 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerating Complex 4D Expression Transitions by Learning Face Landmark Trajectories
Jul 29, 2022

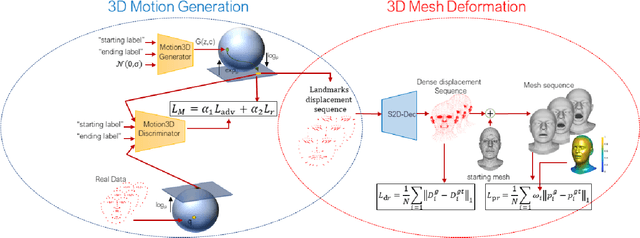

In this work, we address the problem of 4D facial expressions generation. This is usually addressed by animating a neutral 3D face to reach an expression peak, and then get back to the neutral state. In the real world though, people show more complex expressions, and switch from one expression to another. We thus propose a new model that generates transitions between different expressions, and synthesizes long and composed 4D expressions. This involves three sub-problems: (i) modeling the temporal dynamics of expressions, (ii) learning transitions between them, and (iii) deforming a generic mesh. We propose to encode the temporal evolution of expressions using the motion of a set of 3D landmarks, that we learn to generate by training a manifold-valued GAN (Motion3DGAN). To allow the generation of composed expressions, this model accepts two labels encoding the starting and the ending expressions. The final sequence of meshes is generated by a Sparse2Dense mesh Decoder (S2D-Dec) that maps the landmark displacements to a dense, per-vertex displacement of a known mesh topology. By explicitly working with motion trajectories, the model is totally independent from the identity. Extensive experiments on five public datasets show that our proposed approach brings significant improvements with respect to previous solutions, while retaining good generalization to unseen data.
Interaction Transformer for Human Reaction Generation
Jul 04, 2022

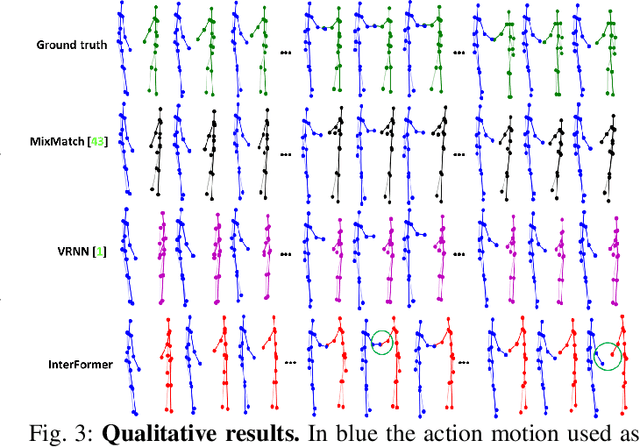

We address the challenging task of human reaction generation which aims to generate a corresponding reaction based on an input action. Most of the existing works do not focus on generating and predicting the reaction and cannot generate the motion when only the action is given as input. To address this limitation, we propose a novel interaction Transformer (InterFormer) consisting of a Transformer network with both temporal and spatial attentions. Specifically, the temporal attention captures the temporal dependencies of the motion of both characters and of their interaction, while the spatial attention learns the dependencies between the different body parts of each character and those which are part of the interaction. Moreover, we propose using graphs to increase the performance of the spatial attention via an interaction distance module that helps focus on nearby joints from both characters. Extensive experiments on the SBU interaction, K3HI, and DuetDance datasets demonstrate the effectiveness of InterFormer. Our method is general and can be used to generate more complex and long-term interactions.
3D Skeleton-based Human Motion Prediction with Manifold-Aware GAN
Mar 01, 2022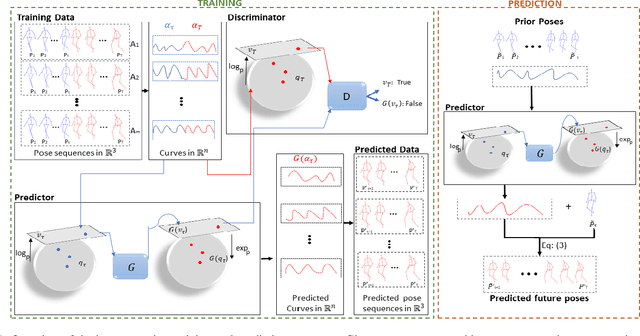


