 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTimeSeriesExamAgent: Creating Time Series Reasoning Benchmarks at Scale
Apr 11, 2026Large Language Models (LLMs) have shown promising performance in time series modeling tasks, but do they truly understand time series data? While multiple benchmarks have been proposed to answer this fundamental question, most are manually curated and focus on narrow domains or specific skill sets. To address this limitation, we propose scalable methods for creating comprehensive time series reasoning benchmarks that combine the flexibility of templates with the creativity of LLM agents. We first develop TimeSeriesExam, a multiple-choice benchmark using synthetic time series to evaluate LLMs across five core reasoning categories: pattern recognitionnoise understandingsimilarity analysisanomaly detection, and causality. Then, with TimeSeriesExamAgent, we scale our approach by automatically generating benchmarks from real-world datasets spanning healthcare, finance and weather domains. Through multi-dimensional quality evaluation, we demonstrate that our automatically generated benchmarks achieve diversity comparable to manually curated alternatives. However, our experiments reveal that LLM performance remains limited in both abstract time series reasoning and domain-specific applications, highlighting ongoing challenges in enabling effective time series understanding in these models. TimeSeriesExamAgent is available at https://github.com/magwiazda/TimeSeriesExamAgent.
Feynman: Knowledge-Infused Diagramming Agent for Scalable Visual Designs
Mar 13, 2026Visual design is an essential application of state-of-the-art multi-modal AI systems. Improving these systems requires high-quality vision-language data at scale. Despite the abundance of internet image and text data, knowledge-rich and well-aligned image-text pairs are rare. In this paper, we present a scalable diagram generation pipeline built with our agent, Feynman. To create diagrams, Feynman first enumerates domain-specific knowledge components (''ideas'') and performs code planning based on the ideas. Given the plan, Feynman translates ideas into simple declarative programs and iterates to receives feedback and visually refine diagrams. Finally, the declarative programs are rendered by the Penrose diagramming system. The optimization-based rendering of Penrose preserves the visual semantics while injecting fresh randomness into the layout, thereby producing diagrams with visual consistency and diversity. As a result, Feynman can author diagrams along with grounded captions with very little cost and time. Using Feynman, we synthesized a dataset with more than 100k well-aligned diagram-caption pairs. We also curate a visual-language benchmark, Diagramma, from freshly generated data. Diagramma can be used for evaluating the visual reasoning capabilities of vision-language models. We plan to release the dataset, benchmark, and the full agent pipeline as an open-source project.
TimeSeriesGym: A Scalable Benchmark for (Time Series) Machine Learning Engineering Agents
May 19, 2025We introduce TimeSeriesGym, a scalable benchmarking framework for evaluating Artificial Intelligence (AI) agents on time series machine learning engineering challenges. Existing benchmarks lack scalability, focus narrowly on model building in well-defined settings, and evaluate only a limited set of research artifacts (e.g., CSV submission files). To make AI agent benchmarking more relevant to the practice of machine learning engineering, our framework scales along two critical dimensions. First, recognizing that effective ML engineering requires a range of diverse skills, TimeSeriesGym incorporates challenges from diverse sources spanning multiple domains and tasks. We design challenges to evaluate both isolated capabilities (including data handling, understanding research repositories, and code translation) and their combinations, and rather than addressing each challenge independently, we develop tools that support designing multiple challenges at scale. Second, we implement evaluation mechanisms for multiple research artifacts, including submission files, code, and models, using both precise numeric measures and more flexible LLM-based evaluation approaches. This dual strategy balances objective assessment with contextual judgment. Although our initial focus is on time series applications, our framework can be readily extended to other data modalities, broadly enhancing the comprehensiveness and practical utility of agentic AI evaluation. We open-source our benchmarking framework to facilitate future research on the ML engineering capabilities of AI agents.
