 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3D Skeleton-based Human Motion Prediction with Manifold-Aware GAN
Mar 01, 2022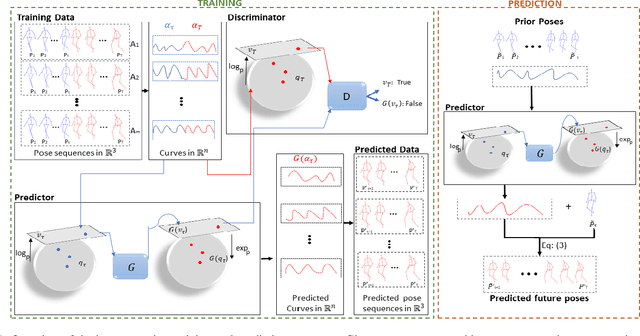


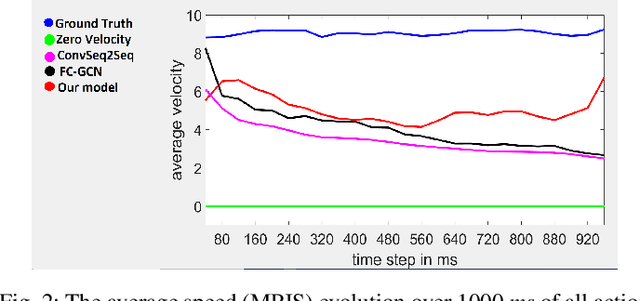
In this work we propose a novel solution for 3D skeleton-based human motion prediction. The objective of this task consists in forecasting future human poses based on a prior skeleton pose sequence. This involves solving two main challenges still present in recent literature; (1) discontinuity of the predicted motion which results in unrealistic motions and (2) performance deterioration in long-term horizons resulting from error accumulation across time. We tackle these issues by using a compact manifold-valued representation of 3D human skeleton motion. Specifically, we model the temporal evolution of the 3D poses as trajectory, what allows us to map human motions to single points on a sphere manifold. Using such a compact representation avoids error accumulation and provides robust representation for long-term prediction while ensuring the smoothness and the coherence of the whole motion. To learn these non-Euclidean representations, we build a manifold-aware Wasserstein generative adversarial model that captures the temporal and spatial dependencies of human motion through different losses. Experiments have been conducted on CMU MoCap and Human 3.6M datasets and demonstrate the superiority of our approach over the state-of-the-art both in short and long term horizons. The smoothness of the generated motion is highlighted in the qualitative results.
Human Motion Prediction Using Manifold-Aware Wasserstein GAN
May 18, 2021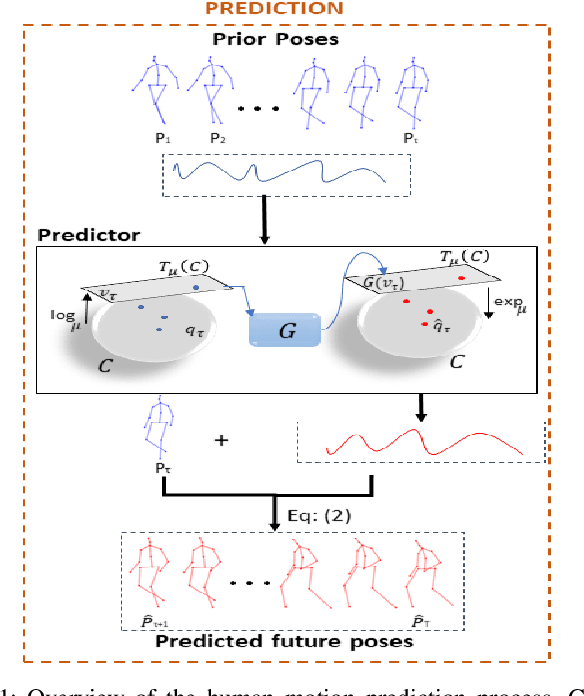
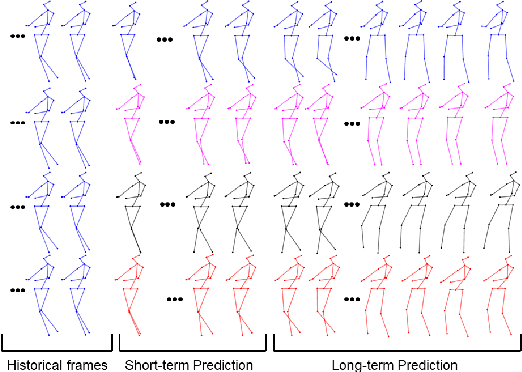
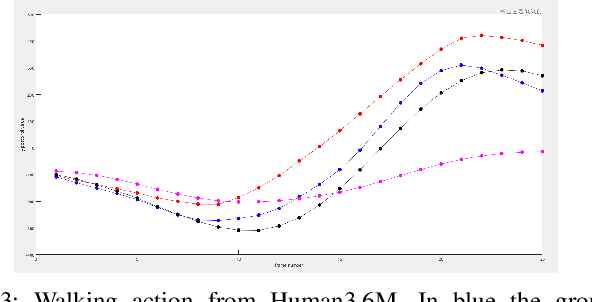
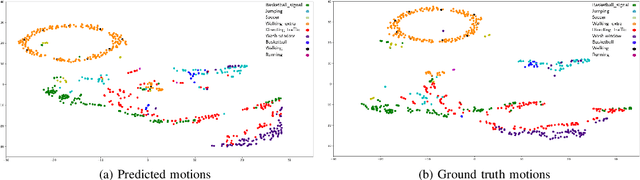
Human motion prediction aims to forecast future human poses given a prior pose sequence. The discontinuity of the predicted motion and the performance deterioration in long-term horizons are still the main challenges encountered in current literature. In this work, we tackle these issues by using a compact manifold-valued representation of human motion. Specifically, we model the temporal evolution of the 3D human poses as trajectory, what allows us to map human motions to single points on a sphere manifold. To learn these non-Euclidean representations, we build a manifold-aware Wasserstein generative adversarial model that captures the temporal and spatial dependencies of human motion through different losses. Extensive experiments show that our approach outperforms the state-of-the-art on CMU MoCap and Human 3.6M datasets. Our qualitative results show the smoothness of the predicted motions.