 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWebMIaS on Docker: Deploying Math-Aware Search in a Single Line of Code
Jun 01, 2021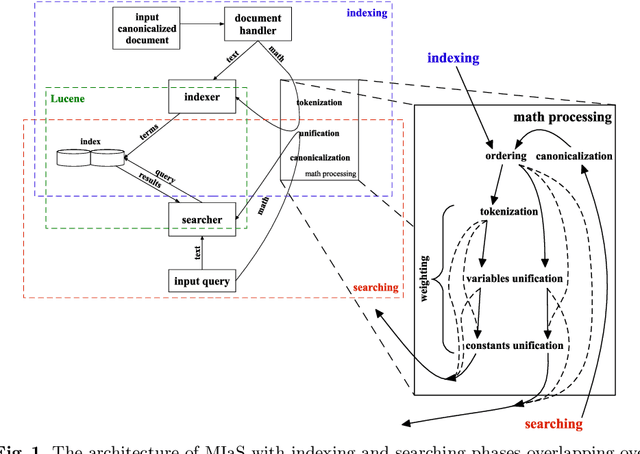
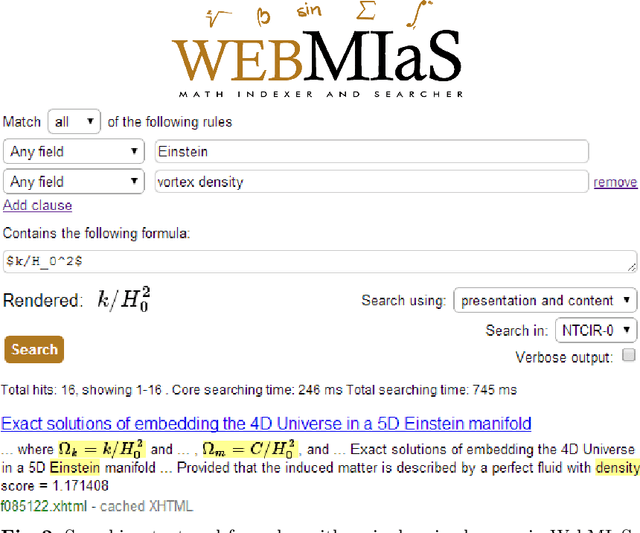


Math informational retrieval (MIR) search engines are absent in the wide-spread production use, even though documents in the STEM fields contain many mathematical formulae, which are sometimes more important than text for understanding. We have developed and open-sourced the WebMIaS MIR search engine that has been successfully deployed in the European Digital Mathematics Library (EuDML). However, its deployment is difficult to automate due to the complexity of this task. Moreover, the solutions developed so far to tackle this challenge are imperfect in terms of speed, maintenance, and robustness. In this paper, we will describe the virtualization of WebMIaS using Docker that solves all three problems and allows anyone to deploy containerized WebMIaS in a single line of code. The publicly available Docker image will also help the community push the development of math-aware search engines in the ARQMath workshop series.
