spurious feature and assess the robustness towards a large set of known and newly found prediction biases for various pre-trained models and debiasing methods in Question Answering (QA). We find that the reported OOD gains of debiasing methods can not be explained by mitigated reliance on biased features, suggesting that biases are shared among QA datasets. We further evidence this by measuring that performance of OOD models depends on bias features comparably to the ID model, motivating future work to refine the reports of LLMs' robustness to a level of known spurious features.
Resources and Few-shot Learners for In-context Learning in Slavic Languages
Apr 04, 2023Despite the rapid recent progress in creating accurate and compact in-context learners, most recent work focuses on in-context learning (ICL) for tasks in English. However, the ability to interact with users of languages outside English presents a great potential for broadening the applicability of language technologies to non-English speakers. In this work, we collect the infrastructure necessary for training and evaluation of ICL in a selection of Slavic languages: Czech, Polish, and Russian. We link a diverse set of datasets and cast these into a unified instructional format through a set of transformations and newly-crafted templates written purely in target languages. Using the newly-curated dataset, we evaluate a set of the most recent in-context learners and compare their results to the supervised baselines. Finally, we train, evaluate and publish a set of in-context learning models that we train on the collected resources and compare their performance to previous work. We find that ICL models tuned in English are also able to learn some tasks from non-English contexts, but multilingual instruction fine-tuning consistently improves the ICL ability. We also find that the massive multitask training can be outperformed by single-task training in the target language, uncovering the potential for specializing in-context learners to the language(s) of their application.