TimeSeriesExam: A time series understanding exam
Oct 18, 2024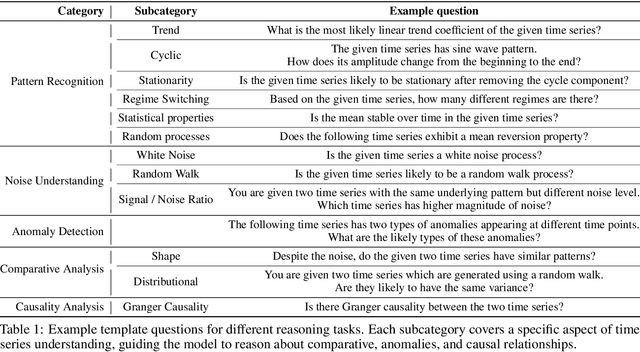
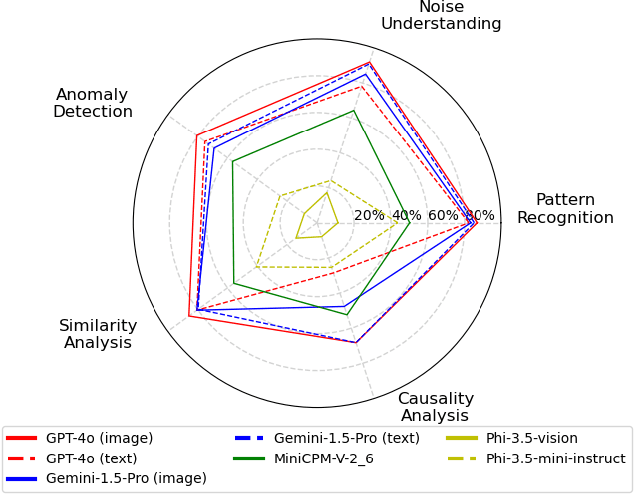
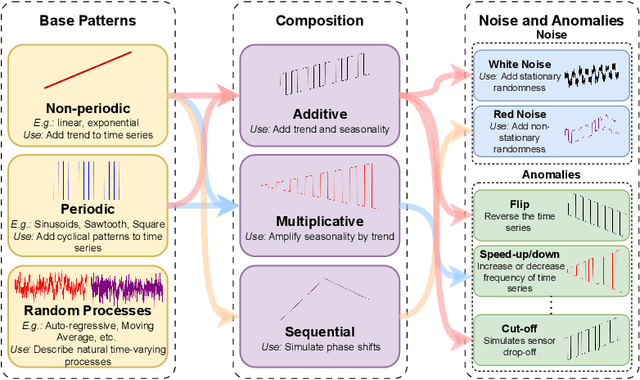
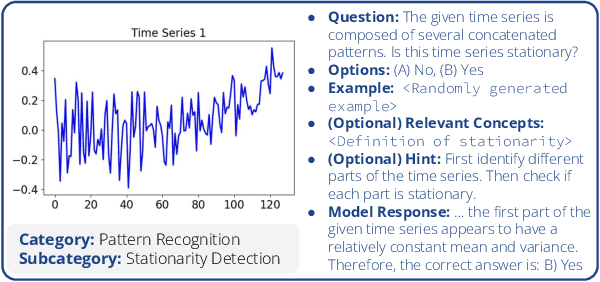
Large Language Models (LLMs) have recently demonstrated a remarkable ability to model time series data. These capabilities can be partly explained if LLMs understand basic time series concepts. However, our knowledge of what these models understand about time series data remains relatively limited. To address this gap, we introduce TimeSeriesExam, a configurable and scalable multiple-choice question exam designed to assess LLMs across five core time series understanding categories: pattern recognition, noise understanding, similarity analysis, anomaly detection, and causality analysis. TimeSeriesExam comprises of over 700 questions, procedurally generated using 104 carefully curated templates and iteratively refined to balance difficulty and their ability to discriminate good from bad models. We test 7 state-of-the-art LLMs on the TimeSeriesExam and provide the first comprehensive evaluation of their time series understanding abilities. Our results suggest that closed-source models such as GPT-4 and Gemini understand simple time series concepts significantly better than their open-source counterparts, while all models struggle with complex concepts such as causality analysis. We believe that the ability to programatically generate questions is fundamental to assessing and improving LLM's ability to understand and reason about time series data.
