 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePeople and Places of Historical Europe: Bootstrapping Annotation Pipeline and a New Corpus of Named Entities in Late Medieval Texts
Jun 06, 2023Although pre-trained named entity recognition (NER) models are highly accurate on modern corpora, they underperform on historical texts due to differences in language OCR errors. In this work, we develop a new NER corpus of 3.6M sentences from late medieval charters written mainly in Czech, Latin, and German. We show that we can start with a list of known historical figures and locations and an unannotated corpus of historical texts, and use information retrieval techniques to automatically bootstrap a NER-annotated corpus. Using our corpus, we train a NER model that achieves entity-level Precision of 72.81-93.98% with 58.14-81.77% Recall on a manually-annotated test dataset. Furthermore, we show that using a weighted loss function helps to combat class imbalance in token classification tasks. To make it easy for others to reproduce and build upon our work, we publicly release our corpus, models, and experimental code.
Adapt$\mathcal{O}$r: Objective-Centric Adaptation Framework for Language Models
Mar 08, 2022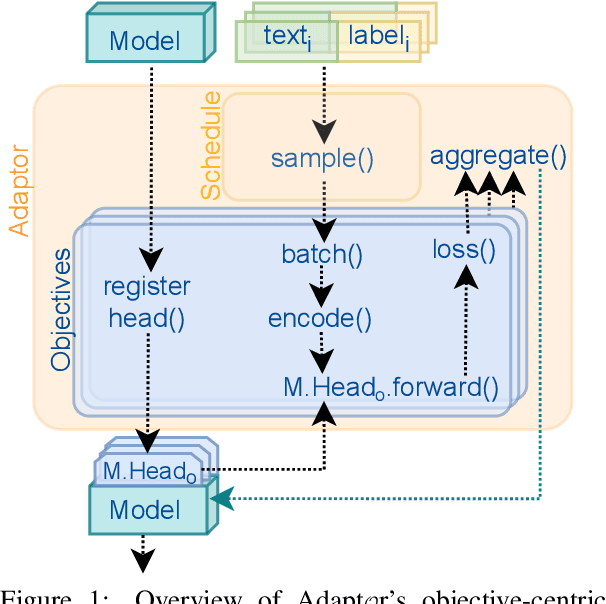


Progress in natural language processing research is catalyzed by the possibilities given by the widespread software frameworks. This paper introduces Adaptor library that transposes the traditional model-centric approach composed of pre-training + fine-tuning steps to objective-centric approach, composing the training process by applications of selected objectives. We survey research directions that can benefit from enhanced objective-centric experimentation in multitask training, custom objectives development, dynamic training curricula, or domain adaptation. Adaptor aims to ease reproducibility of these research directions in practice. Finally, we demonstrate the practical applicability of Adaptor in selected unsupervised domain adaptation scenarios.
Regressive Ensemble for Machine Translation Quality Evaluation
Sep 15, 2021

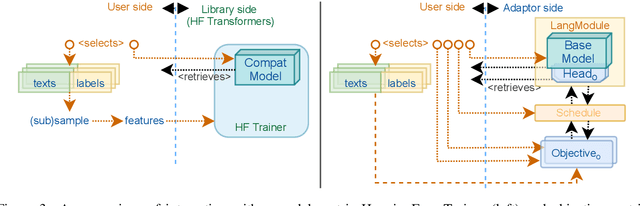
This work introduces a simple regressive ensemble for evaluating machine translation quality based on a set of novel and established metrics. We evaluate the ensemble using a correlation to expert-based MQM scores of the WMT 2021 Metrics workshop. In both monolingual and zero-shot cross-lingual settings, we show a significant performance improvement over single metrics. In the cross-lingual settings, we also demonstrate that an ensemble approach is well-applicable to unseen languages. Furthermore, we identify a strong reference-free baseline that consistently outperforms the commonly-used BLEU and METEOR measures and significantly improves our ensemble's performance.