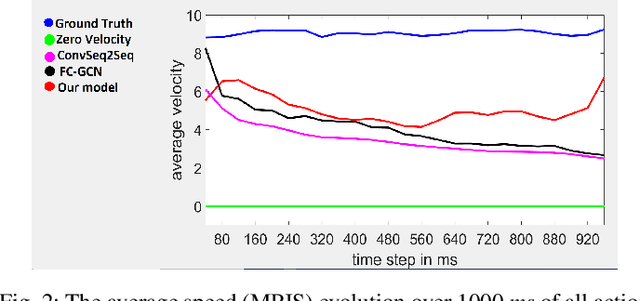
In this work we propose a novel solution for 3D skeleton-based human motion prediction. The objective of this task consists in forecasting future human poses based on a prior skeleton pose sequence. This involves solving two main challenges still present in recent literature; (1) discontinuity of the predicted motion which results in unrealistic motions and (2) performance deterioration in long-term horizons resulting from error accumulation across time. We tackle these issues by using a compact manifold-valued representation of 3D human skeleton motion. Specifically, we model the temporal evolution of the 3D poses as trajectory, what allows us to map human motions to single points on a sphere manifold. Using such a compact representation avoids error accumulation and provides robust representation for long-term prediction while ensuring the smoothness and the coherence of the whole motion. To learn these non-Euclidean representations, we build a manifold-aware Wasserstein generative adversarial model that captures the temporal and spatial dependencies of human motion through different losses. Experiments have been conducted on CMU MoCap and Human 3.6M datasets and demonstrate the superiority of our approach over the state-of-the-art both in short and long term horizons. The smoothness of the generated motion is highlighted in the qualitative results.
Human Motion Prediction Using Manifold-Aware Wasserstein GAN
May 18, 2021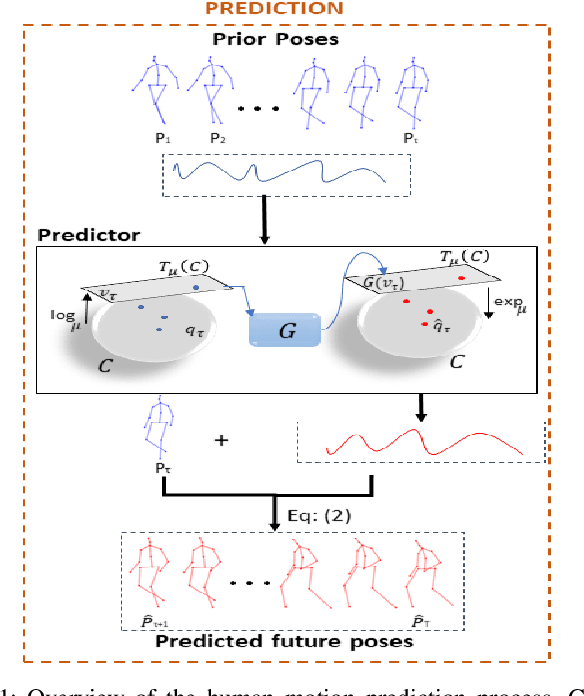
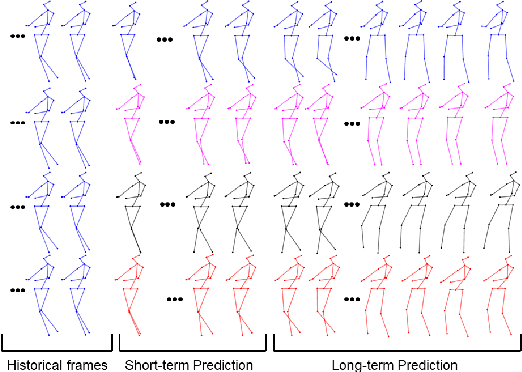
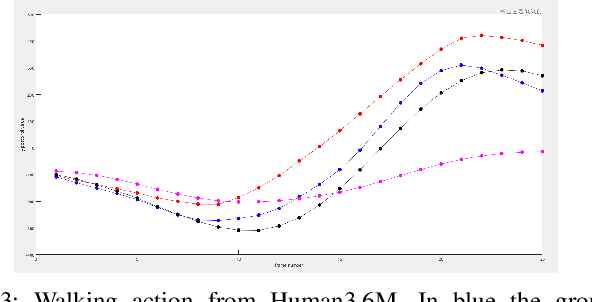
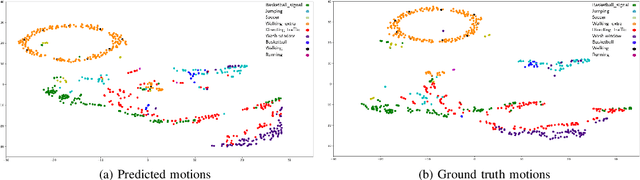
Human motion prediction aims to forecast future human poses given a prior pose sequence. The discontinuity of the predicted motion and the performance deterioration in long-term horizons are still the main challenges encountered in current literature. In this work, we tackle these issues by using a compact manifold-valued representation of human motion. Specifically, we model the temporal evolution of the 3D human poses as trajectory, what allows us to map human motions to single points on a sphere manifold. To learn these non-Euclidean representations, we build a manifold-aware Wasserstein generative adversarial model that captures the temporal and spatial dependencies of human motion through different losses. Extensive experiments show that our approach outperforms the state-of-the-art on CMU MoCap and Human 3.6M datasets. Our qualitative results show the smoothness of the predicted motions.
3D to 4D Facial Expressions Generation Guided by Landmarks
May 16, 2021
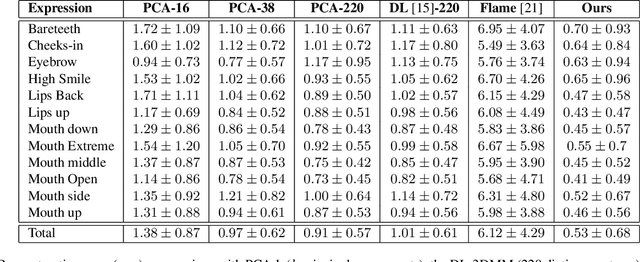
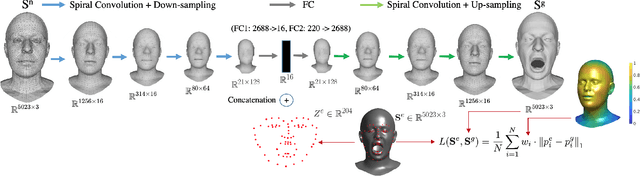