Soft Alignment Objectives for Robust Adaptation in Machine Translation
Nov 29, 2022



Domain adaptation allows generative language models to address specific flaws caused by the domain shift of their application. However, the traditional adaptation by further training on in-domain data rapidly weakens the model's ability to generalize to other domains, making the open-ended deployments of the adapted models prone to errors. This work introduces novel training objectives built upon a semantic similarity of the predicted tokens to the reference. Our results show that (1) avoiding the common assumption of a single correct prediction by constructing the training target from tokens' semantic similarity can mitigate catastrophic forgetting during domain adaptation, while (2) preserving the quality of the adaptation, (3) with negligible additions to compute costs. In the broader perspective, the objectives grounded in a soft token alignment pioneer the exploration of the middle ground between the efficient but naive exact-match token-level objectives and expressive but computationally- and resource-intensive sequential objectives.
Interpretable Gait Recognition by Granger Causality
Jun 15, 2022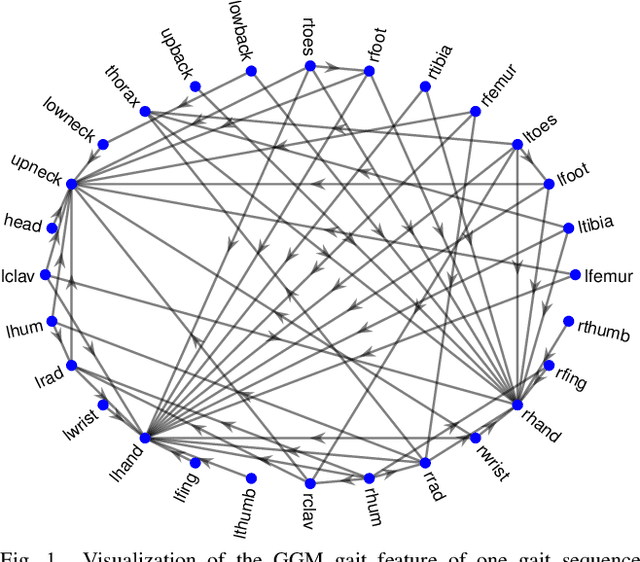
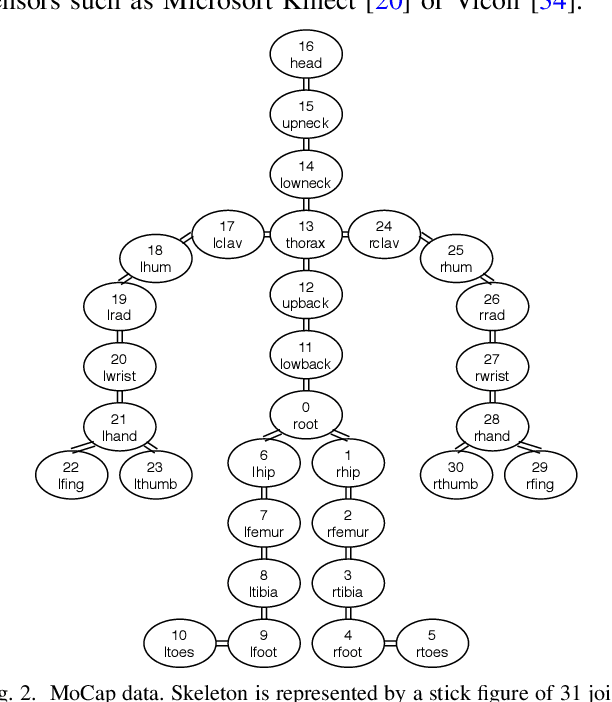
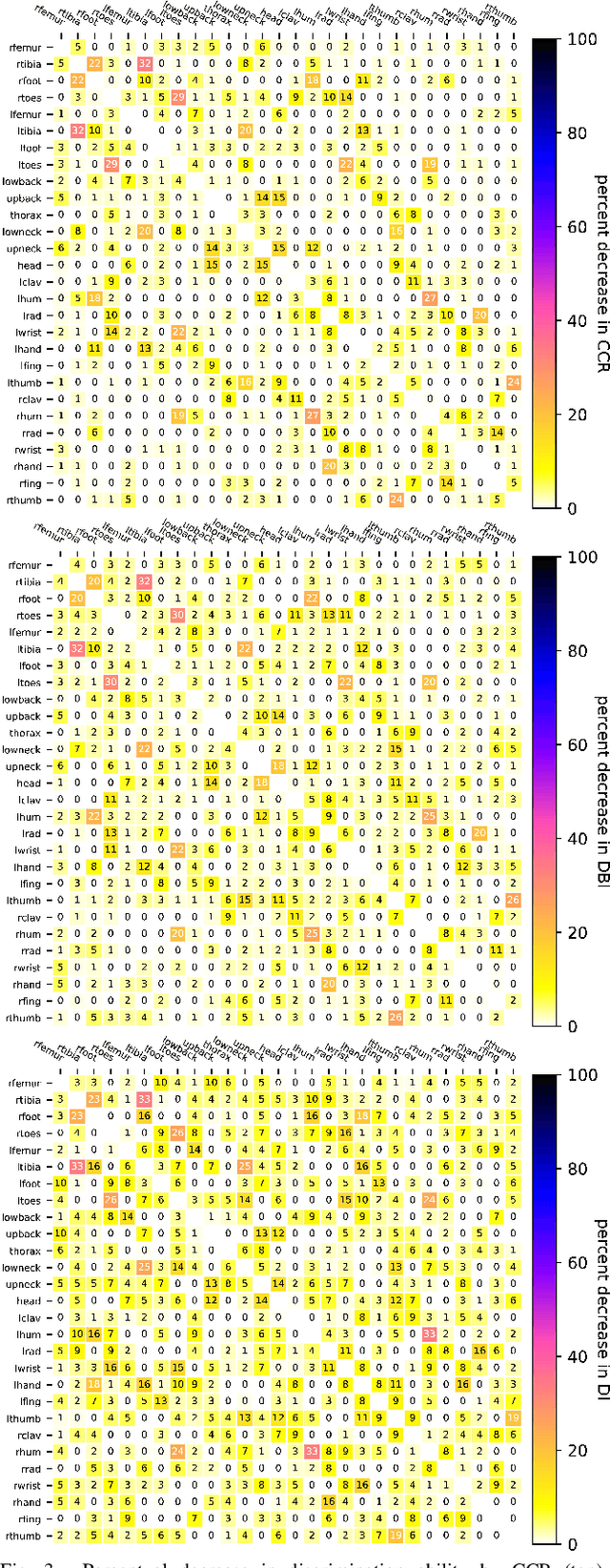
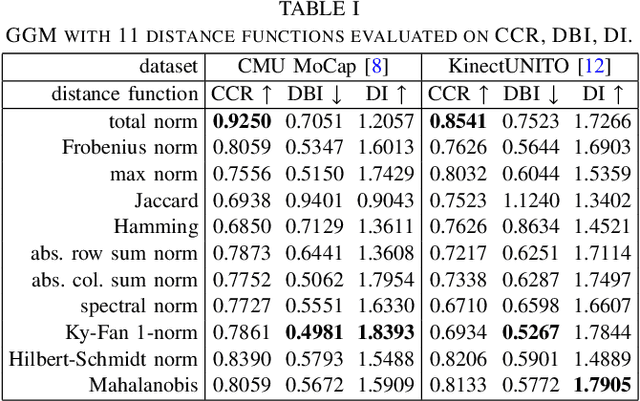
Which joint interactions in the human gait cycle can be used as biometric characteristics? Most current methods on gait recognition suffer from the lack of interpretability. We propose an interpretable feature representation of gait sequences by the graphical Granger causal inference. Gait sequence of a person in the standardized motion capture