 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnravelling the Mechanisms of Manipulating Numbers in Language Models
Oct 30, 2025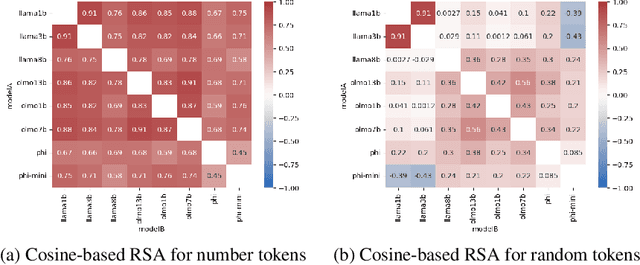

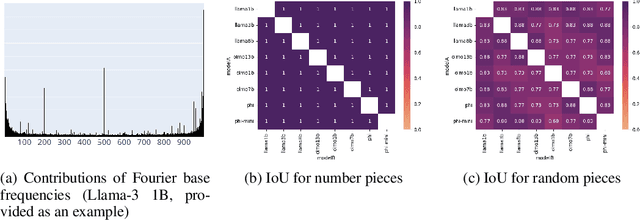
Recent work has shown that different large language models (LLMs) converge to similar and accurate input embedding representations for numbers. These findings conflict with the documented propensity of LLMs to produce erroneous outputs when dealing with numeric information. In this work, we aim to explain this conflict by exploring how language models manipulate numbers and quantify the lower bounds of accuracy of these mechanisms. We find that despite surfacing errors, different language models learn interchangeable representations of numbers that are systematic, highly accurate and universal across their hidden states and the types of input contexts. This allows us to create universal probes for each LLM and to trace information -- including the causes of output errors -- to specific layers. Our results lay a fundamental understanding of how pre-trained LLMs manipulate numbers and outline the potential of more accurate probing techniques in addressed refinements of LLMs' architectures.
Pre-trained Language Models Learn Remarkably Accurate Representations of Numbers
Jun 10, 2025



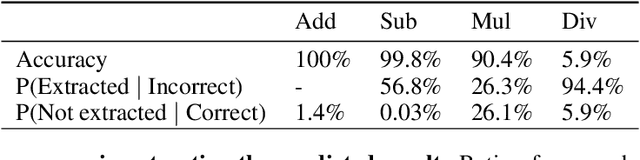
Pretrained language models (LMs) are prone to arithmetic errors. Existing work showed limited success in probing numeric values from models' representations, indicating that these errors can be attributed to the inherent unreliability of distributionally learned embeddings in representing exact quantities. However, we observe that previous probing methods are inadequate for the emergent structure of learned number embeddings with sinusoidal patterns. In response, we propose a novel probing technique that decodes numeric values from input embeddings with near-perfect accuracy across a range of open-source LMs. This proves that after the sole pre-training, LMs represent numbers with remarkable precision. Finally, we find that the embeddings' preciseness judged by our probe's accuracy explains a large portion of LM's errors in elementary arithmetic, and show that aligning the embeddings with the pattern discovered by our probe can mitigate these errors.
Negation: A Pink Elephant in the Large Language Models' Room?
Mar 28, 2025



Negations are key to determining sentence meaning, making them essential for logical reasoning. Despite their importance, negations pose a substantial challenge for large language models (LLMs) and remain underexplored. We construct two multilingual natural language inference (NLI) datasets with \textit{paired} examples differing in negation. We investigate how model size and language impact its ability to handle negation correctly by evaluating popular LLMs. Contrary to previous work, we show that increasing the model size consistently improves the models' ability to handle negations. Furthermore, we find that both the models' reasoning accuracy and robustness to negation are language-dependent and that the length and explicitness of the premise have a greater impact on robustness than language. Our datasets can facilitate further research and improvements of language model reasoning in multilingual settings.
Self-training Language Models for Arithmetic Reasoning
Jul 11, 2024Language models achieve impressive results in tasks involving complex multistep reasoning, but scaling these capabilities further traditionally requires expensive collection of more annotated data. In this work, we explore the potential of improving the capabilities of language models without new data, merely using automated feedback to the validity of their predictions in arithmetic reasoning (self-training). We find that models can substantially improve in both single-round (offline) and online self-training. In the offline setting, supervised methods are able to deliver gains comparable to preference optimization, but in online self-training, preference optimization shows to largely outperform supervised training thanks to superior stability and robustness on unseen types of problems.
Concept-aware Data Construction Improves In-context Learning of Language Models
Mar 08, 2024Many recent language models (LMs) are capable of in-context learning (ICL), manifested in the LMs' ability to perform a new task solely from natural-language instruction. Previous work curating in-context learners assumes that ICL emerges from a vast over-parametrization or the scale of multi-task training. However, recent theoretical work attributes the ICL ability to concept-dependent training data and creates functional in-context learners even in small-scale, synthetic settings. In this work, we practically explore this newly identified axis of ICL quality. We propose Concept-aware Training (CoAT), a framework for constructing training scenarios that make it beneficial for the LM to learn to utilize the analogical reasoning concepts from demonstrations. We find that by using CoAT, pre-trained transformers can learn to better utilise new latent concepts from demonstrations and that such ability makes ICL more robust to the functional deficiencies of the previous models. Finally, we show that concept-aware in-context learning is more effective for a majority of new tasks when compared to traditional instruction tuning, resulting in a performance comparable to the previous in-context learners using magnitudes of more training data.
Calc-X: Enriching Arithmetical Chain-of-Thoughts Datasets by Interaction with Symbolic Systems
May 24, 2023



