 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpecTUS: Spectral Translator for Unknown Structures annotation from EI-MS spectra
Feb 07, 2025



Compound identification and structure annotation from mass spectra is a well-established task widely applied in drug detection, criminal forensics, small molecule biomarker discovery and chemical engineering. We propose SpecTUS: Spectral Translator for Unknown Structures, a deep neural model that addresses the task of structural annotation of small molecules from low-resolution gas chromatography electron ionization mass spectra (GC-EI-MS). Our model analyzes the spectra in \textit{de novo} manner -- a direct translation from the spectra into 2D-structural representation. Our approach is particularly useful for analyzing compounds unavailable in spectral libraries. In a rigorous evaluation of our model on the novel structure annotation task across different libraries, we outperformed standard database search techniques by a wide margin. On a held-out testing set, including \numprint{28267} spectra from the NIST database, we show that our model's single suggestion perfectly reconstructs 43\% of the subset's compounds. This single suggestion is strictly better than the candidate of the database hybrid search (common method among practitioners) in 76\% of cases. In a~still affordable scenario of~10 suggestions, perfect reconstruction is achieved in 65\%, and 84\% are better than the hybrid search.
A Whisper transformer for audio captioning trained with synthetic captions and transfer learning
May 15, 2023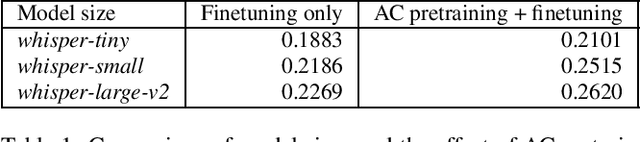

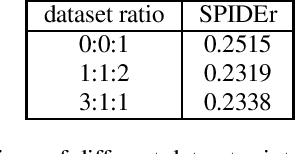
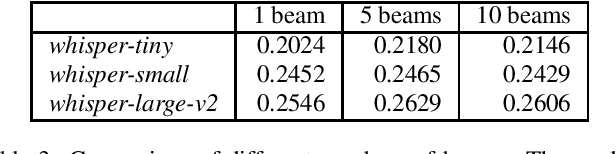
The field of audio captioning has seen significant advancements in recent years, driven by the availability of large-scale audio datasets and advancements in deep learning techniques. In this technical report, we present our approach to audio captioning, focusing on the use of a pretrained speech-to-text Whisper model and pretraining on synthetic captions. We discuss our training procedures and present our experiments' results, which include model size variations, dataset mixtures, and other hyperparameters. Our findings demonstrate the impact of different training strategies on the performance of the audio captioning model. Our code and trained models are publicly available on GitHub and Hugging Face Hub.
De-novo Identification of Small Molecules from Their GC-EI-MS Spectra
Apr 04, 2023



Identification of experimentally acquired mass spectra of unknown compounds presents a~particular challenge because reliable spectral databases do not cover the potential chemical space with sufficient density. Therefore machine learning based \emph{de-novo} methods, which derive molecular structure directly from its mass spectrum gained attention recently. We present a~novel method in this family, addressing a~specific usecase of GC-EI-MS spectra, which is particularly hard due to lack of additional information from the first stage of MS/MS experiments, on which the previously published methods rely. We analyze strengths and drawbacks or our approach and discuss future directions.