 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Math-Aware Automated Classification and Similarity Search of Scientific Publications: Methods of Mathematical Content Representations
Oct 08, 2021
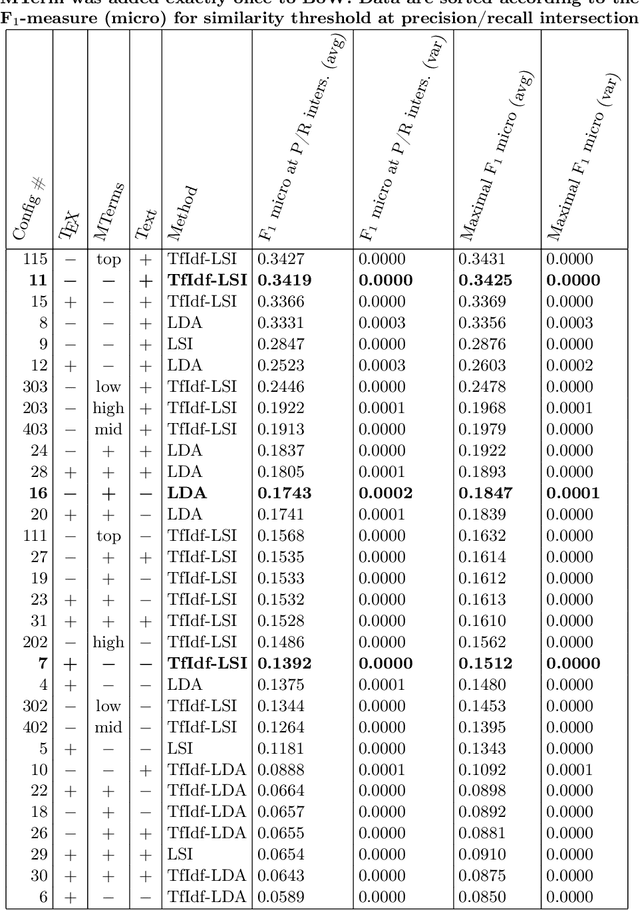
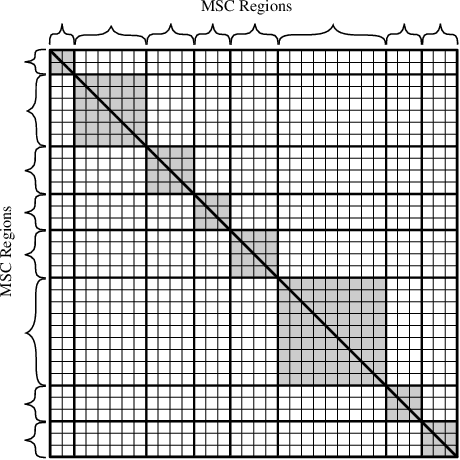

In this paper, we investigate mathematical content representations suitable for the automated classification of and the similarity search in STEM documents using standard machine learning algorithms: the Latent Dirichlet Allocation (LDA) and the Latent Semantic Indexing (LSI). The methods are evaluated on a subset of arXiv.org papers with the Mathematics Subject Classification (MSC) as a reference classification and using the standard precision/recall/F1-measure metrics. The results give insight into how different math representations may influence the performance of the classification and similarity search tasks in STEM repositories. Non-surprisingly, machine learning methods are able to grab distributional semantics from textual tokens. A proper selection of weighted tokens representing math may improve the quality of the results slightly. A structured math representation that imitates successful text-processing techniques with math is shown to yield better results than flat TeX tokens.