This report overviews our ongoing work in enriching chain-of-thoughts datasets requiring arithmetical reasoning with the integration of non-parametric components, such as a calculator. We conduct an analysis of prominent relevant datasets such as GSM8K, Ape210K, AQuA-RAT, and MathQA and propose a machine-processable HTML-like format specifically tailored for working with semi-structured chains. By converting the datasets into this unified format, we enable the effective integration of large language models and symbolic systems, empowering them to tackle arithmetical reasoning tasks more efficiently.
Concept-aware Training Improves In-context Learning Ability of Language Models
May 23, 2023

Many recent language models (LMs) of Transformers family exhibit so-called in-context learning (ICL) ability, manifested in the LMs' ability to modulate their function by a task described in a natural language input. Previous work curating these models assumes that ICL emerges from vast over-parametrization or the scale of multi-task training. However, a complementary branch of recent theoretical work attributes ICL emergence to specific properties of training data and creates functional in-context learners in small-scale, synthetic settings. Inspired by recent findings on data properties driving the emergence of ICL, we propose a method to create LMs able to better utilize the in-context information, by constructing training scenarios where it is beneficial for the LM to capture the analogical reasoning concepts. We measure that data sampling of Concept-aware Training (CoAT) consistently improves models' reasoning ability. As a result, the in-context learners trained with CoAT on only two datasets of a single (QA) task perform comparably to larger models trained on 1600+ tasks.
A Whisper transformer for audio captioning trained with synthetic captions and transfer learning
May 15, 2023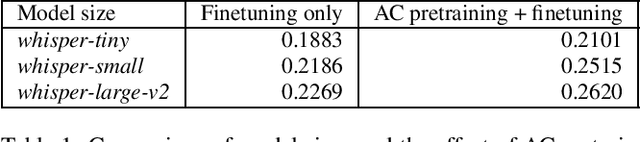

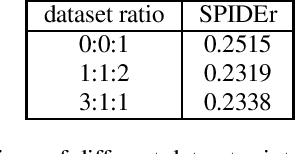
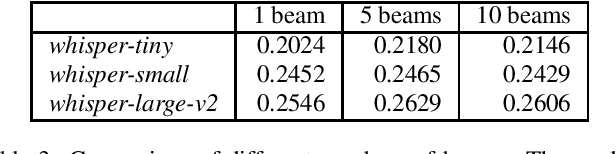
The field of audio captioning has seen significant advancements in recent years, driven by the availability of large-scale audio datasets and advancements in deep learning techniques. In this technical report, we present our approach to audio captioning, focusing on the use of a pretrained speech-to-text Whisper model and pretraining on synthetic captions. We discuss our training procedures and present our experiments' results, which include model size variations, dataset mixtures, and other hyperparameters. Our findings demonstrate the impact of different training strategies on the performance of the audio captioning model. Our code and trained models are publicly available on GitHub and Hugging Face Hub.
Resources and Few-shot Learners for In-context Learning in Slavic Languages
Apr 04, 2023Despite the rapid recent progress in creating accurate and compact in-context learners, most recent work focuses on in-context learning (ICL) for tasks in English. However, the ability to interact with users of languages outside English presents a great potential for broadening the applicability of language technologies to non-English speakers. In this work, we collect the infrastructure necessary for training and evaluation of ICL in a selection of Slavic languages: Czech, Polish, and Russian. We link a diverse set of datasets and cast these into a unified instructional format through a set of transformations and newly-crafted templates written purely in target languages. Using the newly-curated dataset, we evaluate a set of the most recent in-context learners and compare their results to the supervised baselines. Finally, we train, evaluate and publish a set of in-context learning models that we train on the collected resources and compare their performance to previous work. We find that ICL models tuned in English are also able to learn some tasks from non-English contexts, but multilingual instruction fine-tuning consistently improves the ICL ability. We also find that the massive multitask training can be outperformed by single-task training in the target language, uncovering the potential for specializing in-context learners to the language(s) of their application.
What is Not in the Context? Evaluation of Few-shot Learners with Informative Demonstrations
Dec 03, 2022Large language models demonstrate an emergent ability to learn a new task from a small number of input-output demonstrations, referred to as in-context few-shot learning. However, recent work shows that in such settings, models mainly learn to mimic the new task distribution, instead of the mechanics of the new task. We argue that the commonly-used evaluation settings of few-shot models utilizing a random selection of in-context demonstrations is not able to disentangle models' ability to learn new skills from demonstrations, as most of the such-selected demonstrations are not informative for prediction beyond exposing the new task's input and output distribution. Therefore, we introduce an evaluation technique that disentangles few-shot learners' gain from in-context learning by picking the demonstrations sharing a specific, informative concept with the predicted sample, in addition to the performance reached by mainly non-informative samples. We find that regardless of the model size, existing few-shot learners are not able to benefit from observing such informative concepts in demonstrations. We also find that such ability may not be obtained trivially by exposing the informative demonstrations in the training process, leaving the challenge of training true in-context learners open.