WebMIaS on Docker: Deploying Math-Aware Search in a Single Line of Code
Jun 01, 2021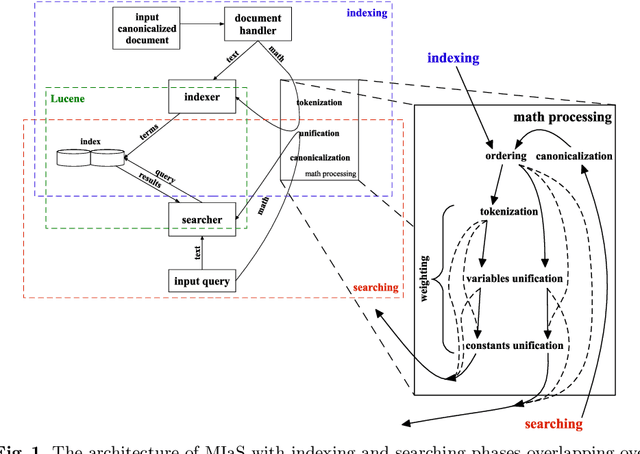
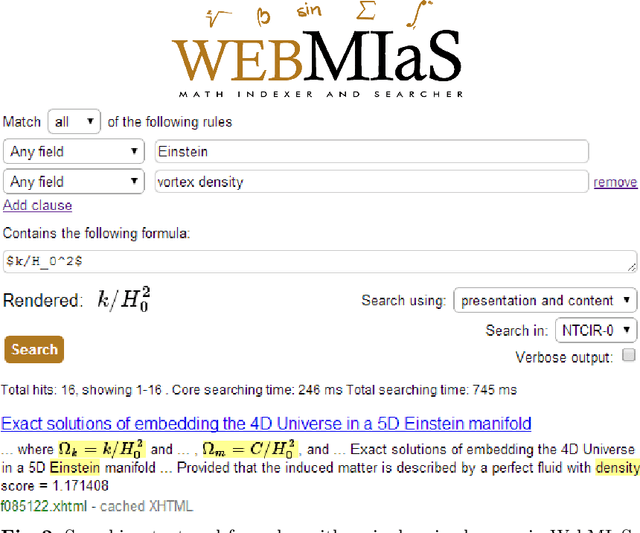


Math informational retrieval (MIR) search engines are absent in the wide-spread production use, even though documents in the STEM fields contain many mathematical formulae, which are sometimes more important than text for understanding. We have developed and open-sourced the WebMIaS MIR search engine that has been successfully deployed in the European Digital Mathematics Library (EuDML). However, its deployment is difficult to automate due to the complexity of this task. Moreover, the solutions developed so far to tackle this challenge are imperfect in terms of speed, maintenance, and robustness. In this paper, we will describe the virtualization of WebMIaS using Docker that solves all three problems and allows anyone to deploy containerized WebMIaS in a single line of code. The publicly available Docker image will also help the community push the development of math-aware search engines in the ARQMath workshop series.
When FastText Pays Attention: Efficient Estimation of Word Representations using Constrained Positional Weighting
Apr 21, 2021
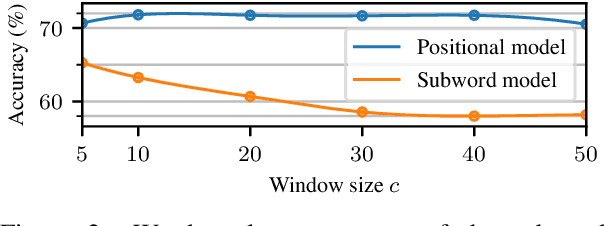
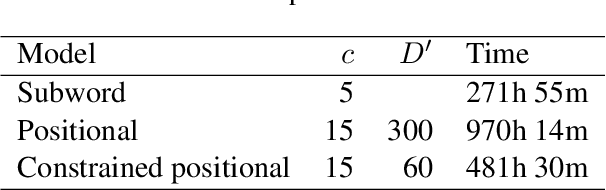
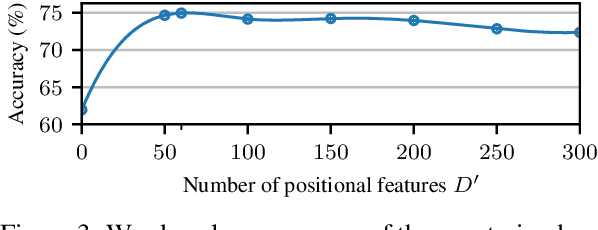
Since the seminal work of Mikolov et al. (2013a) and Bojanowski et al. (2017), word representations of shallow log-bilinear language models have found their way into many NLP applications. Mikolov et al. (2018) introduced a positional log-bilinear language model, which has characteristics of an attention-based language model and which has reached state-of-the-art performance on the intrinsic word analogy task. However, the positional model has never been evaluated on qualitative criteria or extrinsic tasks and its speed is impractical. We outline the similarities between the attention mechanism and the positional model, and we propose a constrained positional model, which adapts the sparse attention mechanism of Dai et al. (2018). We evaluate the positional and constrained positional models on three novel qualitative criteria and on the extrinsic language modeling task of Botha and Blunsom (2014). We show that the positional and constrained positional models contain interpretable information about word order and outperform the subword model of Bojanowski et al. (2017) on language modeling. We also show that the constrained positional model outperforms the positional model on language modeling and is twice as fast.
