 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Can We Synthesize High-Quality Pretraining Data? A Systematic Study of Prompt Design, Generator Model, and Source Data
Apr 15, 2026Synthetic data is a standard component in training large language models, yet systematic comparisons across design dimensions, including rephrasing strategy, generator model, and source data, remain absent. We conduct extensive controlled experiments, generating over one trillion tokens, to identify critical factors in rephrasing web text into synthetic pretraining data. Our results reveal that structured output formats, such as tables, math problems, FAQs, and tutorials, consistently outperform both curated web baselines and prior synthetic methods. Notably, increasing the size of the generator model beyond 1B parameters provides no additional benefit. Our analysis also demonstrates that the selection of the original data used for mixing substantially influences performance. By applying our findings, we develop \textbf{\textsc{FinePhrase}}, a 486-billion-token open dataset of rephrased web text. We show that \textsc{FinePhrase} outperforms all existing synthetic data baselines while reducing generation costs by up to 30 times. We provide the dataset, all prompts, and the generation framework to the research community.
Unravelling the Mechanisms of Manipulating Numbers in Language Models
Oct 30, 2025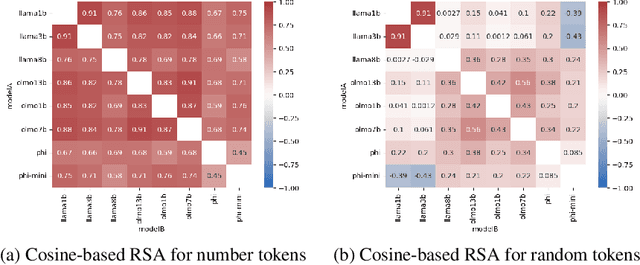

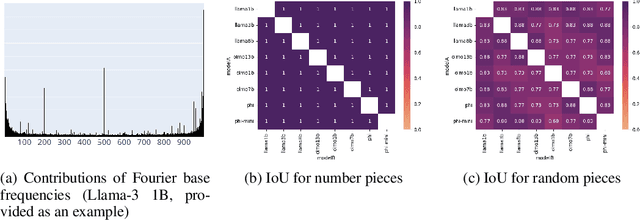
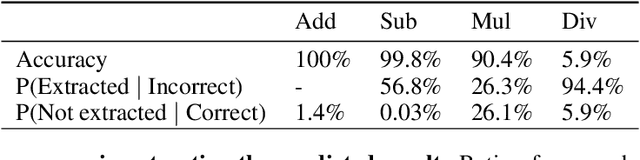
Recent work has shown that different large language models (LLMs) converge to similar and accurate input embedding representations for numbers. These findings conflict with the documented propensity of LLMs to produce erroneous outputs when dealing with numeric information. In this work, we aim to explain this conflict by exploring how language models manipulate numbers and quantify the lower bounds of accuracy of these mechanisms. We find that despite surfacing errors, different language models learn interchangeable representations of numbers that are systematic, highly accurate and universal across their hidden states and the types of input contexts. This allows us to create universal probes for each LLM and to trace information -- including the causes of output errors -- to specific layers. Our results lay a fundamental understanding of how pre-trained LLMs manipulate numbers and outline the potential of more accurate probing techniques in addressed refinements of LLMs' architectures.
Pre-trained Language Models Learn Remarkably Accurate Representations of Numbers
Jun 10, 2025



Pretrained language models (LMs) are prone to arithmetic errors. Existing work showed limited success in probing numeric values from models' representations, indicating that these errors can be attributed to the inherent unreliability of distributionally learned embeddings in representing exact quantities. However, we observe that previous probing methods are inadequate for the emergent structure of learned number embeddings with sinusoidal patterns. In response, we propose a novel probing technique that decodes numeric values from input embeddings with near-perfect accuracy across a range of open-source LMs. This proves that after the sole pre-training, LMs represent numbers with remarkable precision. Finally, we find that the embeddings' preciseness judged by our probe's accuracy explains a large portion of LM's errors in elementary arithmetic, and show that aligning the embeddings with the pattern discovered by our probe can mitigate these errors.
Negation: A Pink Elephant in the Large Language Models' Room?
Mar 28, 2025