format, constituting a set of 3D joint spatial trajectories, is envisaged as a causal system of joints interacting in time. We apply the graphical Granger model (GGM) to obtain the so-called Granger causal graph among joints as a discriminative and visually interpretable representation of a person's gait. We evaluate eleven distance functions in the GGM feature space by established classification and class-separability evaluation metrics. Our experiments indicate that, depending on the metric, the most appropriate distance functions for the GGM are the total norm distance and the Ky-Fan 1-norm distance. Experiments also show that the GGM is able to detect the most discriminative joint interactions and that it outperforms five related interpretable models in correct classification rate and in Davies-Bouldin index. The proposed GGM model can serve as a complementary tool for gait analysis in kinesiology or for gait recognition in video surveillance.
Adapt$\mathcal{O}$r: Objective-Centric Adaptation Framework for Language Models
Mar 08, 2022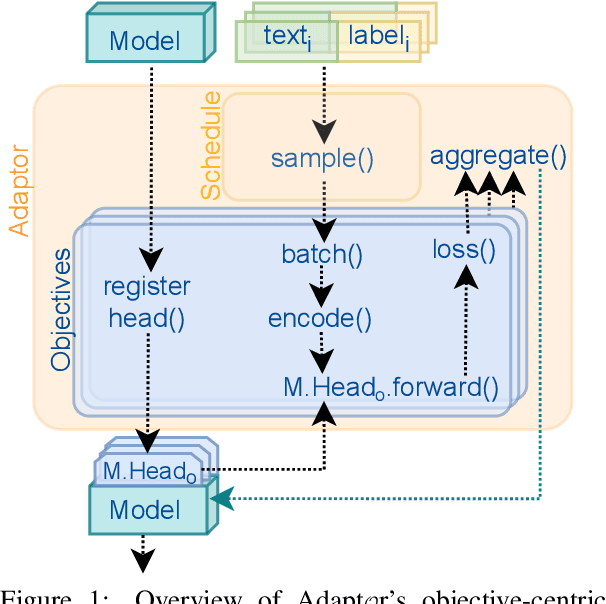


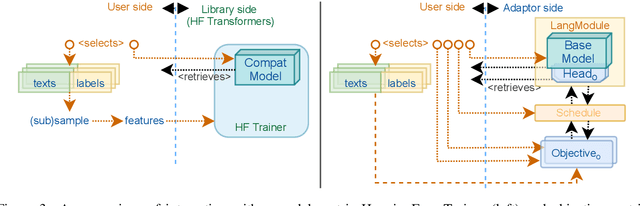
Progress in natural language processing research is catalyzed by the possibilities given by the widespread software frameworks. This paper introduces Adaptor library that transposes the traditional model-centric approach composed of pre-training + fine-tuning steps to objective-centric approach, composing the training process by applications of selected objectives. We survey research directions that can benefit from enhanced objective-centric experimentation in multitask training, custom objectives development, dynamic training curricula, or domain adaptation. Adaptor aims to ease reproducibility of these research directions in practice. Finally, we demonstrate the practical applicability of Adaptor in selected unsupervised domain adaptation scenarios.
