 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTHEval. Evaluation Framework for Talking Head Video Generation
Nov 06, 2025Video generation has achieved remarkable progress, with generated videos increasingly resembling real ones. However, the rapid advance in generation has outpaced the development of adequate evaluation metrics. Currently, the assessment of talking head generation primarily relies on limited metrics, evaluating general video quality, lip synchronization, and on conducting user studies. Motivated by this, we propose a new evaluation framework comprising 8 metrics related to three dimensions (i) quality, (ii) naturalness, and (iii) synchronization. In selecting the metrics, we place emphasis on efficiency, as well as alignment with human preferences. Based on this considerations, we streamline to analyze fine-grained dynamics of head, mouth, and eyebrows, as well as face quality. Our extensive experiments on 85,000 videos generated by 17 state-of-the-art models suggest that while many algorithms excel in lip synchronization, they face challenges with generating expressiveness and artifact-free details. These videos were generated based on a novel real dataset, that we have curated, in order to mitigate bias of training data. Our proposed benchmark framework is aimed at evaluating the improvement of generative methods. Original code, dataset and leaderboards will be publicly released and regularly updated with new methods, in order to reflect progress in the field.
Dimitra: Audio-driven Diffusion model for Expressive Talking Head Generation
Feb 24, 2025We propose Dimitra, a novel framework for audio-driven talking head generation, streamlined to learn lip motion, facial expression, as well as head pose motion. Specifically, we train a conditional Motion Diffusion Transformer (cMDT) by modeling facial motion sequences with 3D representation. We condition the cMDT with only two input signals, an audio-sequence, as well as a reference facial image. By extracting additional features directly from audio, Dimitra is able to increase quality and realism of generated videos. In particular, phoneme sequences contribute to the realism of lip motion, whereas text transcript to facial expression and head pose realism. Quantitative and qualitative experiments on two widely employed datasets, VoxCeleb2 and HDTF, showcase that Dimitra is able to outperform existing approaches for generating realistic talking heads imparting lip motion, facial expression, and head pose.
Bipartite Graph Diffusion Model for Human Interaction Generation
Jan 24, 2023


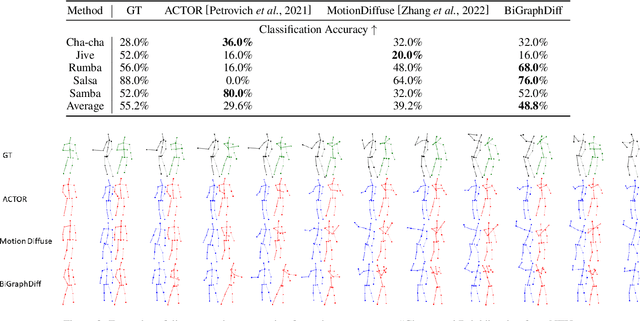
The generation of natural human motion interactions is a hot topic in computer vision and computer animation. It is a challenging task due to the diversity of possible human motion interactions. Diffusion models, which have already shown remarkable generative capabilities in other domains, are a good candidate for this task. In this paper, we introduce a novel bipartite graph diffusion method (BiGraphDiff) to generate human motion interactions between two persons. Specifically, bipartite node sets are constructed to model the inherent geometric constraints between skeleton nodes during interactions. The interaction graph diffusion model is transformer-based, combining some state-of-the-art motion methods. We show that the proposed achieves new state-of-the-art results on leading benchmarks for the human interaction generation task.
Interaction Transformer for Human Reaction Generation
Jul 04, 2022

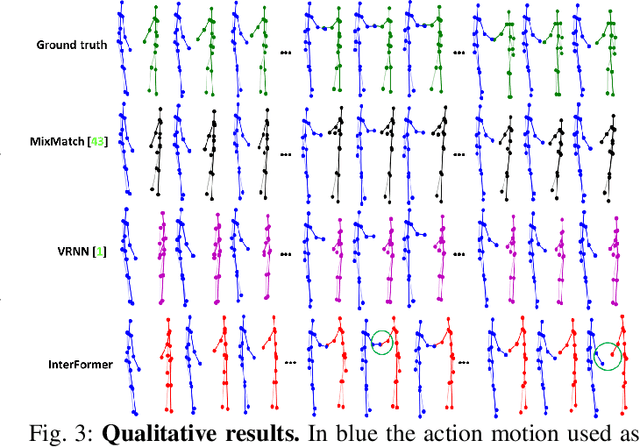

We address the challenging task of human reaction generation which aims to generate a corresponding reaction based on an input action. Most of the existing works do not focus on generating and predicting the reaction and cannot generate the motion when only the action is given as input. To address this limitation, we propose a novel interaction Transformer (InterFormer) consisting of a Transformer network with both temporal and spatial attentions. Specifically, the temporal attention captures the temporal dependencies of the motion of both characters and of their interaction, while the spatial attention learns the dependencies between the different body parts of each character and those which are part of the interaction. Moreover, we propose using graphs to increase the performance of the spatial attention via an interaction distance module that helps focus on nearby joints from both characters. Extensive experiments on the SBU interaction, K3HI, and DuetDance datasets demonstrate the effectiveness of InterFormer. Our method is general and can be used to generate more complex and long-term interactions.
3D Skeleton-based Human Motion Prediction with Manifold-Aware GAN
Mar 01, 2022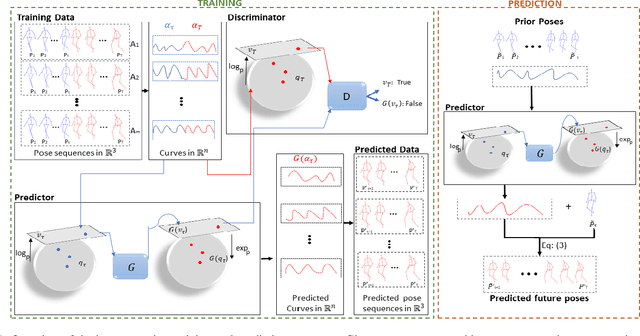


