 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTAMP: Spatial-Temporal Adapter with Multi-Head Pooling
Nov 13, 2025Time series foundation models (TSFMs) pretrained on data from multiple domains have shown strong performance on diverse modeling tasks. Various efforts have been made to develop foundation models specific to electroencephalography (EEG) data, which records brain electrical activity as time series. However, no comparative analysis of EEG-specific foundation models (EEGFMs) versus general TSFMs has been performed on EEG-specific tasks. We introduce a novel Spatial-Temporal Adapter with Multi-Head Pooling (STAMP), which leverages univariate embeddings produced by a general TSFM, implicitly models spatial-temporal characteristics of EEG data, and achieves performance comparable to state-of-the-art EEGFMs. A comprehensive analysis is performed on 8 benchmark datasets of clinical tasks using EEG for classification, along with ablation studies. Our proposed adapter is lightweight in trainable parameters and flexible in the inputs it can accommodate, supporting easy modeling of EEG data using TSFMs.
Multimodal Structure Preservation Learning
Oct 29, 2024



When selecting data to build machine learning models in practical applications, factors such as availability, acquisition cost, and discriminatory power are crucial considerations. Different data modalities often capture unique aspects of the underlying phenomenon, making their utilities complementary. On the other hand, some sources of data host structural information that is key to their value. Hence, the utility of one data type can sometimes be enhanced by matching the structure of another. We propose Multimodal Structure Preservation Learning (MSPL) as a novel method of learning data representations that leverages the clustering structure provided by one data modality to enhance the utility of data from another modality. We demonstrate the effectiveness of MSPL in uncovering latent structures in synthetic time series data and recovering clusters from whole genome sequencing and antimicrobial resistance data using mass spectrometry data in support of epidemiology applications. The results show that MSPL can imbue the learned features with external structures and help reap the beneficial synergies occurring across disparate data modalities.
Classifying Unstructured Clinical Notes via Automatic Weak Supervision
Jun 24, 2022

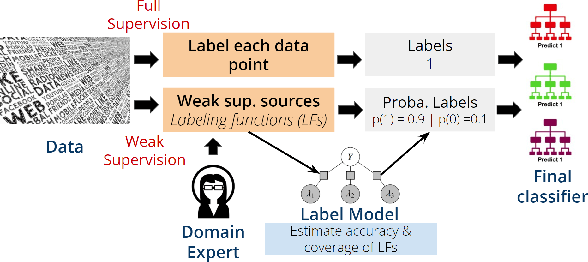

Healthcare providers usually record detailed notes of the clinical care delivered to each patient for clinical, research, and billing purposes. Due to the unstructured nature of these narratives, providers employ dedicated staff to assign diagnostic codes to patients' diagnoses using the International Classification of Diseases (ICD) coding system. This manual process is not only time-consuming but also costly and error-prone. Prior work demonstrated potential utility of Machine Learning (ML) methodology in automating this process, but it has relied on large quantities of manually labeled data to train the models. Additionally, diagnostic coding systems evolve with time, which makes traditional supervised learning strategies unable to generalize beyond local applications. In this work, we introduce a general weakly-supervised text classification framework that learns from class-label descriptions only, without the need to use any human-labeled documents. It leverages the linguistic domain knowledge stored within pre-trained language models and the data programming framework to assign code labels to individual texts. We demonstrate the efficacy and flexibility of our method by comparing it to state-of-the-art weak text classifiers across four real-world text classification datasets, in addition to assigning ICD codes to medical notes in the publicly available MIMIC-III database.