While deep learning-based 3D face generation has made a progress recently, the problem of dynamic 3D (4D) facial expression synthesis is less investigated. In this paper, we propose a novel solution to the following question: given one input 3D neutral face, can we generate dynamic 3D (4D) facial expressions from it? To tackle this problem, we first propose a mesh encoder-decoder architecture (Expr-ED) that exploits a set of 3D landmarks to generate an expressive 3D face from its neutral counterpart. Then, we extend it to 4D by modeling the temporal dynamics of facial expressions using a manifold-valued GAN capable of generating a sequence of 3D landmarks from an expression label (Motion3DGAN). The generated landmarks are fed into the mesh encoder-decoder, ultimately producing a sequence of 3D expressive faces. By decoupling the two steps, we separately address the non-linearity induced by the mesh deformation and motion dynamics. The experimental results on the CoMA dataset show that our mesh encoder-decoder guided by landmarks brings a significant improvement with respect to other landmark-based 3D fitting approaches, and that we can generate high quality dynamic facial expressions. This framework further enables the 3D expression intensity to be continuously adapted from low to high intensity. Finally, we show our framework can be applied to other tasks, such as 2D-3D facial expression transfer.
Dynamic Facial Expression Generation on Hilbert Hypersphere with Conditional Wasserstein Generative Adversarial Nets
Jul 23, 2019