EDS-MEMBED: Multi-sense embeddings based on enhanced distributional semantic structures via a graph walk over word senses
Feb 27, 2021


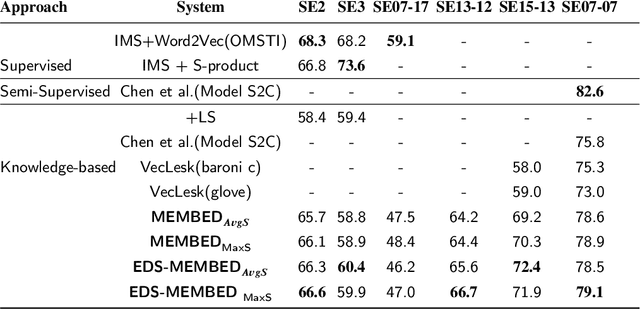
Several language applications often require word semantics as a core part of their processing pipeline, either as precise meaning inference or semantic similarity. Multi-sense embeddings (M-SE) can be exploited for this important requirement. M-SE seeks to represent each word by their distinct senses in order to resolve the conflation of meanings of words as used in different contexts. Previous works usually approach this task by training a model on a large corpus and often ignore the effect and usefulness of the semantic relations offered by lexical resources. However, even with large training data, coverage of all possible word senses is still an issue. In addition, a considerable percentage of contextual semantic knowledge are never learned because a huge amount of possible distributional semantic structures are never explored. In this paper, we leverage the rich semantic structures in WordNet using a graph-theoretic walk technique over word senses to enhance the quality of multi-sense embeddings. This algorithm composes enriched texts from the original texts. Furthermore, we derive new distributional semantic similarity measures for M-SE from prior ones. We adapt these measures to word sense disambiguation (WSD) aspect of our experiment. We report evaluation results on 11 benchmark datasets involving WSD and Word Similarity tasks and show that our method for enhancing distributional semantic structures improves embeddings quality on the baselines. Despite the small training data, it achieves state-of-the-art performance on some of the datasets.
One Size Does Not Fit All: Finding the Optimal N-gram Sizes for FastText Models across Languages
Feb 04, 2021

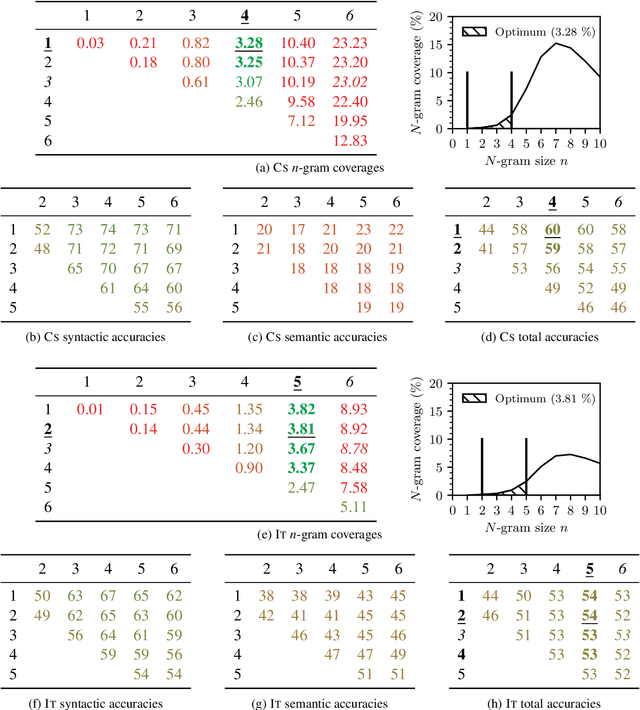
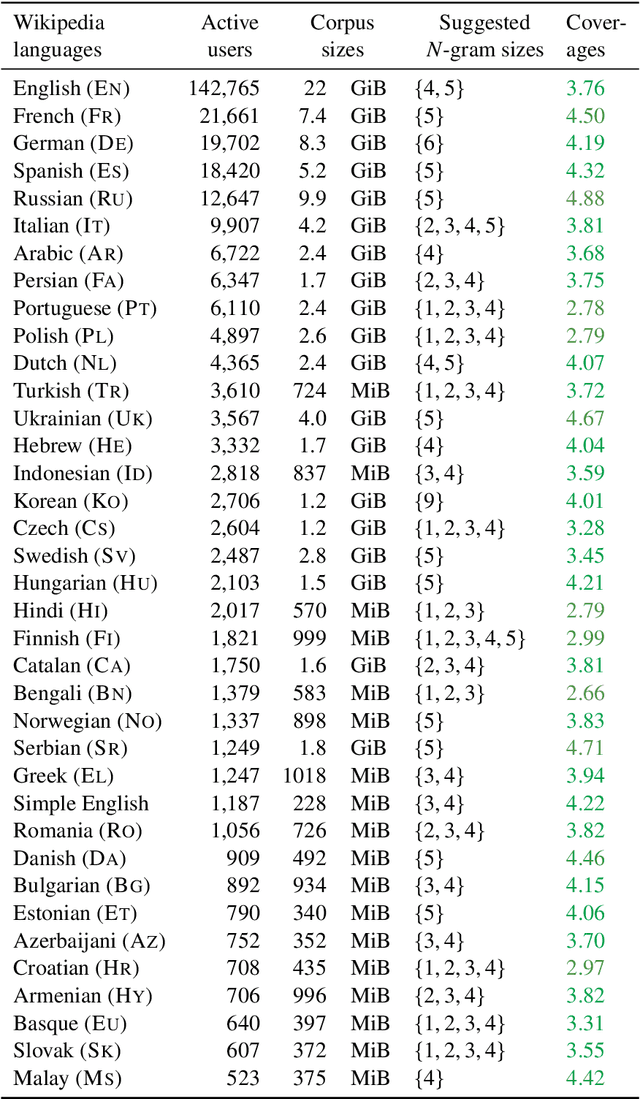
Unsupervised word representation learning from large corpora is badly needed for downstream tasks such as text classification, information retrieval, and machine translation. The representation precision of the fastText language models is mostly due to their use of subword information. In previous work, the optimization of fastText subword sizes has been largely neglected, and non-English fastText language models were trained using subword sizes optimized for English and German. In our work, we train English, German, Czech, and