 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInteraction Transformer for Human Reaction Generation
Paper and Code


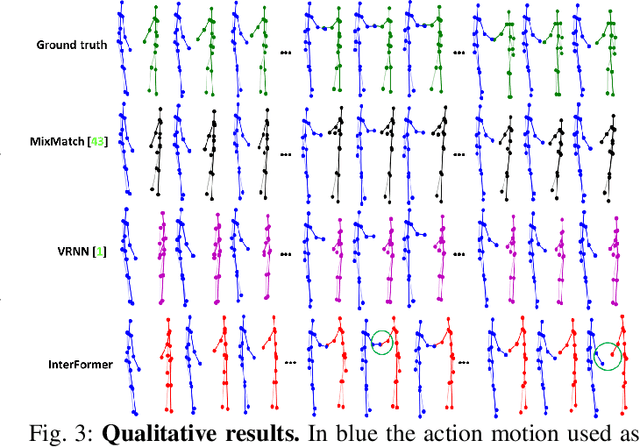

We address the challenging task of human reaction generation which aims to generate a corresponding reaction based on an input action. Most of the existing works do not focus on generating and predicting the reaction and cannot generate the motion when only the action is given as input. To address this limitation, we propose a novel interaction Transformer (InterFormer) consisting of a Transformer network with both temporal and spatial attentions. Specifically, the temporal attention captures the temporal dependencies of the motion of both characters and of their interaction, while the spatial attention learns the dependencies between the different body parts of each character and those which are part of the interaction. Moreover, we propose using graphs to increase the performance of the spatial attention via an interaction distance module that helps focus on nearby joints from both characters. Extensive experiments on the SBU interaction, K3HI, and DuetDance datasets demonstrate the effectiveness of InterFormer. Our method is general and can be used to generate more complex and long-term interactions.