Novel Prediction Techniques Based on Clusterwise Linear Regression
Apr 28, 2018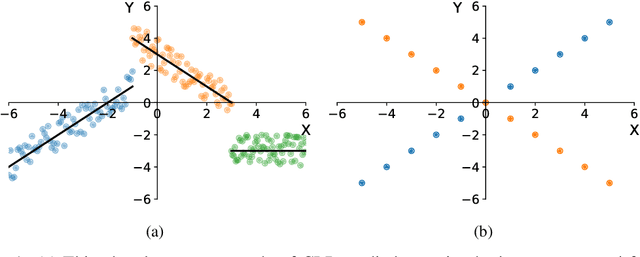
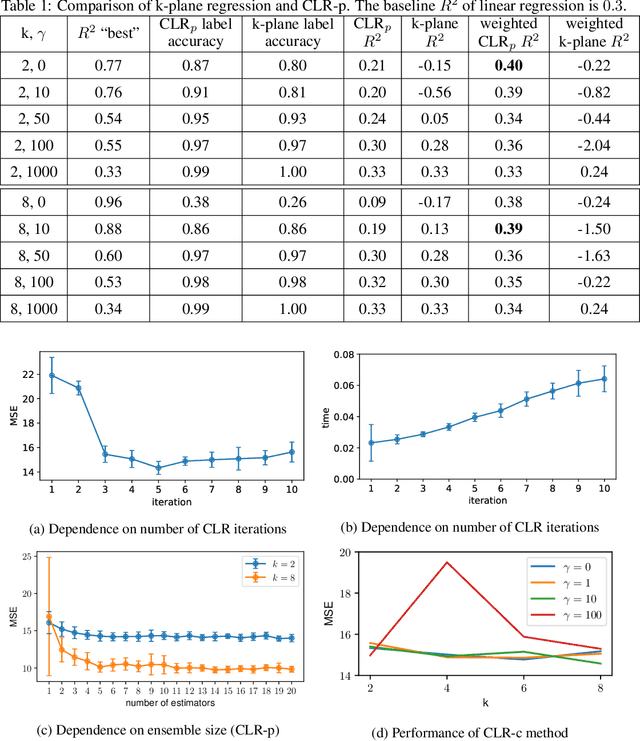
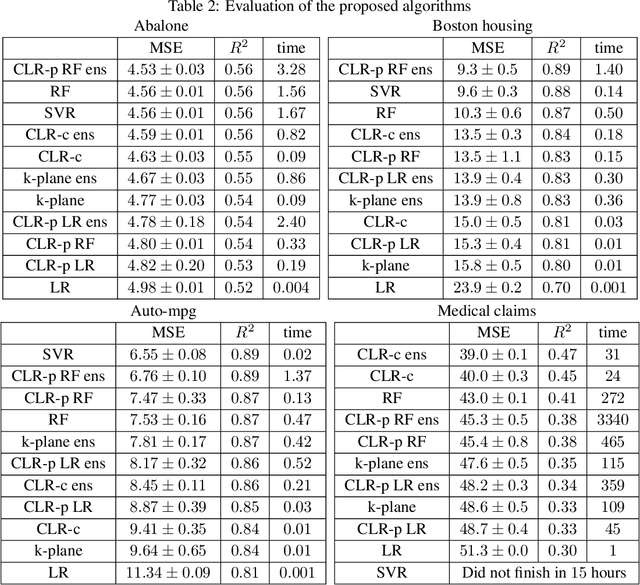
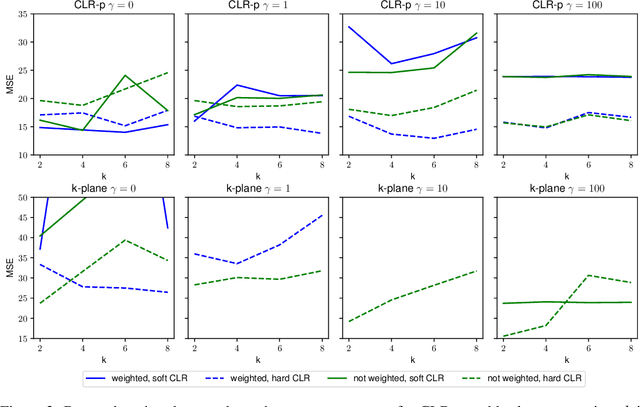
In this paper we explore different regression models based on Clusterwise Linear Regression (CLR). CLR aims to find the partition of the data into $k$ clusters, such that linear regressions fitted to each of the clusters minimize overall mean squared error on the whole data. The main obstacle preventing to use found regression models for prediction on the unseen test points is the absence of a reasonable way to obtain CLR cluster labels when the values of target variable are unknown. In this paper we propose two novel approaches on how to solve this problem. The first approach, predictive CLR builds a separate classification model to predict test CLR labels. The second approach, constrained CLR utilizes a set of user-specified constraints that enforce certain points to go to the same clusters. Assuming the constraint values are known for the test points, they can be directly used to assign CLR labels. We evaluate these two approaches on three UCI ML datasets as well as on a large corpus of health insurance claims. We show that both of the proposed algorithms significantly improve over the known CLR-based regression methods. Moreover, predictive CLR consistently outperforms linear regression and random forest, and shows comparable performance to support vector regression on UCI ML datasets. The constrained CLR approach achieves the best performance on the health insurance dataset, while enjoying only $\approx 20$ times increased computational time over linear regression.