One Size Does Not Fit All: Finding the Optimal N-gram Sizes for FastText Models across Languages
Feb 04, 2021

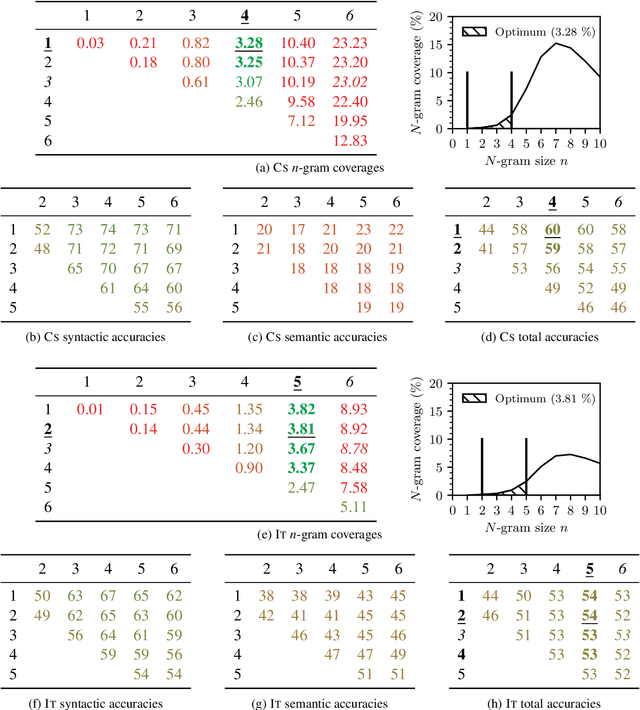
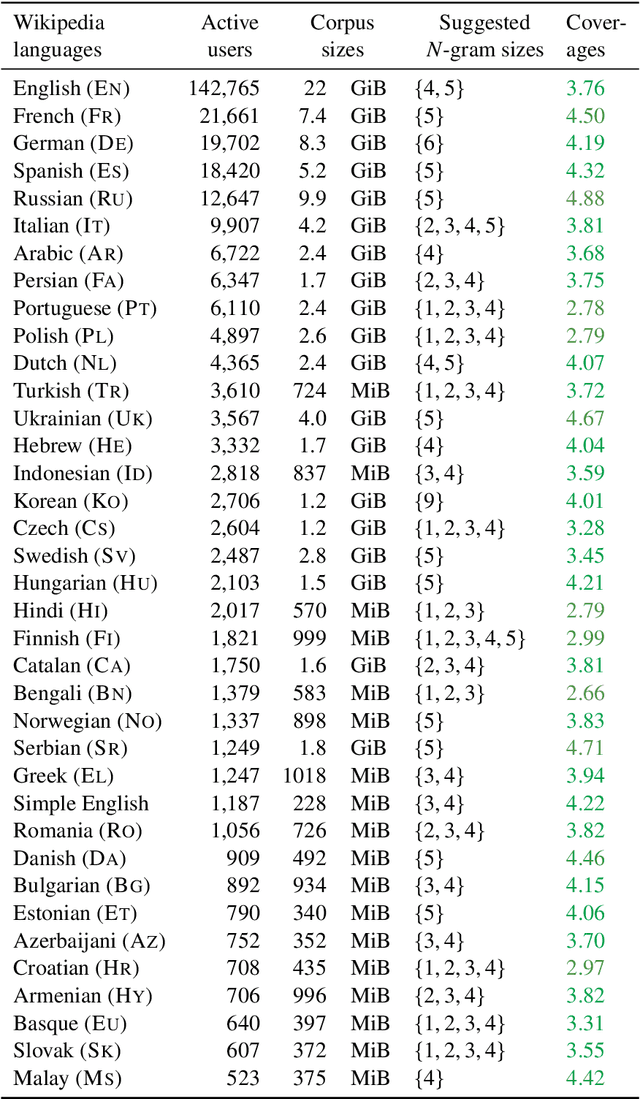
Unsupervised word representation learning from large corpora is badly needed for downstream tasks such as text classification, information retrieval, and machine translation. The representation precision of the fastText language models is mostly due to their use of subword information. In previous work, the optimization of fastText subword sizes has been largely neglected, and non-English fastText language models were trained using subword sizes optimized for English and German. In our work, we train English, German, Czech, and Italian fastText language models on Wikipedia, and we optimize the subword sizes on the English, German, Czech, and Italian word analogy tasks. We show that the optimization of subword sizes results in a 5% improvement on the Czech word analogy task. We also show that computationally expensive hyperparameter optimization can be replaced with cheap $n$-gram frequency analysis: subword sizes that are the closest to covering 3.76% of all unique subwords in a language are shown to be the optimal fastText hyperparameters on the English, German, Czech, and Italian word analogy tasks.