Towards Math-Aware Automated Classification and Similarity Search of Scientific Publications: Methods of Mathematical Content Representations
Oct 08, 2021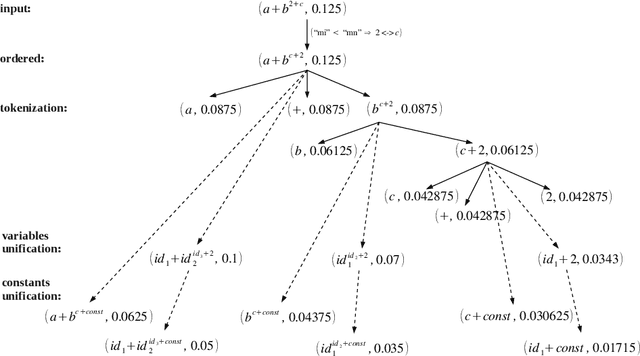
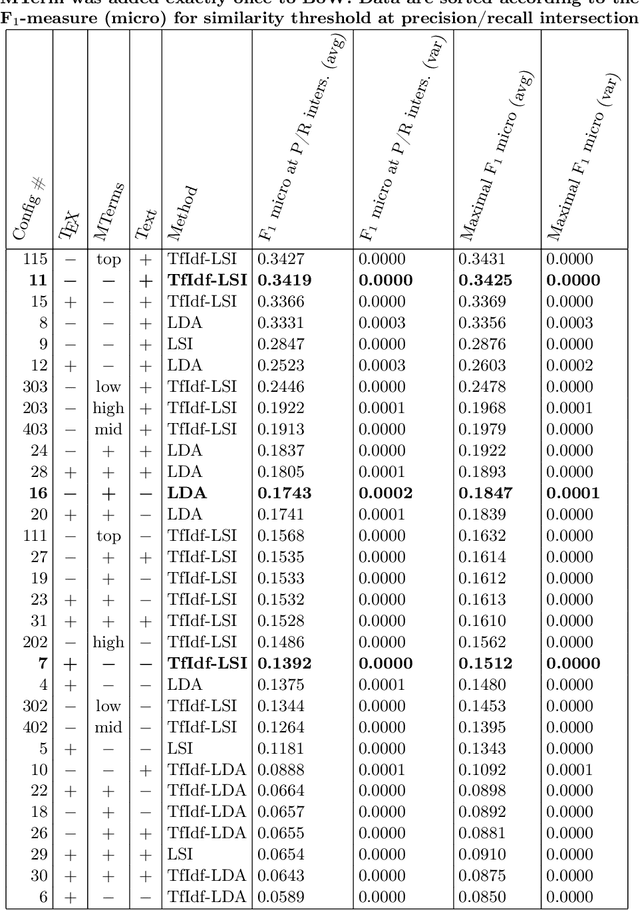

In this paper, we investigate mathematical content representations suitable for the automated classification of and the similarity search in STEM documents using standard machine learning algorithms: the Latent Dirichlet Allocation (LDA) and the Latent Semantic Indexing (LSI). The methods are evaluated on a subset of arXiv.org papers with the Mathematics Subject Classification (MSC) as a reference classification and using the standard precision/recall/F1-measure metrics. The results give insight into how different math representations may influence the performance of the classification and similarity search tasks in STEM repositories. Non-surprisingly, machine learning methods are able to grab distributional semantics from textual tokens. A proper selection of weighted tokens representing math may improve the quality of the results slightly. A structured math representation that imitates successful text-processing techniques with math is shown to yield better results than flat TeX tokens.
