 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePeople and Places of Historical Europe: Bootstrapping Annotation Pipeline and a New Corpus of Named Entities in Late Medieval Texts
Jun 06, 2023Although pre-trained named entity recognition (NER) models are highly accurate on modern corpora, they underperform on historical texts due to differences in language OCR errors. In this work, we develop a new NER corpus of 3.6M sentences from late medieval charters written mainly in Czech, Latin, and German. We show that we can start with a list of known historical figures and locations and an unannotated corpus of historical texts, and use information retrieval techniques to automatically bootstrap a NER-annotated corpus. Using our corpus, we train a NER model that achieves entity-level Precision of 72.81-93.98% with 58.14-81.77% Recall on a manually-annotated test dataset. Furthermore, we show that using a weighted loss function helps to combat class imbalance in token classification tasks. To make it easy for others to reproduce and build upon our work, we publicly release our corpus, models, and experimental code.
Evaluation of Automatically Constructed Word Meaning Explanations
Feb 27, 2023



Preparing exact and comprehensive word meaning explanations is one of the key steps in the process of monolingual dictionary writing. In standard methodology, the explanations need an expert lexicographer who spends a substantial amount of time checking the consistency between the descriptive text and corpus evidence. In the following text, we present a new tool that derives explanations automatically based on collective information from very large corpora, particularly on word sketches. We also propose a quantitative evaluation of the constructed explanations, concentrating on explanations of nouns. The methodology is to a certain extent language independent; however, the presented verification is limited to Czech and English. We show that the presented approach allows to create explanations that contain data useful for understanding the word meaning in approximately 90% of cases. However, in many cases, the result requires post-editing to remove redundant information.
* preprint of a chapter published by College Publications at https://www.collegepublications.co.uk/tributes/?00049
Information Extraction from Scanned Invoice Images using Text Analysis and Layout Features
Aug 08, 2022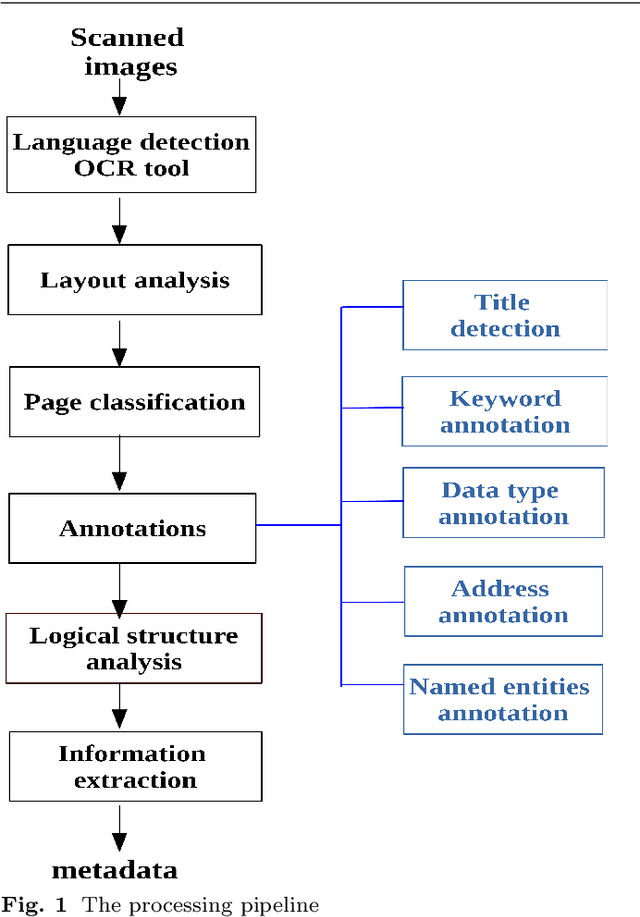
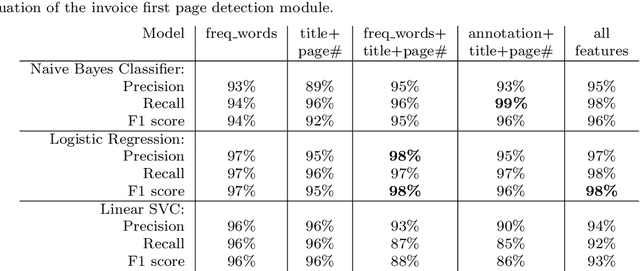
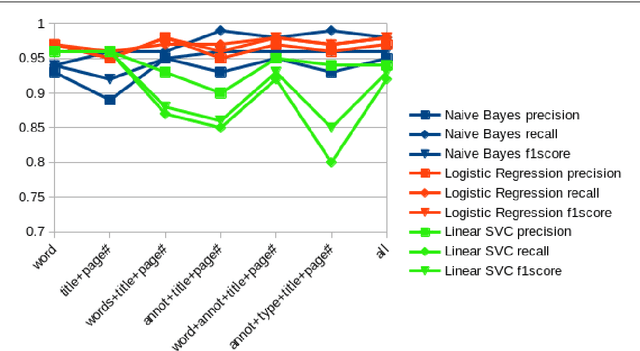
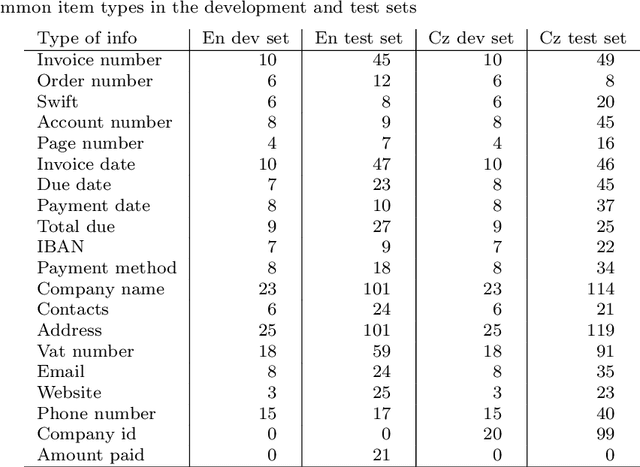
While storing invoice content as metadata to avoid paper document processing may be the future trend, almost all of daily issued invoices are still printed on paper or generated in digital formats such as PDFs. In this paper, we introduce the OCRMiner system for information extraction from scanned document images which is based on text analysis techniques in combination with layout features to extract indexing metadata of (semi-)structured documents. The system is designed to process the document in a similar way a human reader uses, i.e. to employ different layout and text attributes in a coordinated decision. The system consists of a set of interconnected modules that start with (possibly erroneous) character-based output from a standard OCR system and allow to apply different techniques and to expand the extracted knowledge at each step. Using an open source OCR, the system is able to recover the invoice data in 90% for English and in 88% for the Czech set.