Implementation of a FPGA-Based Feature Detection and Networking System for Real-time Traffic Monitoring
Mar 22, 2016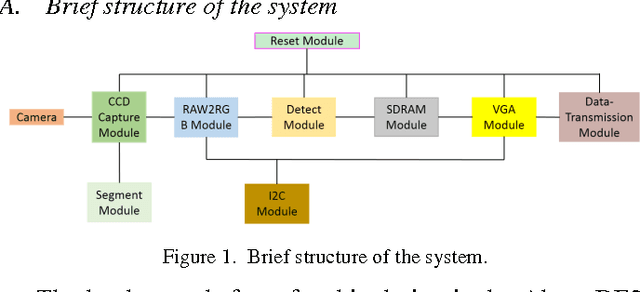
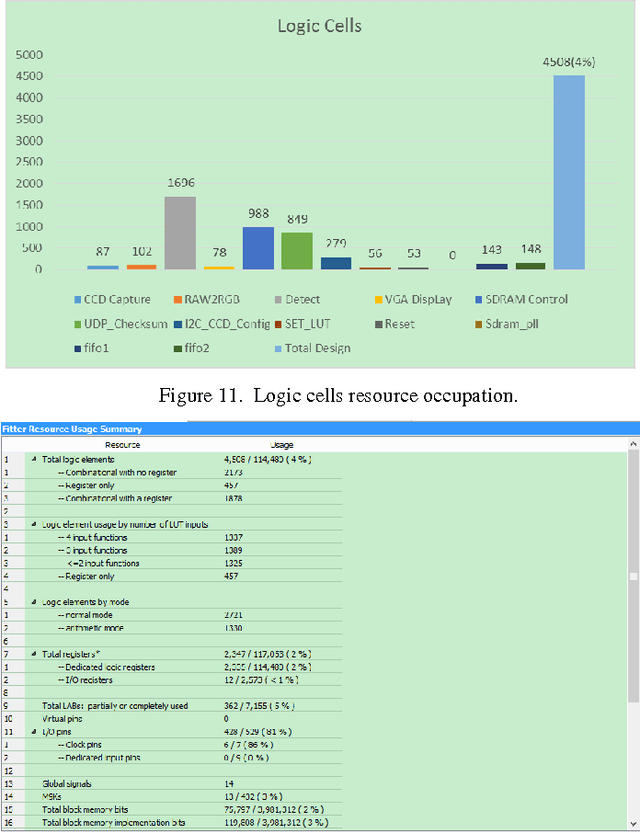
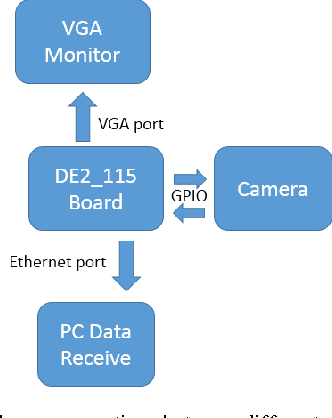
With the growing demand of real-time traffic monitoring nowadays, software-based image processing can hardly meet the real-time data processing requirement due to the serial data processing nature. In this paper, the implementation of a hardware-based feature detection and networking system prototype for real-time traffic monitoring as well as data transmission is presented. The hardware architecture of the proposed system is mainly composed of three parts: data collection, feature detection, and data transmission. Overall, the presented prototype can tolerate a high data rate of about 60 frames per second. By integrating the feature detection and data transmission functions, the presented system can be further developed for various VANET application scenarios to improve road safety and traffic efficiency. For example, detection of vehicles that violate traffic rules, parking enforcement, etc.