Negations are key to determining sentence meaning, making them essential for logical reasoning. Despite their importance, negations pose a substantial challenge for large language models (LLMs) and remain underexplored. We construct two multilingual natural language inference (NLI) datasets with \textit{paired} examples differing in negation. We investigate how model size and language impact its ability to handle negation correctly by evaluating popular LLMs. Contrary to previous work, we show that increasing the model size consistently improves the models' ability to handle negations. Furthermore, we find that both the models' reasoning accuracy and robustness to negation are language-dependent and that the length and explicitness of the premise have a greater impact on robustness than language. Our datasets can facilitate further research and improvements of language model reasoning in multilingual settings.
Self-training Language Models for Arithmetic Reasoning
Jul 11, 2024Language models achieve impressive results in tasks involving complex multistep reasoning, but scaling these capabilities further traditionally requires expensive collection of more annotated data. In this work, we explore the potential of improving the capabilities of language models without new data, merely using automated feedback to the validity of their predictions in arithmetic reasoning (self-training). We find that models can substantially improve in both single-round (offline) and online self-training. In the offline setting, supervised methods are able to deliver gains comparable to preference optimization, but in online self-training, preference optimization shows to largely outperform supervised training thanks to superior stability and robustness on unseen types of problems.
Concept-aware Data Construction Improves In-context Learning of Language Models
Mar 08, 2024Many recent language models (LMs) are capable of in-context learning (ICL), manifested in the LMs' ability to perform a new task solely from natural-language instruction. Previous work curating in-context learners assumes that ICL emerges from a vast over-parametrization or the scale of multi-task training. However, recent theoretical work attributes the ICL ability to concept-dependent training data and creates functional in-context learners even in small-scale, synthetic settings. In this work, we practically explore this newly identified axis of ICL quality. We propose Concept-aware Training (CoAT), a framework for constructing training scenarios that make it beneficial for the LM to learn to utilize the analogical reasoning concepts from demonstrations. We find that by using CoAT, pre-trained transformers can learn to better utilise new latent concepts from demonstrations and that such ability makes ICL more robust to the functional deficiencies of the previous models. Finally, we show that concept-aware in-context learning is more effective for a majority of new tasks when compared to traditional instruction tuning, resulting in a performance comparable to the previous in-context learners using magnitudes of more training data.
People and Places of Historical Europe: Bootstrapping Annotation Pipeline and a New Corpus of Named Entities in Late Medieval Texts
Jun 06, 2023Although pre-trained named entity recognition (NER) models are highly accurate on modern corpora, they underperform on historical texts due to differences in language OCR errors. In this work, we develop a new NER corpus of 3.6M sentences from late medieval charters written mainly in Czech, Latin, and German. We show that we can start with a list of known historical figures and locations and an unannotated corpus of historical texts, and use information retrieval techniques to automatically bootstrap a NER-annotated corpus. Using our corpus, we train a NER model that achieves entity-level Precision of 72.81-93.98% with 58.14-81.77% Recall on a manually-annotated test dataset. Furthermore, we show that using a weighted loss function helps to combat class imbalance in token classification tasks. To make it easy for others to reproduce and build upon our work, we publicly release our corpus, models, and experimental code.
Calc-X: Enriching Arithmetical Chain-of-Thoughts Datasets by Interaction with Symbolic Systems
May 24, 2023



This report overviews our ongoing work in enriching chain-of-thoughts datasets requiring arithmetical reasoning with the integration of non-parametric components, such as a calculator. We conduct an analysis of prominent relevant datasets such as GSM8K, Ape210K, AQuA-RAT, and MathQA and propose a machine-processable HTML-like format specifically tailored for working with semi-structured chains. By converting the datasets into this unified format, we enable the effective integration of large language models and symbolic systems, empowering them to tackle arithmetical reasoning tasks more efficiently.
Concept-aware Training Improves In-context Learning Ability of Language Models
May 23, 2023

Many recent language models (LMs) of Transformers family exhibit so-called in-context learning (ICL) ability, manifested in the LMs' ability to modulate their function by a task described in a natural language input. Previous work curating these models assumes that ICL emerges from vast over-parametrization or the scale of multi-task training. However, a complementary branch of recent theoretical work attributes ICL emergence to specific properties of training data and creates functional in-context learners in small-scale, synthetic settings. Inspired by recent findings on data properties driving the emergence of ICL, we propose a method to create LMs able to better utilize the in-context information, by constructing training scenarios where it is beneficial for the LM to capture the analogical reasoning concepts. We measure that data sampling of Concept-aware Training (CoAT) consistently improves models' reasoning ability. As a result, the in-context learners trained with CoAT on only two datasets of a single (QA) task perform comparably to larger models trained on 1600+ tasks.
Think Twice: Measuring the Efficiency of Eliminating Prediction Shortcuts of Question Answering Models
May 11, 2023While the Large Language Models (LLMs) dominate a majority of language understanding tasks, previous work shows that some of these results are supported by modelling spurious correlations of training datasets. Authors commonly assess model robustness by evaluating their models on out-of-distribution (OOD) datasets of the same task, but these datasets might share the bias of the training dataset. We propose a simple method for measuring a scale of models' reliance on any identified spurious feature and assess the robustness towards a large set of known and newly found prediction biases for various pre-trained models and debiasing methods in Question Answering (QA). We find that the reported OOD gains of debiasing methods can not be explained by mitigated reliance on biased features, suggesting that biases are shared among QA datasets. We further evidence this by measuring that performance of OOD models depends on bias features comparably to the ID model, motivating future work to refine the reports of LLMs' robustness to a level of known spurious features.