In this work we propose a novel solution for 3D skeleton-based human motion prediction. The objective of this task consists in forecasting future human poses based on a prior skeleton pose sequence. This involves solving two main challenges still present in recent literature; (1) discontinuity of the predicted motion which results in unrealistic motions and (2) performance deterioration in long-term horizons resulting from error accumulation across time. We tackle these issues by using a compact manifold-valued representation of 3D human skeleton motion. Specifically, we model the temporal evolution of the 3D poses as trajectory, what allows us to map human motions to single points on a sphere manifold. Using such a compact representation avoids error accumulation and provides robust representation for long-term prediction while ensuring the smoothness and the coherence of the whole motion. To learn these non-Euclidean representations, we build a manifold-aware Wasserstein generative adversarial model that captures the temporal and spatial dependencies of human motion through different losses. Experiments have been conducted on CMU MoCap and Human 3.6M datasets and demonstrate the superiority of our approach over the state-of-the-art both in short and long term horizons. The smoothness of the generated motion is highlighted in the qualitative results.
Human Motion Prediction Using Manifold-Aware Wasserstein GAN
May 18, 2021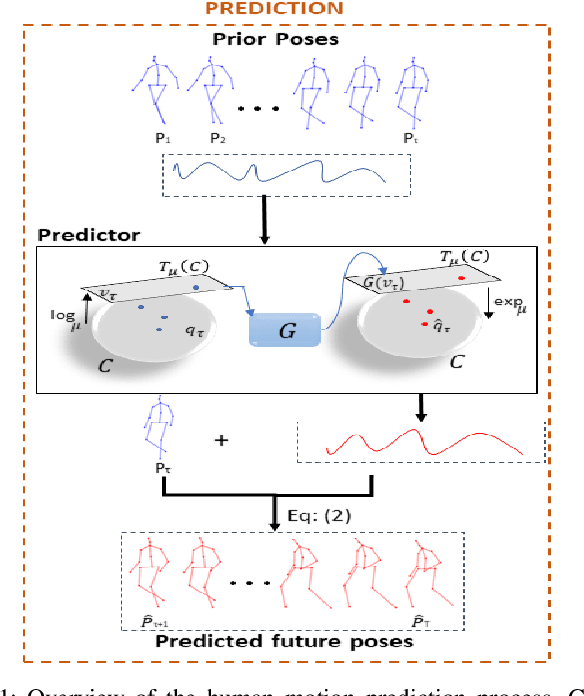
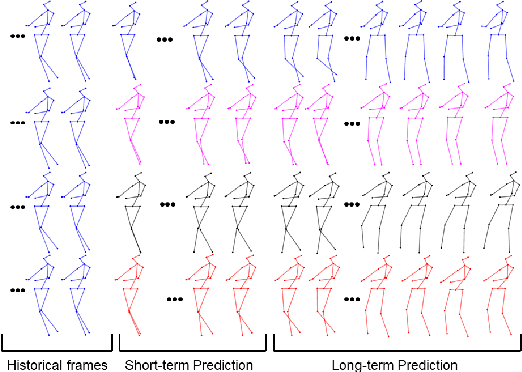
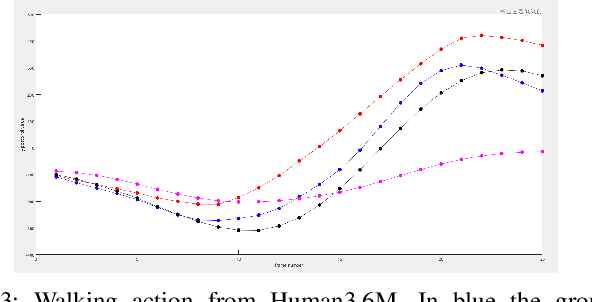
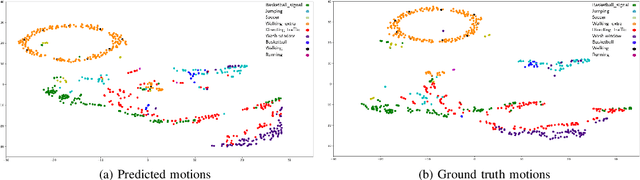
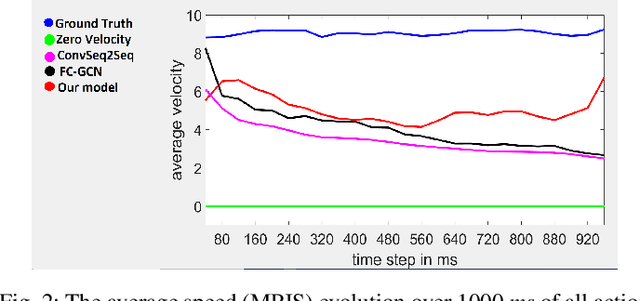
Human motion prediction aims to forecast future human poses given a prior pose sequence. The discontinuity of the predicted motion and the performance deterioration in long-term horizons are still the main challenges encountered in current literature. In this work, we tackle these issues by using a compact manifold-valued representation of human motion. Specifically, we model the temporal evolution of the 3D human poses as trajectory, what allows us to map human motions to single points on a sphere manifold. To learn these non-Euclidean representations, we build a manifold-aware Wasserstein generative adversarial model that captures the temporal and spatial dependencies of human motion through different losses. Extensive experiments show that our approach outperforms the state-of-the-art on CMU MoCap and Human 3.6M datasets. Our qualitative results show the smoothness of the predicted motions.