 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOne Size Does Not Fit All: Finding the Optimal N-gram Sizes for FastText Models across Languages
Paper and Code


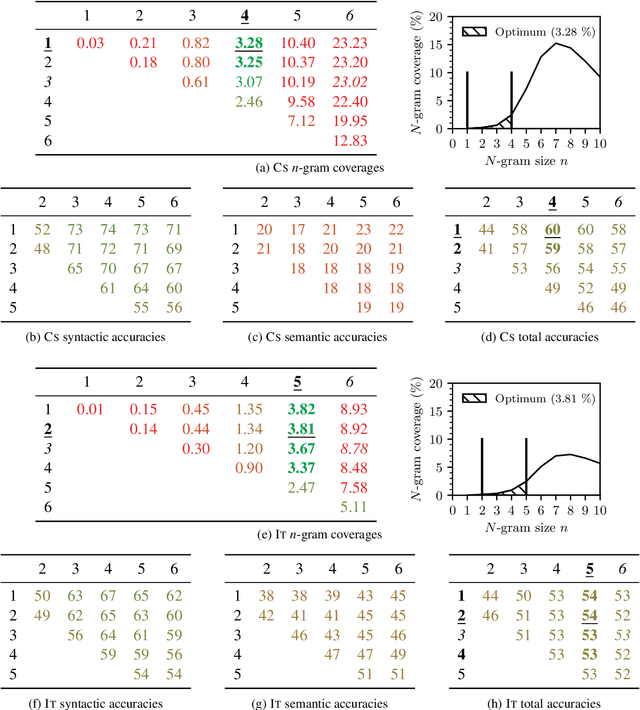
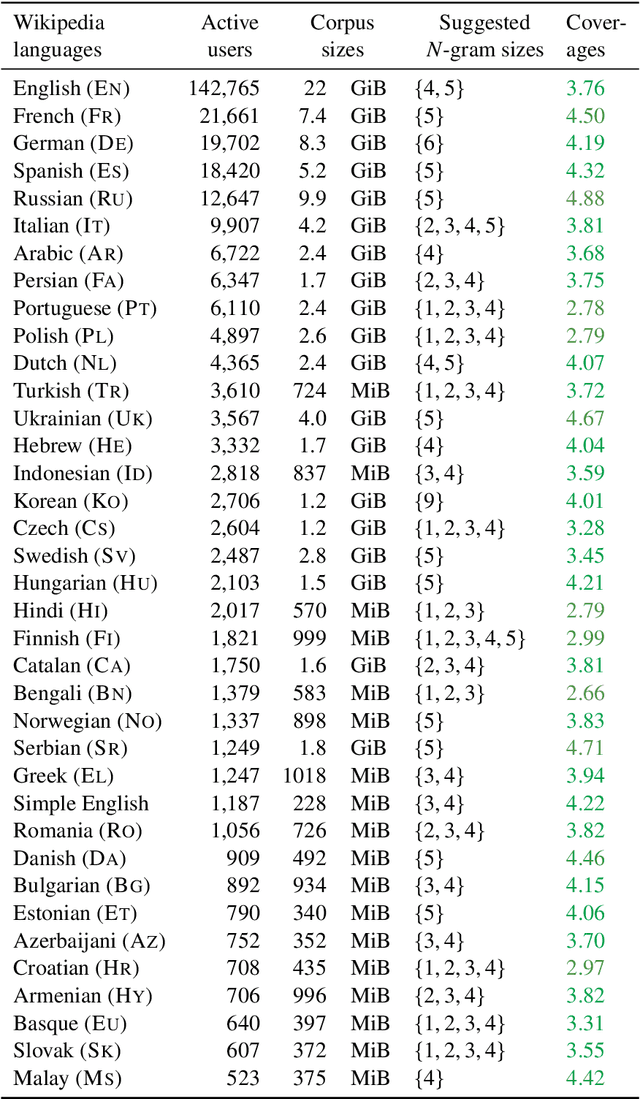
Unsupervised word representation learning from large corpora is badly needed for downstream tasks such as text classification, information retrieval, and machine translation. The representation precision of the fastText language models is mostly due to their use of subword information. In previous work, the optimization of fastText subword sizes has been largely neglected, and non-English fastText language models were trained using subword sizes optimized for English and German. In our work, we train English, German, Czech, and Italian fastText language models on Wikipedia, and we optimize the subword sizes on the English, German, Czech, and Italian word analogy tasks. We show that the optimization of subword sizes results in a 5% improvement on the Czech word analogy task. We also show that computationally expensive hyperparameter optimization can be replaced with cheap $n$-gram frequency analysis: subword sizes that are the closest to covering 3.76% of all unique subwords in a language are shown to be the optimal fastText hyperparameters on the English, German, Czech, and Italian word analogy tasks.