* This is an author preprint of the article published by Elsevier in Signal Processing: Image Communication at https://doi.org/10.1016/j.image.2021.116601
Technological Approaches to Detecting Online Disinformation and Manipulation
Aug 26, 2021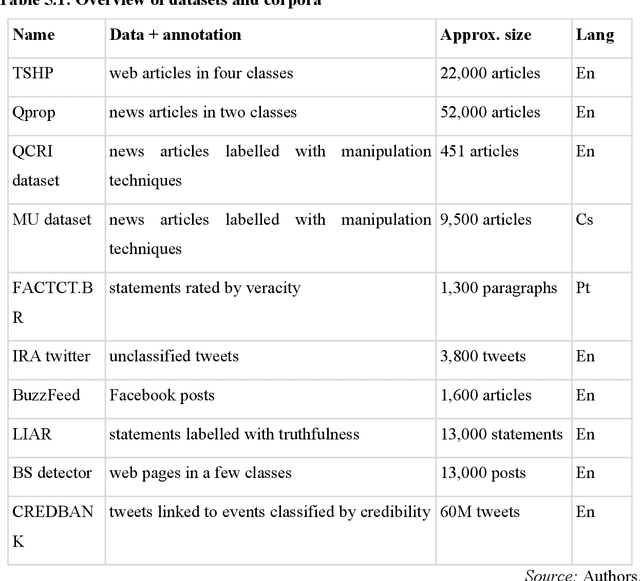
The move of propaganda and disinformation to the online environment is possible thanks to the fact that within the last decade, digital information channels radically increased in popularity as a news source. The main advantage of such media lies in the speed of information creation and dissemination. This, on the other hand, inevitably adds pressure, accelerating editorial work, fact-checking, and the scrutiny of source credibility. In this chapter, an overview of computer-supported approaches to detecting disinformation and manipulative techniques based on several criteria is presented. We concentrate on the technical aspects of automatic methods which support fact-checking, topic identification, text style analysis, or message filtering on social media channels. Most of the techniques employ artificial intelligence and machine learning with feature extraction combining available information resources. The following text firstly specifies the tasks related to computer detection of manipulation and disinformation spreading. The second section presents concrete methods of solving the tasks of the analysis, and the third sections enlists current verification and benchmarking datasets published and used in this area for evaluation and comparison.
Hyperintensional Reasoning based on Natural Language Knowledge Base
Jun 18, 2019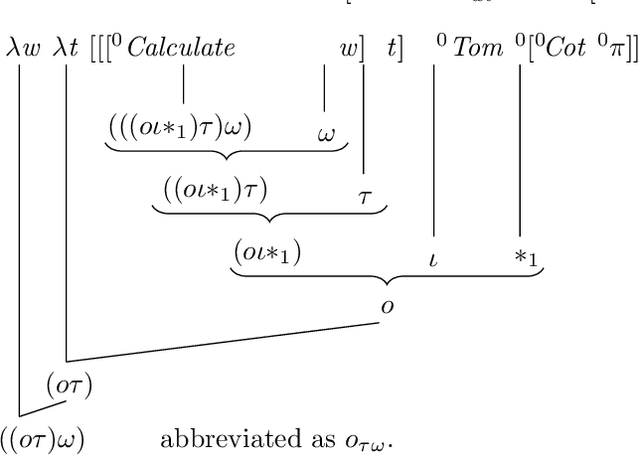
The success of automated reasoning techniques over large natural-language texts heavily relies on a fine-grained analysis of natural language assumptions. While there is a common agreement that the analysis should be hyperintensional, most of the automatic reasoning systems are still based on an intensional logic, at the best. In this paper, we introduce the system of reasoning based on a fine-grained, hyperintensional analysis. To this end we apply Tichy's Transparent Intensional Logic (TIL) with its procedural semantics. TIL is a higher-order, hyperintensional logic of partial functions, in particular apt for a fine-grained natural-language analysis. Within TIL we recognise three kinds of context, namely extensional, intensional and hyperintensional, in which a particular natural-language term, or rather its meaning, can occur. Having defined the three kinds of context and implemented an algorithm of context recognition, we are in a position to develop and implement an extensional logic of hyperintensions with the inference machine that should neither over-infer nor under-infer.