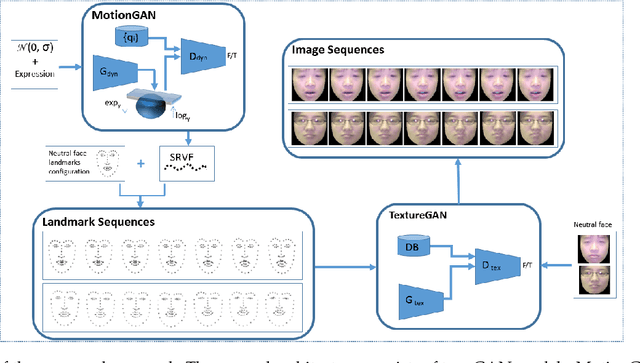
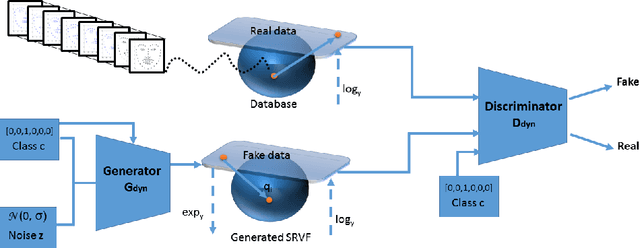
In this work, we propose a novel approach for generating videos of the six basic facial expressions given a neutral face image. We propose to exploit the face geometry by modeling the facial landmarks motion as curves encoded as points on a hypersphere. By proposing a conditional version of manifold-valued Wasserstein generative adversarial network (GAN) for motion generation on the hypersphere, we learn the distribution of facial expression dynamics of different classes, from which we synthesize new facial expression motions. The resulting motions can be transformed to sequences of landmarks and then to images sequences by editing the texture information using another conditional Generative Adversarial Network. To the best of our knowledge, this is the first work that explores manifold-valued representations with GAN to address the problem of dynamic facial expression generation. We evaluate our proposed approach both quantitatively and qualitatively on two public datasets; Oulu-CASIA and MUG Facial Expression. Our experimental results demonstrate the effectiveness of our approach in generating realistic videos with continuous motion, realistic appearance and identity preservation. We also show the efficiency of our framework for dynamic facial expressions generation, dynamic facial expression transfer and data augmentation for training improved emotion recognition models.
Automatic Analysis of Facial Expressions Based on Deep Covariance Trajectories
Oct 25, 2018
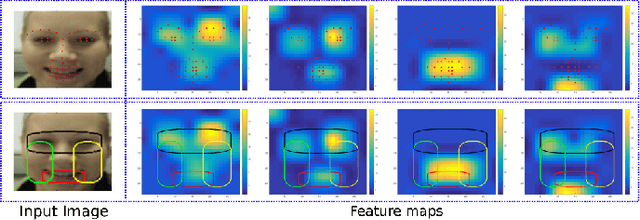
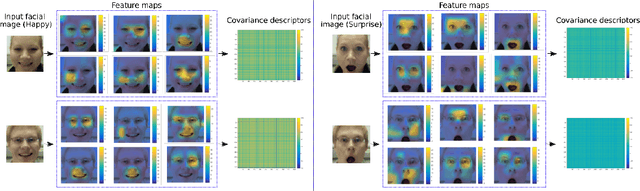

In this paper, we propose a new approach for facial expression recognition. The solution is based on the idea of encoding local and global Deep Convolutional Neural Network (DCNN) features extracted from still images, in compact local and global covariance descriptors. The space geometry of the covariance matrices is that of Symmetric Positive Definite (SPD) matrices. By performing the classification of static facial expressions using a valid Gaussian kernel on the SPD manifold and Support Vector Machine (SVM), we show that the covariance descriptors computed on DCNN features are more effective than the standard classification with fully connected layers and softmax. Besides, we propose a completely new and original solution to model the temporal dynamic of facial expressions as deep trajectories on the SPD manifold. As an extension of the classification pipeline of covariance descriptors, we apply SVM with valid positive definite kernels derived from global alignment for deep covariance trajectories classification. By conducting extensive experiments on the Oulu-CASIA, CK+, and SFEW datasets, we show that both the proposed static and dynamic approaches achieve state-of-the-art performance for facial expression recognition outperforming most recent approaches.
Deep Covariance Descriptors for Facial Expression Recognition
May 10, 2018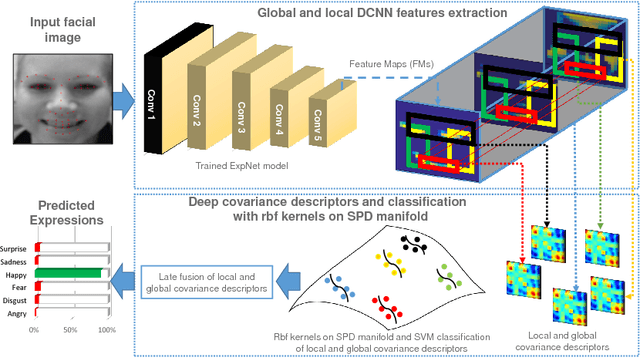



In this paper, covariance matrices are exploited to encode the deep convolutional neural networks (DCNN) features for facial expression recognition. The space geometry of the covariance matrices is that of Symmetric Positive Definite (SPD) matrices. By performing the classification of the facial expressions using Gaussian kernel on SPD manifold, we show that the covariance descriptors computed on DCNN features are more efficient than the standard classification with fully connected layers and softmax. By implementing our approach using the VGG-face and ExpNet architectures with extensive experiments on the Oulu-CASIA and SFEW datasets, we show that the proposed approach achieves performance at the state of the art for facial expression recognition.