Regressive Ensemble for Machine Translation Quality Evaluation
Sep 15, 2021

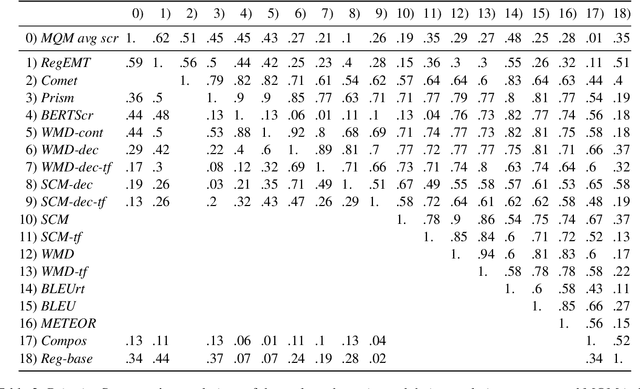
This work introduces a simple regressive ensemble for evaluating machine translation quality based on a set of novel and established metrics. We evaluate the ensemble using a correlation to expert-based MQM scores of the WMT 2021 Metrics workshop. In both monolingual and zero-shot cross-lingual settings, we show a significant performance improvement over single metrics. In the cross-lingual settings, we also demonstrate that an ensemble approach is well-applicable to unseen languages. Furthermore, we identify a strong reference-free baseline that consistently outperforms the commonly-used BLEU and METEOR measures and significantly improves our ensemble's performance.
WebMIaS on Docker: Deploying Math-Aware Search in a Single Line of Code
Jun 01, 2021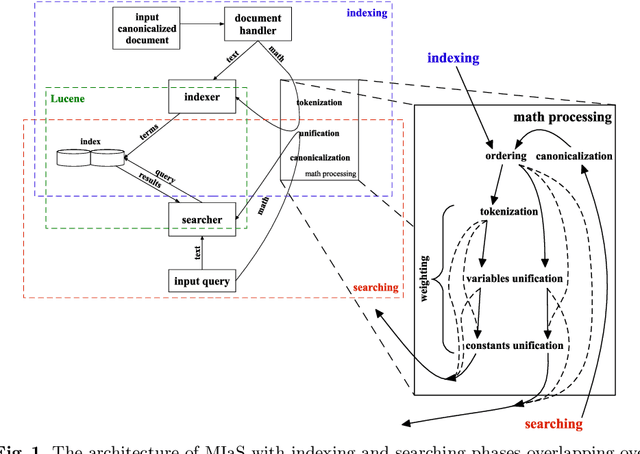
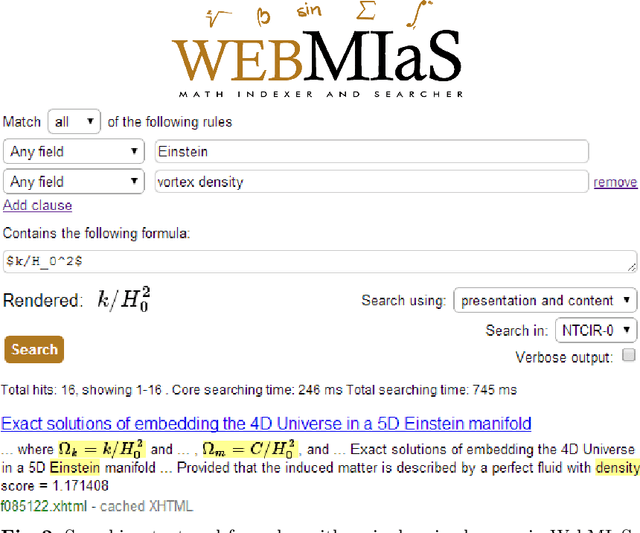


Math informational retrieval (MIR) search engines are absent in the wide-spread production use, even though documents in the STEM fields contain many mathematical formulae, which are sometimes more important than text for understanding. We have developed and open-sourced the WebMIaS MIR search engine that has been successfully deployed in the European Digital Mathematics Library (EuDML). However, its deployment is difficult to automate due to the complexity of this task. Moreover, the solutions developed so far to tackle this challenge are imperfect in terms of speed, maintenance, and robustness. In this paper, we will describe the virtualization of WebMIaS using Docker that solves all three problems and allows anyone to deploy containerized WebMIaS in a single line of code. The publicly available Docker image will also help the community push the development of math-aware search engines in the ARQMath workshop series.