Italian fastText language models on Wikipedia, and we optimize the subword sizes on the English, German, Czech, and Italian word analogy tasks. We show that the optimization of subword sizes results in a 5% improvement on the Czech word analogy task. We also show that computationally expensive hyperparameter optimization can be replaced with cheap $n$-gram frequency analysis: subword sizes that are the closest to covering 3.76% of all unique subwords in a language are shown to be the optimal fastText hyperparameters on the English, German, Czech, and Italian word analogy tasks.
Text classification with word embedding regularization and soft similarity measure
Mar 10, 2020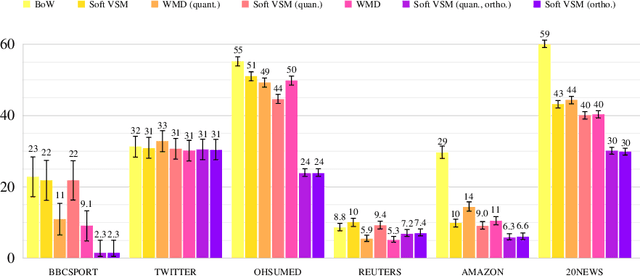
Since the seminal work of Mikolov et al., word embeddings have become the preferred word representations for many natural language processing tasks. Document similarity measures extracted from word embeddings, such as the soft cosine measure (SCM) and the Word Mover's Distance (WMD), were reported to achieve state-of-the-art performance on semantic text similarity and text classification. Despite the strong performance of the WMD on text classification and semantic text similarity, its super-cubic average time complexity is impractical. The SCM has quadratic worst-case time complexity, but its performance on text classification has never been compared with the WMD. Recently, two word embedding regularization techniques were shown to reduce storage and memory costs, and to improve training speed, document processing speed, and task performance on word analogy, word similarity, and semantic text similarity. However, the effect of these techniques on text classification has not yet been studied. In our work, we investigate the individual and joint effect of the two word embedding regularization techniques on the document processing speed and the task performance of the SCM and the WMD on text classification. For evaluation, we use the $k$NN classifier and six standard datasets: BBCSPORT, TWITTER, OHSUMED, REUTERS-21578, AMAZON, and 20NEWS. We show 39% average $k$NN test error reduction with regularized word embeddings compared to non-regularized word embeddings. We describe a practical procedure for deriving such regularized embeddings through Cholesky factorization. We also show that the SCM with regularized word embeddings significantly outperforms the WMD on text classification and is over 10,000 times faster.