MOMENT: A Family of Open Time-series Foundation Models
Feb 06, 2024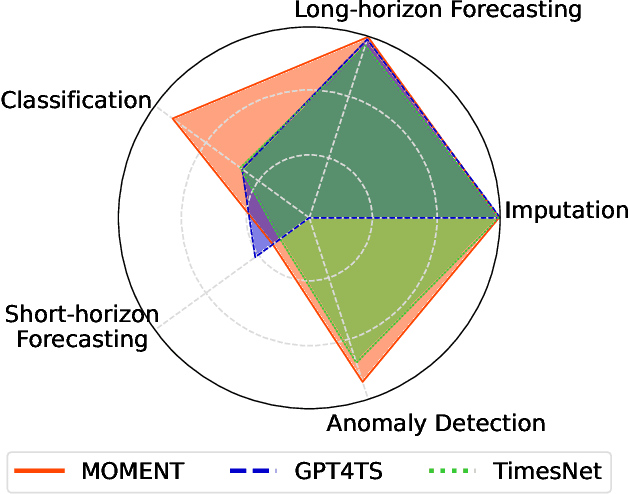
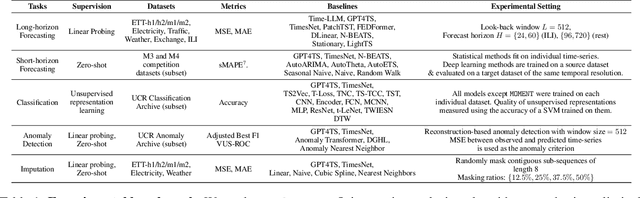
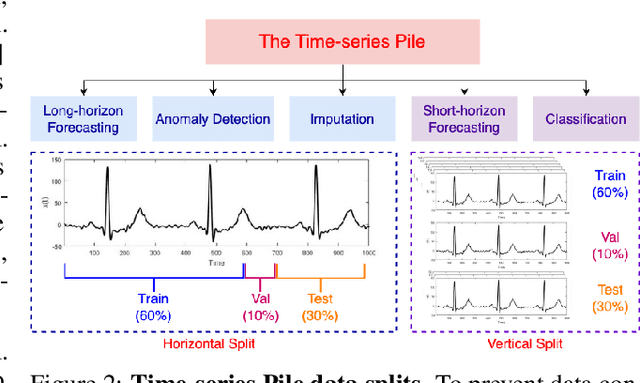
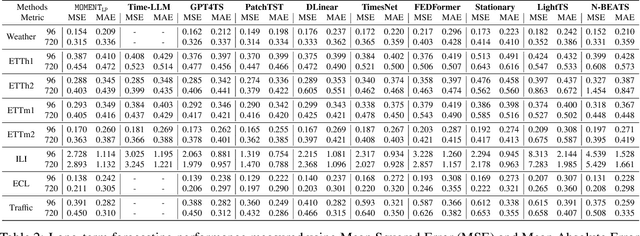
We introduce MOMENT, a family of open-source foundation models for general-purpose time-series analysis. Pre-training large models on time-series data is challenging due to (1) the absence of a large and cohesive public time-series repository, and (2) diverse time-series characteristics which make multi-dataset training onerous. Additionally, (3) experimental benchmarks to evaluate these models, especially in scenarios with limited resources, time, and supervision, are still in their nascent stages. To address these challenges, we compile a large and diverse collection of public time-series, called the Time-series Pile, and systematically tackle time-series-specific challenges to unlock large-scale multi-dataset pre-training. Finally, we build on recent work to design a benchmark to evaluate time-series foundation models on diverse tasks and datasets in limited supervision settings. Experiments on this benchmark demonstrate the effectiveness of our pre-trained models with minimal data and task-specific fine-tuning. Finally, we present several interesting empirical observations about large pre-trained time-series models. Our code is available anonymously at anonymous.4open.science/r/BETT-773F/.